基于多数据集协作学习的视频显著性区域检测方法
本发明涉及图像通信方法,尤其涉及一种基于多数据集协作学习的视频显著性区域检测方法。
背景技术:
1、视频显著性区域检测是视频处理和计算机视觉中的基本任务之一,也是感知视频编码中重要的预处理任务。它旨在模拟人类视觉注意系统,预测人类自由观看视频时对各个视频区域的关注程度,以显著性图的形式表达出来。在感知视频编码中,首先进行视频显著性区域的捕获,然后把比特资源更多的分配给显著性区域,使得显著性区域保持高清,而非显著性区域适当失真,以达到在主观视觉感知不变的情况下降低视频码率,提升视频压缩率,进而缩减视频存储空间,减轻视频通信的带宽负担。
2、随着深度学习的发展,视频显著性区域检测领域取得很大的进步,但是大多数的视频显著性检测模型都是以单数据集或微调方式进行训练的。由于单个数据集的数据量有限,其检测精度趋近饱和,且缺乏足够的泛化能力,阻碍了这些模型在现实生活中的应用。利用多个数据集进行训练扩充了训练数据量,看似可以解决以上问题,但是数据集之间常常存在分布偏差,直接在多数据集上训练得到的模型常常还不如单数据集或者微调模型下的结果。由此可见,如何解耦数据集间的分布差异,建模具有显著信息的共性特征是有效进行多数据集训练的关键。
技术实现思路
1、
2、本发明为了解决现有方法中的上述问题,提出一种基于多数据集协作学习的视频显著性区域检测方法。
3、一种基于多数据集协作学习的视频显著性区域检测方法,其特征在于包括如下步骤:
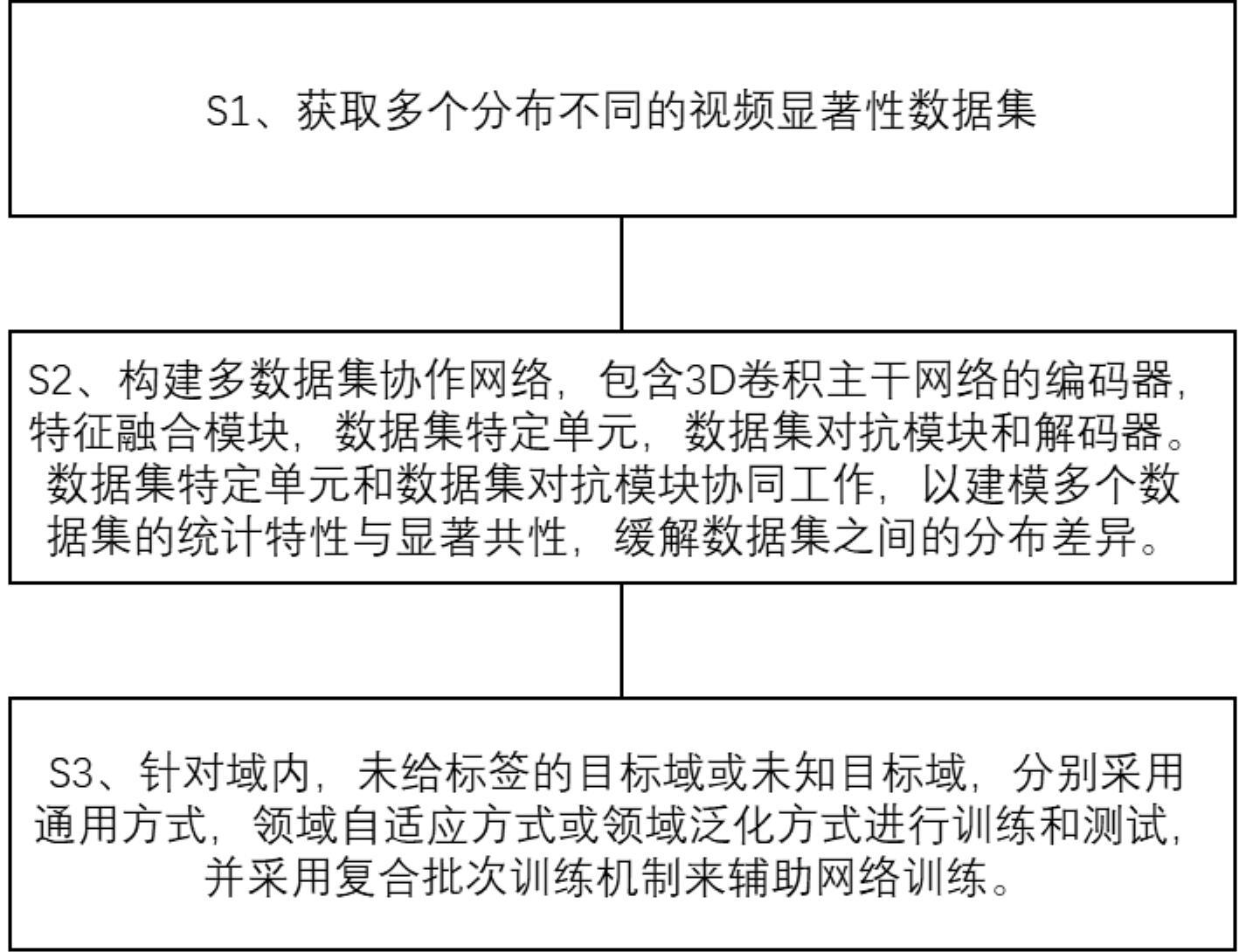
4、s1:获取多个带有标签的视频显著性数据集,其中,多个数据集的样本和标签分布不同;
5、 s2:构建多数据集协作网络,利用多数据集的信息来获取输入视频的显著图。该网络由3d卷积主干网络的编码器,特征融合模块,数据集特定单元,数据集对抗模块和解码器组成。其中,数据集特定单元包含数据集特定批归一化操作,数据集特定高斯先验图和数据集特定高斯光滑滤波器,用以建模每个数据集的统计特性;数据集对抗模块用以判断输入样本的数据集标签,产生分类损失,以对抗学习的形式促使网络学习具备显著性特征的共性;数据集特定单元和数据集对抗模块协同工作,可以建模多个数据集的统计特性与显著共性,共同来缓解多个数据集之间的分布差异问题;
6、s3:针对域内场景,采用通用方式进行训练和测试;针对未给标签的目标域,采用领域自适应方式进行训练和测试;针对未知目标域,采用领域泛化方式进行训练和测试;并采用复合批次训练机制来辅助多数据集协作网络训练。
7、进一步的技术方案在于,数据集特定单元为每个数据集设置了相应的分支,根据输入数据集的标签,自动切换开关以激活相应的分支,从而建模数据集专属特征;其具体应用分为数据集特定批归一化操作,数据集特定高斯先验图和数据集特定高斯光滑滤波器;针对跨数据集的批归一化参数分布不同,数据集特定批归一化操作为通过训练来学习每个数据集的批归一化均值与方差;针对数据集之间的高斯先验图不同,数据集特定高斯先验图为每个数据集构建不同的二维高斯先验图,用以建模每个数据集的中心注视偏差;针对数据集之间的显著图清晰度不同,采用可学习的数据集特定高斯光滑滤波器来消除此偏差。
8、进一步的技术方案在于,数据集对抗模块是由梯度反转层和数据集分类器组成;数据集分类器由卷积层和全连接层组成,用于预测输入视频所属数据集,其损失函数为多分类交叉熵损失;梯度反转层在正向传播中不进行数值变换,而在反向传播时自动反转梯度方向。
9、进一步的技术方案在于,通用方式旨在利用来自多个数据集的信息来学习一个统一模型,用以提高模型在每个数据集上的表现;在训练阶段,前向传播每个数据集的批次,反向传播显著性预测损失和数据集分类损失,在检测阶段,根据输入数据集的标签来选择相应的数据集特定单元分支,而不使用数据集对抗模块。
10、进一步的技术方案在于,领域自适应方式旨在提高在无标签目标域上的性能;在训练阶段,前向传播来自每个源域数据集和一个无标签目标域的批次,对于每个源域数据集需要计算和反向传播显著性预测损失和数据集分类损失,对于目标域则只计算和反向传播数据集分类损失;在测试阶段,对于源域数据集,根据所属数据集的标签来选择相应的数据集特定单元分支,而不使用数据集对抗模块,而对于目标域数据,选择数据量最多的源域数据集作为其数据集标签以确定对应特定单元分支。
11、进一步的技术方案在于,领域泛化方式旨在尝试从多个源域数据集中学习泛化模型,而不使用目标域数据;由于目标域的缺失,其训练阶段与通用方式相同,而测试阶段与领域自适应方式相同。
12、进一步的技术方案在于,复合批次训练机制用于促进训练过程协同优化,避免不同数据集切换带来的批次抖动;该机制按照多个源域数据集的视频数量比例,将来自每个数据集的批次构建为复合批次;在前向传播时分别计算每个数据集批次的损失,当来自所有数据集批次的损失都计算完后再进行反向传播以更新梯度。
13、采用上述技术方案所产生的有益效果在于:该方案突破了传统单数据集或微调训练方式的束缚,提出了视频显著性区域检测的多数据集协作学习范式。利用多个数据集的信息来构建统一模型,不仅提高了显著性区域检测精度,还显著提升了模型针对域外数据的泛化能力,更加适合应用在现实场景中。
技术特征:
1.一种基于多数据集协作学习的视频显著性区域检测方法,其特征在于,包括如下步骤:
2.如权利要求1所述的基于多数据集协作学习的视频显著性区域检测方法,其特征在于,所述的数据集特定单元为每个数据集设置了相应的分支,根据输入数据集的标签,自动切换开关以激活相应的分支,从而建模数据集专属特征;其具体应用分为数据集特定批归一化操作,数据集特定高斯先验图和数据集特定高斯光滑滤波器;针对跨数据集的批归一化参数分布不同,数据集特定批归一化操作为通过训练来学习每个数据集的批归一化均值与方差;针对数据集之间的高斯先验图不同,数据集特定高斯先验图为每个数据集构建不同的二维高斯先验图,用以建模每个数据集的中心注视偏差;针对数据集之间的显著图清晰度不同,采用可学习的数据集特定高斯光滑滤波器来消除此偏差。
3.如权利要求1所述的基于多数据集协作学习的视频显著性区域检测方法,其特征在于,所述的数据集对抗模块是由梯度反转层和数据集分类器组成;数据集分类器由卷积层和全连接层组成,用于预测输入视频所属数据集,其损失函数为多分类交叉熵损失;梯度反转层在正向传播中不进行数值变换,而在反向传播时自动反转梯度方向。
4.如权利要求1所述的基于多数据集协作学习的视频显著性区域检测方法,其特征在于,所述的通用方式旨在利用来自多个数据集的信息来学习一个统一模型,用以提高模型在每个数据集上的表现;在训练阶段,前向传播每个数据集的批次,反向传播显著性预测损失和数据集分类损失,在检测阶段,根据输入数据集的标签来选择相应的数据集特定单元分支,而不使用数据集对抗模块。
5.如权利要求1所述的基于多数据集协作学习的视频显著性区域检测方法,其特征在于,所述的领域自适应方式旨在提高在无标签目标域上的性能;在训练阶段,前向传播来自每个源域数据集和一个无标签目标域的批次,对于每个源域数据集需要计算和反向传播显著性预测损失和数据集分类损失,对于目标域则只计算和反向传播数据集分类损失;在测试阶段,对于源域数据集,根据所属数据集的标签来选择相应的数据集特定单元分支,而不使用数据集对抗模块,而对于目标域数据,选择数据量最多的源域数据集作为其数据集标签以确定对应特定单元分支。
6.如权利要求1所述的基于多数据集协作学习的视频显著性区域检测方法,其特征在于,所述的领域泛化方式旨在尝试从多个源域数据集中学习泛化模型,而不使用目标域数据;由于目标域的缺失,其训练阶段与通用方式相同,而测试阶段与领域自适应方式相同。
7.如权利要求1所述的基于多数据集协作学习的视频显著性区域检测方法,其特征在于,所述的复合批次训练机制用于促进训练过程协同优化,避免不同数据集切换带来的批次抖动;该机制按照多个源域数据集的视频数量比例,将来自每个数据集的批次构建为复合批次;在前向传播时分别计算每个数据集批次的损失,当来自所有数据集批次的损失都计算完后再进行反向传播以更新梯度。
技术总结
本发明公开了一种基于多数据集协作学习的视频显著性区域检测方法。所述方法包括如下步骤:获取多个分布不同的视频显著性数据集;构建多数据集协作网络,通过数据集特定单元以建模多数据集的统计特性,通过数据集对抗模块以促使网络学习具备显著性特征的共性,二者联合来缓解数据集之间分布差异问题;针对不同的应用场景,提出相对应的多数据集训练和测试方式,并采用复合批次训练机制以优化协作学习过程。所述方法区别于常见的单数据集或微调训练模式,利用多个数据集的信息来提升视频显著性区域检测精度,并提高模型在域外数据上的泛化表现。
技术研发人员:张云佐,张天,郑宇鑫,武存宇,刘亚猛,于璞泽,康伟丽,朱鹏飞,王双双
受保护的技术使用者:石家庄铁道大学
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!