水稻识别模型的构建方法及其水稻识别和制图方法与流程
本发明属于农业遥感,具体涉及一种水稻识别模型的构建方法及其水稻识别和制图方法。
背景技术:
1、水稻制图技术一直是农业遥感领域的热门问题。由于能够稳定、快速地获取目标区域的影像,帮助从业人员和有关部门掌握地表情况,遥感技术被广泛应用于水稻制图工作。水稻作为一种在我国大量种植的农作物,在不同的生长期表现出不同的特征,利用多时序遥感影像进行水稻制图是当前的主流方法。
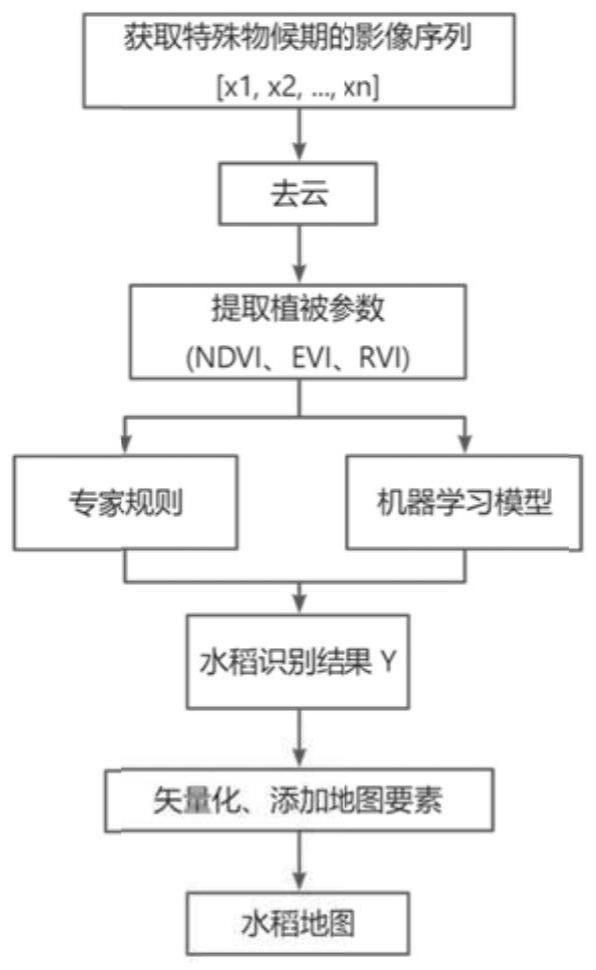
2、当前,水稻制图的基本流程如下:首先,根据水稻的生长周期获取在此区间内的遥感影像,组成遥感影像序列;其次,对遥感影像进行去云操作,去除被云层覆盖的像素,防止水稻的光谱特征被云层污染;然后,对遥感影像序列提取特征,如归一化植被指数(ndvi,normalized vegetation index)、比值植被指数(rvi,ratio vegetation index)、差值植被指数(dvi,difference vegetation index)、调整土壤亮度植被指数(savi,soil-adjusted vegetation index);接着,通过专家制定的规则进行阈值分割,确定水稻的区域和其他的土地区域,或者使用自动学习模型,如支持向量机(svm,support vectormachine)、随机森林(rf,random forest)等学习水稻的特征,经过一定样本的学习后,对水稻进行识别;最后,对水稻识别结果进行矢量化,添加比例尺、经纬网等地图元素,得到水稻地图。
3、但是现有技术存在下列不足:(1)在水稻的识别方法上,现有技术利用专家规则和机器学习模型进行识别;专家规则系统的灵活性不足,在气候条件、种植物候信息与这些区域不一致的地区,水稻的识别效果会急剧下降;而机器学习模型由于模型的学习能力并没有完全强于人工规则,在一些特定的区域,利用机器学习方法得到的水稻地图产品精度会比专家规则系统要低;此外,专家规则系统和机器学习模型这两种识别方法都关注于提取时序特征,没有针对空间特征进行挖掘;(2)去云操作将被云层覆盖的像素值剔除,会导致光谱值序列在某些时间段的数据被丢弃。当丢弃情况不是特别严重时,通过其他时间段的光谱特征,也能识别出水稻,但识别的精度会有所降低。在降雨多、云雾出现概率高的南方区域,时序数据的丢失情况及其严重,无法得到足够精度的水稻地图产品。
技术实现思路
1、本发明的发明目的是提供用于水稻识别的水稻识别模型的构建方法和基于该模型的水稻识别方法及水稻制图方法。
2、该用于水稻识别的水稻识别模型的构建方法和基于该模型的水稻识别方法及水稻制图方法解决了在云雾较多的南方地区,如何构建精准识别水稻的模型,以及如何利用该模型更精准地识别水稻,最终得到质量较高的水稻制图产品;还能充分挖掘水稻识别中水稻的时间和空间特征,提高水稻制图精度。
3、为实现上述发明目的,本发明的技术方案为:
4、一种用于水稻识别的水稻识别模型的构建方法,包括:
5、a.构建包括编码器、时序掩码模块、掩码恢复模块和解码器的预训练模型;
6、b.对预训练模型进行预训练,使编码器学习到基于残缺时间序列提取完整时间序列时空特征的能力;
7、c.构建包括编码器和解码器的水稻识别模型,且该编码器使用所述预训练模型中经训练的编码器;
8、d.固定编码器参数对水稻识别模型进行正式训练,使其解码器学习到基于编码器输出的时空特征识别水稻的能力。
9、本发明设计的模型的构建方法有效增强模型抵抗数据缺失的能力,时序掩码模块是通过随机丢弃时序影像中的部分时间点的影像,然后控制模型学习影像的时空特征,对原始序列影像进行恢复或重建的过程。经过预训练模型强大的学习能力学习影像序列的时空依赖关系,再通过正式训练强化了水稻识别模型对于影像序列时空关系的捕捉能力,使得水稻识别模型对于数据缺失(时序影像序列不完整)的情况有较强的抵抗能力,当原始数据中的影像被云雾遮挡且无法修补的情况下,使得水稻识别模型拥有抵抗云雾带来的数据缺失的能力。
10、在上述的用于水稻识别的水稻识别模型的构建方法中,预训练过程如下:
11、b1.由时序掩码模块对输入的影像序列随机去除部分影像序列,记录掩码位置的索引值;
12、b2.由编码器基于掩码后的影像序列提取时空特征;
13、b3.由掩码恢复模块和解码器基于掩码位置的索引值和编码器输出的时空特征恢复影像序列;
14、b4.使用预训练损失函数比较恢复的影像序列和输入的影像序列,更新模型参数;
15、通过上述预训练过程训练编码器基于残缺时间序列提取完整时间序列时空特征的能力。
16、具体来说,本发明的预训练是一种基于时序掩码的预训练,首先,对于输入的影像序列[z1,z2,..zm],经过一个时序掩码模块,丢弃部分影像,并记录掩码位置的索引值;经过时序掩码后,影像序列的大小由原来的h×w×t变成h×w×t;接着,将掩码过后的“残缺”影像序列输入给预训练模型,预训练模型提取水稻在不同尺度下的时空特征;然后根据掩码的索引值将这些特征恢复到它们在初始影像序列[z1,z2,…zm]中的位置,未恢复的部分(掩码部分)用可学习的参数进行填充,恢复原始影像的时间长度;掩码恢复模块最后将掩码恢复后的影像序列投入解码器进行解码,然后经过聚合得到重建后的影像序列。
17、预训练中的编码器可学习的参数会试图恢复所有特征,包括掩码部分和未掩码部分,对比只能对未残缺部分的参数进行训练的传统训练过程,经过预训练,能够同时对未残缺部分和用于恢复缺失部分的参数进行训练,或者说较好地训练,掩码恢复模块根据掩码索引将这些特征填充至对应的位置。
18、在上述的用于水稻识别的水稻识别模型的构建方法中,所述用于预训练的预训练损失函数为欧式距离,
19、
20、其中zi为输入影像序列,f(xi)为重建影像序列。
21、本发明中,基于时序掩码的预训练使用欧式距离作为损失函数,控制模型进行自动学习。
22、在上述的用于水稻识别的水稻识别模型的构建方法中,所述水稻识别模型正式训练的步骤如下:
23、d1.将影像序列输入编码器提取时空特征;
24、d2.将编码器提取到的时空特征输出给解码器进行解码,
25、d3.解码器输出水稻识别结果;
26、d4.基于正式训练损失函数将水稻识别结果与真值进行比较,更新解码器参数。
27、在水稻识别模型正式训练时,模型的训练结构与预训练模型的训练结构有一定差异,需要去掉时序掩码模块和掩码恢复模块,将输入的影像序列直接作为编码器的输入,编码器不同阶段提取的时空特征也直接输给解码器进行解码,最终模型输出水稻识别结果。
28、在上述的用于水稻识别的水稻识别模型的构建方法中,用于水稻识别模型正式训练的正式训练损失函数为交叉熵函数,
29、
30、其中zi为输入影像序列,f(xi)为重建影像序列,
31、本发明提供的水稻识别方法中,在水稻识别模型正式训练阶段使用交叉熵函数作为损失函数,将水稻识别模型输出的水稻识别结果与地表真值进行比较,对水稻识别模型进行参数的调整。
32、在上述的用于水稻识别的水稻识别模型的构建方法中,所述的编码器包括用于提取不同尺度下时空特征的多个编码模块,每个提取模块均包括3d卷积、参数密集型的多层感知机mlp和多头注意力结构multi-head attention;
33、所述的解码器包括用于对多个尺度下的时空特征进行解码的多个解码模块,以及用于对多个解码的时空特征进行聚合的聚合模块。
34、本发明中,水稻识别模型整体以“u”型编码-解码结构构建,能够得到水稻在不同空间尺度上的时空特征,最大程度地确保水稻田的边缘识别准确性。编码器的组件中,3d卷积能够学习时空关系,优选conv3d;参数密集型的多层感知机mlp和多头注意力结构multi-head attention能灵活挖掘更有效特征,上述组合能够充分挖掘水稻时间以及空间上的两种特征,并加以融合,结合两种特征,能够更加准确地识别地表的水稻。由于水稻识别模型强大的学习和泛化性,能够在地理位置不同的区域进行的水稻识别,可以进行大规模的水稻制图工作。
35、优选地,所述编码器包括五个阶段,每个阶段包含至少一个块,每个块包括一个三维卷积层conv3d、多头注意力层multi-head attention和多层感知机层mlp,不同阶段包含的块的数量分别为[1,2,2,2,2];
36、所述解码器包括五个阶段,分别解码经过编码器得到的水稻时空特征,经过mlp层聚合,得到重建影像序列。
37、其中,阶段2-5中的conv3d层的窗口滑动步距设置为2,用于进行特征图尺寸的缩减,得到多尺度特征。
38、本发明还提供了一种一种基于水稻识别模型的水稻识别方法,
39、所述的水稻识别模型采用上述方法构建,且水稻识别方法包括:
40、s1.影像采集,采集水稻生长全周期的遥感光学影像,组成原始影像时间序列;
41、s2.去云模块,对原始影像时间序列进行去云并进行修补;具体如下,
42、s21.对采集的原始影像时间序列进行去云操作;
43、s22.影像填补,检测影像的缺失情况,若存在像素值缺失,使用临近年份采集时间最近似的影像进行填补;
44、s23.影像合成,对填补后的影像进行合成,将一个时间段内的所有影像进行合成,组成新的影像序列;
45、s3.将步骤s2得到的影像序列输入至经过训练的水稻识别模型得到水稻识别结果。
46、去云操作,是因为部分地物的光谱反射值被云层遮挡而成为噪声,因此需要进行云识别,并去除云含量较高的影像,以及被云层覆盖的像素值,防止噪声对水稻识别精度造成影响。
47、本发明的基于水稻识别模型的水稻识别方法,在云雾较多的南方地区,仍能够得到质量较高的水稻制图产品,同时,充分挖掘水稻的时间和空间特征,提高水稻制图精度。该识别方法在时序数据不完整的情况下,依然能够得到精准的水稻识别结果,在地理位置和气候环境不同的区域,都能够对水稻进行精准的识别,表现出了较强的泛化能力。
48、本发明的去云模块在去云后再进行影像填补和影像合成作为修补操作,在遥感影像序列有云雾遮挡的情况下,可以尽量少地丢失信息,降低云雾遮挡带来的不利影响,并以此去除填补操作可能带来的噪声。经过这样的处理,能够最大程度地在数据层面减少数据丢失现象。
49、优选地,在上述的s23.影像合成,中,以14天为间隔,利用中值合成将每个14天内的影像合成为一张,使不同区域的影像在时间轴上进行对齐。
50、本发明水稻识别方法中影像填补目的是在数据层面减少时间序列的缺失值;而影像合成目的是为了缩减模型计算量,同时使不同区域的影像在时间轴上进行对齐,时间轴的尺度单位由1天变为14天,中值合成使得合成后的影像更有该时间段水稻生长情况的代表性,同时也相当于对不同地区采集时间有些微差别的影像进行了时间尺度上的对齐。
51、更进一步地,所述s1影像采集中,选择采集水稻全生长周期的影像序列。本发明选择水稻生长周期内所有影像序列,用来保证原始数据包含足够多的水稻生长特征。
52、本发明又提供了一种基于水稻识别模型的水稻制图方法,该方法包括:
53、通过上述方法得到水稻识别结果;
54、对水稻识别结果进行矢量化,随后添加包括框图、指北针、图例的地图元素得到水稻地图。
55、与现有技术相比,本发明的有益效果体现在:
56、(1)本发明设计的模型的构建方法有效增强模型抵抗数据缺失的能力,时序掩码模块是通过随机丢弃时序影像中的部分时间点的影像,然后控制模型学习影像的时空特征,对原始序列影像进行恢复或重建的过程。经过预训练模型强大的学习能力学习影像序列的时空依赖关系,再通过正式训练强化了水稻识别模型对于影像序列时空关系的捕捉能力,使得水稻识别模型对于数据缺失(时序影像序列不完整)的情况有较强的抵抗能力,当原始数据中的影像被云雾遮挡且无法修补
57、(2)本发明时序掩码预训练操作的加入,使得模型捕捉时空关系的能力进一步加强,预训练模型的参数,不仅可以用于指导水稻制图,也可以用于指导其他任务,如耕地识别,地表要素分割等等。
58、(3)本发明中,水稻识别模型整体以“u”型编码-解码结构构建,能够得到水稻在不同空间尺度上的时空特征,最大程度地确保水稻田的边缘识别准确性。编码器的组件中,3d卷积能够学习时空关系,优选conv3d;参数密集型的多层感知机mlp和多头注意力结构multi-head attention能灵活挖掘更有效特征,上述组合能够充分挖掘水稻时间以及空间上的两种特征,并加以融合,结合两种特征,能够更加准确地识别地表的水稻。由于水稻识别模型强大的学习和泛化性,能够在地理位置不同的区域进行的水稻识别,可以进行大规模的水稻制图工作。
59、(4)本发明的基于水稻识别模型的水稻识别方法,在云雾较多的南方地区,仍能够得到质量较高的水稻制图产品,同时,充分挖掘水稻的时间和空间特征,提高水稻制图精度。该识别方法在时序数据不完整的情况下,依然能够得到精准的水稻识别结果,在地理位置和气候环境不同的区域,都能够对水稻进行精准的识别,表现出了较强的泛化能力。
60、(4)本发明的去云模块在去云后再进行影像填补和影像合成作为修补操作,在遥感影像序列有云雾遮挡的情况下,可以尽量少地丢失信息,降低云雾遮挡带来的不利影响,并以此去除填补操作可能带来的噪声。经过这样的处理,能够最大程度地在数据层面减少数据丢失现象。
61、(5)本发明水稻识别方法中影像填补目的是在数据层面减少时间序列的缺失值;而影像合成目的是为了缩减模型计算量,同时使不同区域的影像在时间轴上进行对齐,时间轴的尺度单位由1天变为14天,中值合成使得合成后的影像更有该时间段水稻生长情况的代表性,同时也相当于对不同地区采集时间有些微差别的影像进行了时间尺度上的对齐。
62、(6)本发明提供了一种基于水稻识别模型的水稻制图方法,可以利用多时序遥感影像对水稻进行识别,并生成水稻地图产品。与现有技术相比,本发明提供的方案能够大幅度抵抗时序数据缺失的情况,对于南方多降水、多云雾的情况,水稻制图精度有较大提升。
- 还没有人留言评论。精彩留言会获得点赞!