一种解决物理约束的深度强化学习训练及决策方法
本发明涉及一种解决物理约束的深度强化学习训练及决策方法,属于人工智能。
背景技术:
1、强化学习(reinforcement learning)是一种解决序列决策问题的人工智能方法。近年来,其被广泛应用于机器人控制,游戏竞技,自动驾驶等领域。通常,序列决策问题会被建模成马尔科夫决策过程(markov decision processes),也就是一个五元组<s,,,,>,其中,s代表状态空间,a代表动作空间,r代表奖励函数,p代表概率转移函数,γ代表折扣因子。传统强化学习的优化目标最大化累积折扣奖励的期望,即但是,经典的马尔科夫决策过程没有考虑现实决策问题中存在的固有约束,这也导致了传统强化学习很难被应用于一些具有物理约束的现实问题中。
2、在这样的背景下,相关专家学者又提出了基于约束马尔科夫决策过程(constrained markov decision processes)建模的安全强化学习技术(safereinforcement learning)。约束马尔科夫决策过程在马尔科夫决策过程的基础上引入了代价函数c。安全强化学习的目标是在最大化奖励目标的同时,满足累积折扣代价的期望的约束,即其中,di代表第i个约束。但是,安全强化学习技术大多仅考虑了隐式的不等式约束,并且往往只能处理一些约束数量少,约束实际形式较为简单的场景;而现实应用中存在着许多复杂物理约束,除了不等式约束外,其中也包含了等式约束。这就使得经典的安全强化学习技术难以解决此类问题。
3、另一方面,现有的解决物理约束的机器学习方法,尤其是强化学习领域,大多都局限于某一具体应用,或者仅能解决特殊形式的约束。此外,目前对于带有物理约束的序列决策问题,尚未出现统一的建模方式,这也导致了该领域缺乏系统性的研究和方法。
技术实现思路
1、本发明要解决的技术问题是:现有的强化学习技术没有办法很好地满足在现实应用(例如电网操作任务)中的物理硬约束。
2、为了更好地定义和规范具有物理约束的决策问题,本发明首先提出了物理约束马尔可夫决策过程(physics-constrained markov decision processes),在原来马尔可夫决策过程的基础上引入了两个元素,分别是满足等式约束策略集和满足不等式约束的策略集我们的目标是在等式约束策略集和不等式约束策略集中找出最优策略,也就是
3、本发明所公开的具体技术方案是提供了一种解决物理约束的深度强化学习决策方法,其特征在于,包括以下步骤:
4、步骤1、在强化学习的策略网络输出后添加一个可微的物理感知层,用于对策略网络输出的不满足物理约束的动作进行处理,使其满足物理硬约束,其中,物理感知层包括用于解决等式约束的满足性的等式构造层和用于解决不等式约束的满足性的不等式投影层;
5、本发明提出了物理感知强化学习方法。物理感知强化学习方法在强化学习原有的策略网络输出后添加了一个可微的物理感知层。物理感知层有一个缺点:当策略网络输出的初始动作离不等式约束所规定的的可行域较远时,其运行时间会大大提高,因此,本发明提出的物理感知强化学习方法还包括了单调原始对偶策略更新算法,使得策略网络输出的初始动作,就已经较为接近不等式约束所规定的可行域,减少了物理感知层的运行时间。
6、步骤2、给定当前状态s,使用策略网络决策出初始部分动作ap;
7、步骤3、将部分动作ap输入等式构造层,等式构造层通过求解当前状态s下等式约束所定义的方程组,求解出剩余动作ar,最终得到完整动作
8、步骤4、将完整动作输入不等式投影层,不等式投影层以当前状态s下不等式约束对应的精确惩罚函数为优化目标,对完整动作进行多次投影更新,直至其满足所有不等式约束,输出最终可行动作a;
9、步骤5、强化学习智能体执行最终可行动作a。
10、优选地,步骤2中,假设当前实际问题具有m个等式约束,则从原始的动作空间rn中选择n-m个动作作为策略网络实际要决策的动作维数,将其称为部分动作ap。
11、优选地,步骤3中,在等式构造层中,当部分动作ap确定之后,根据m个等式约束对于剩下的m个要决策的动作ar构建出一个具有m个方程的m元方程组;然后,通过求解m元方程组,将剩下的m维动作给解出来。
12、优选地,步骤3中,在等式构造层中,求解m元方程组时等式构造层利用了隐函数定理来获得剩余动作ar对于ap的雅克比矩阵,不管从部分动作ap到剩余动作ar的计算过程是否可微,策略网络都能够得到从损失函数反向传播回来的完整梯度。
13、优选地,步骤3中,剩余动作ar对于部分动作ap的雅克比矩阵为:
14、
15、其中,剩余动作ar=r(p),φr代表着从部分动作ap到剩余动作ar的计算过程;为状态s上的等式约束对于完整动作的雅克比矩阵,表示矩阵jf的第一列到第m列,表示矩阵jf的第m+1列到第n列。
16、本发明中解方程的方法可以是任意的现有方法,比如牛顿法;或者如果该方程具有某种特定的形式,比如都是线性等式,也可以直接得到关于剩余动作ar的解析解。然而,如果直接使用类似牛顿法之类的数值方法去求解,剩余动作ar对于部分动作ap的雅克比矩阵将无法获得。这就会导致策略网络无法获得完整的梯度流进行训练。因此,等式构造层利用了隐函数定理来获得剩余动作ar对于ap的雅克比矩阵。
17、优选地,步骤4中,不等式投影层将当前不满足的约束作为优化目标,在等式约束所定义的低维流形上进行优化,直至所有不等式约束满足,其中,不等式投影层的优化过程写成:
18、
19、
20、
21、
22、其中:是不等式投影层所采用的精确惩罚函数,表示状态s下关于动作a的第j个不等式约束;a(k)表示经过k次投影更新后的动作,其中,ap()表示k次投影更新后的部分动作,ar()表示k次投影更新后的剩余动作;是每次投影更新的步长。需要注意的是,由于不等式投影层所输出的最终动作a也需要满足等式约束的成立,投影更新必须要在等式约束所定义的低维流形上进行。而对于非线性等式约束,雅克比矩阵不固定。因此,对于具有非线性等式约束的场景,需要设置的很小,以阻止更新后的动作偏离等式约束所定义的低维流形过多。
23、本发明的另一个技术方案是提供了一种上述的解决物理约束的深度强化学习决策方法在电网操作中的应用,其特征在于,包括以下步骤:
24、步骤1、给定当前电网状态s,该当前电网状态s包括电网中各节点的有功功率需求和无功功率需求以及当前的日前电价,使用策略网络决策出初始部分动作ap,该初始部分动作ap包括发电节点的有功发电功率和电压幅值以及蓄电池的有功放电/充电功率;
25、步骤2、将初始部分动作ap输入等式构造层,等式构造层通过求解当前状态s下等式约束所定义的方程组求解出剩余动作ar,该剩余动作ar包括电网发电节点的无功发电功率和电网各节点的电压幅值和幅角,最终得到完整动作其中,电网各节点的电压幅值不包括发电节点的电压幅值;
26、步骤3、将完整动作输入不等式投影层,不等式投影层以当前状态s下不等式约束对应的精确惩罚函数为优化目标,对完整动作进行多次投影更新,直至其满足所有不等式约束,输出最终可行动作a;
27、步骤4、强化学习智能体执行最终可行动作a至电网控制中心。
28、本发明的另一个技术方案是提供了一种解决物理约束的深度强化学习训练方法,其特征在于,包括以下步骤:
29、步骤1、强化学习智能体使用上述的决策方法与环境/仿真器交互,收集数据并存入经验回放池中;
30、步骤2、从经验回放池中随机采样数据;
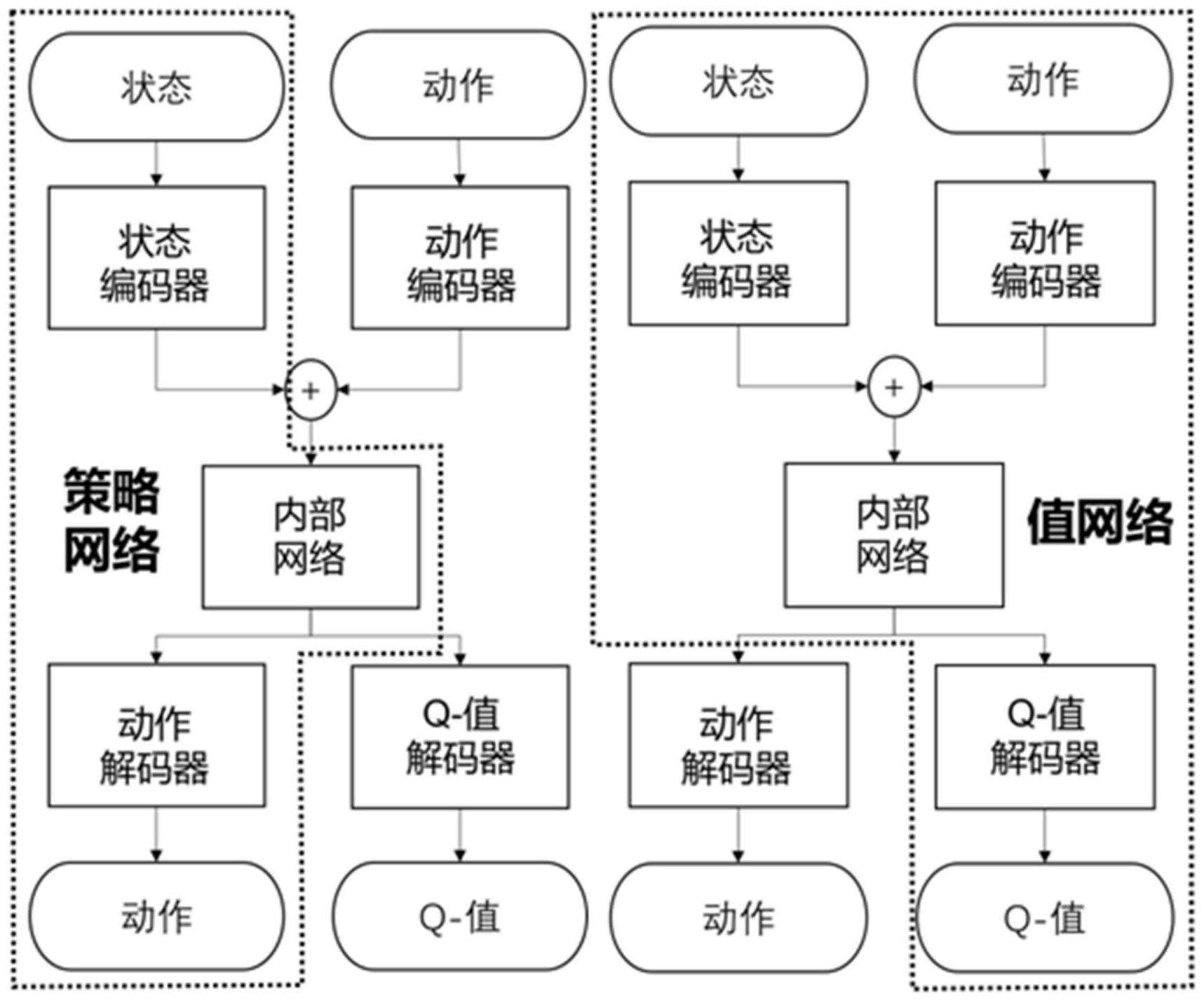
31、步骤3、使用采样数据,以无约束优化问题为目标,对策略网络进行更新,其中,在马尔可夫决策过程的基础上引入了满足等式约束策略集和满足不等式约束的策略集目标是在等式约束策略集和不等式约束策略集中找出最优策略,也就是其中,π表示策略,i表示第i个约束,j表示第j个约束,s表示状态,π(s)表示状态s下策略π所输出的动作,fi(π(s)|s)表示在状态s和策略π下第i个等式约束的值,gj(π(s)|s)表示在状态s和策略π下第j个不等式约束的值,jr(π)表示策略π所对应的累积折扣奖励的期望;
32、步骤4、使用采样数据,构建目标q值,以mse损失为目标,对值网络进行更新;
33、步骤5、使用采样数据,根据单调原始对偶更新,对惩罚因子进行更新;
34、步骤6、以软更新方式更新策略网络和值网络所对应的目标网络。
35、优选地,所述步骤5,在单调原始对偶更新中,为了使得强化学习中策略网络所输出的初始部分动作,能够更接近不等式所规定的可行域,将原始的有约束决策问题,转化成了等价的无约束问题,如下式所述:
36、
37、具体地,通过拉格朗日松弛的方法,使用精确惩罚函数在目标函数中构造惩罚项,则转化成的无约束优化问题表示为:
38、
39、其中,是对于第j个不等式约束的惩罚因子,当时,该无约束优化问题和原始的有约束优化问题等价,因此,在单调原始对偶更新中,对惩罚因子进行单调增长的更新,使其最终总会满足上述不等式,具体更新公式如下:
40、
41、式中,表示第k次更新后的对应于第j个不等式约束的惩罚因子,ηj表示第j个惩罚因子的更新步长,gj(s,a)的含义同g(a|s)。
42、本发明的另一个技术方案是提供了一种上述的解决物理约束的深度强化学习训练方法在电网操作中的应用,其特征在于,包括以下步骤:
43、步骤1、强化学习智能体使用上所述的决策方法与电网真实环境或者电网仿真程序交互,收集数据并存入经验回放池中;
44、步骤2、从经验回放池中随机采样数据;
45、步骤3、使用采样数据,以无约束优化问题为目标,对策略网络进行更新;以带有蓄电池组的电网操作应用为例,目标是最小化发电机自身发电成本并最大化蓄电池在时间维度上进行削峰填谷的收益,同时还要考虑到潮流平衡方程的物理等式约束,以及操作可行范围的物理不等式约束。
46、步骤4、使用采样数据,构建目标q值,以mse损失为目标,对值网络进行更新;
47、步骤5、使用采样数据,根据单调原始对偶更新,对惩罚因子进行更新;
48、步骤6、以软更新方式更新策略网络和值网络所对应的目标网络。
49、本发明公开了一种通用的能够处理物理约束的强化学习方法,确保了在强化学习进行决策的过程中硬约束的满足,其与现有技术相比具有以下几个明显优势:
50、(1)本发明提出的是一种通用的解决物理约束的强化学习方法,可以解决任意形式的具有任意多个可微约束的决策问题,而不限于某一具有某种特定形式约束(例如线性约束)的决策问题。
51、(2)本发明所提出的物理感知层是全可微的。因此,策略网络可以得到完整的梯度信息,因此其训练过程是端到端的,便于实现和操作。其训练更新的过程也更加准确。
52、(3)本发明致力于解决决策问题中的物理硬约束,其包含了等式和不等式约束,确保了决策的可行性。这对强化学习技术在实际应用中的落地意义重大。
- 还没有人留言评论。精彩留言会获得点赞!