一种应用于知识蒸馏的知识选择方法与流程
本发明涉及一种知识蒸馏技术,具体为一种应用于知识蒸馏的知识选择方法。
背景技术:
1、预训练语言模型(plm,pre-trained language model)通常采用双向的transformer来堆叠而成,通过在大规模单语语料进行训练,然后在特定任务数据进行微调,可以达到优异的性能。尽管能够在很多自然语言处理任务上达到优异的性能,但是其由于拥有庞大的体积,导致其遭受难以部署、计算代价较大和推理时间较长等问题。知识蒸馏是压缩plm方法中的一类方法,也是最常用的一种方法,表示精简、体积较小的plm(学生模型),在具有更大规模的、性能更好的plm(教师模型)的指导下进行训练更新。
2、plm采用多个双向的transformer模型进行堆叠而成,每一个transformer的输出是下一个transformer的输入。通常,每一层transformer的输出也称为中间层特征。在进行文本分类的时候,其特点是,利用编码器将输入的文字序列转化为包含文字信息的向量,然后在最后一层的时候加入一个分类器,来进行计算输入文本类别概率分布。
3、早期的文本分类框架,就是使用卷积神经网络编码输入文本序列,然后使用循环神经网络(rnn,recurrent neural network)转换模型中间向量为对应文本的最终特征向量,然后将该特征向量输入一个分类器进行分类。其中带有注意力机制的plm在文本分类中的成功应用,将文本分类带上了一个新的高度。在plm读取文本之后,注意力机制模仿了人类读取文本的过程,模型在就算输入文本特征向量时,并不像循环神经网络那样,将所有单词视同一律,而是为不同单词赋予不同的权重,与当前时刻的词相关性高的词,将获得较高的注意力权重,可以看出,注意力机制的引入,缓解了循环神经网络的不足。
4、在实际的过程中,无论是文本分类还是其他的基于深度神经网络的任务都是在不断的进行模拟人的行为,并且于此也在不断的创新和突破。在知识蒸馏过程中如此,设想,如果有一个模型先去学习所拥有的语料库知识,然后借用这个模型所学习的知识,也许能够帮助其他模型进行更好的学习。
5、虽然现在已经存在着一些针对知识蒸馏的知识选择方法,比如动态地调整损失的权重,但是依然存在以下不足:
6、1)并没有直接对知识类型进行建模,比如动态调整损失权重。在调整损失权重时并没有把知识和损失进行直接相关联系,也并没有直接的去解决知识蒸馏中知识选择这一问题;
7、2)损失权重调节建模方式简单,现有的权重调节的方式往往是直接使用模型的置信度等一些相关的因素进行直接建模,但是世界上知识的选择受到多个因素影响,并不是单纯的某些因素可以决定;
8、3)同时考虑较少的知识类型,现有的方法并没有较系统地把所有的知识进行归类划分,而是针对某一个知识来去解决知识选择问题。比如回复知识,现有的方法只针对在训练过程中回复知识应该不应该被学生模型进行学习这一问题进行研究,而忽略了其他类型的知识。
技术实现思路
1、针对现有知识蒸馏中训练时候知识类型多样的问题,导致学生模型可能学习不到正确的知识等不足,本发明要解决的技术问题是提供一种应用于知识蒸馏的知识选择方法,可以根据教师模型和学生模型学习的状态来判断当前情况下应该让学生模型学习什么类型的知识,以获得更好的性能,在知识蒸馏的训练过程中更加充分和正确地利用教师模型的知识。
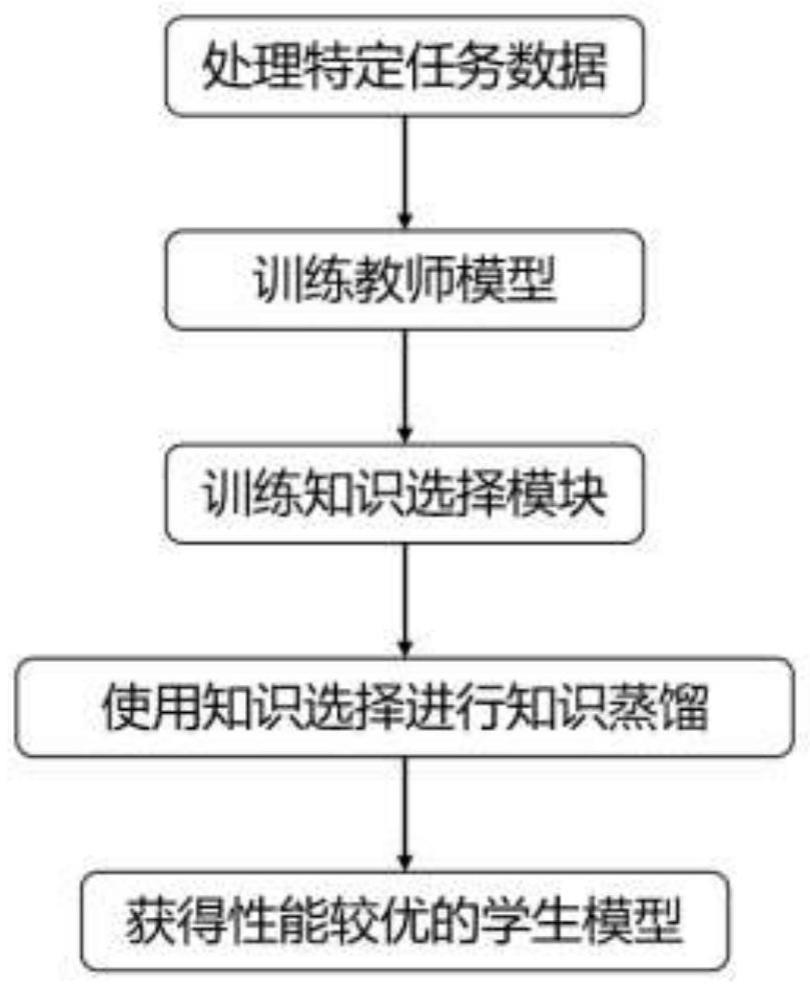
2、本发明提供一种应用于知识蒸馏的知识选择方法,包括以下步骤:
3、1)使用文本分类任务的数据训练教师模型;
4、2)使用训练后的教师模型来抽取不同类型的知识,并把这些知识进行分类;
5、3)基于训练后的教师模型来初始化学生模型;
6、4)使用reinforce算法训练知识选择模块;
7、5)使用被训练过后的知识选择模块来训练最终的学生模型,训练时知识选择模块根据对应教师模型和学生模型的特征来选择学生模型应该学习的类型的知识。
8、步骤1)是使用所拥有的文本分类任务数据进行训练教师模型,表示为:
9、teachermodel=modeltrain(s,b)
10、其中modeltrain为模型训练函数,s为输入文本集合,b为输入文本的标签,表示单一的训练一个文本分类模型。
11、步骤2)具体步骤为:
12、201)设文本分类任务为二分类任务,其输入的文本为s=(s0,s1,s2,…si…,sm),其si表示文本s中的第i个句子;对应文本分类的标签为b=(b0,b1,b2,…bi…,bm),其bi表示句子si对应的分类标签,其值为0或1;
13、使用教师模型对所给文本s中句子si进行分类,产生三类不同的知识;
14、202)抽取教师模型对输入句子xi所计算出来的概率分布pt(xi)作为回复知识;
15、203)抽取教师模型最后一层表示作为特征知识lt(xi);
16、204)计算教师模型每一层之间的输出之间的相对关系作为相对知识rt(xi)。
17、步骤4)通过使用reinforce算法来训练一个知识选择模块,具体步骤为:
18、401)在训练的每一步中,分别提取教师模型和学生模型最后一层的表示向量,然后将其连接起来作为知识选择模块的特征输入f(x),表示包含对应知识蒸馏过程中教师模型和学生模型的学习状态和数据特征;
19、402)知识选择模块根据输入的特征决策当前状态下学生模型应该学习的类型的知识,让学生模型进行学习;
20、403)在知识蒸馏完成后,计算学生模型在校验集上的得分,然后用该得分和学生模型初始状态在校验集上的得分做差作为获得对应知识选择模块决策的奖励值r;
21、404)使用奖励值r和知识选择模块在步骤402)中所做出决策的损失和来更新知识选择模块的参数;
22、405)重复步骤401)到404),直到知识选择模块模型参数收敛。
23、步骤5)中,使用步骤4)所训练的知识选择模块决策学生模型在训练过程的每一步应该学习的类型的知识,具体步骤如下:
24、501)提取当前训练步中教师模型和学生模型最后一层的输出表示向量,并拼接成为特征f(x),输入知识选择模块获得当前训练步应该给学生模型进行学习的知识类型;
25、502)根据知识选择模块提供的决策,来更新学生模型的参数,最终实现了知识选择。
26、本发明具有以下有益效果及优点:
27、1.本发明全面的划分知识蒸馏过程中知识类型,在知识蒸馏过程常用的知识类型为1)回复知识,其来源于教师模型最后输出的概率分布;2)特征知识,其来源于教师模型最后一层输出的向量表示;3)相对性知识,其来源于教师模型层与层之间的相对关系。
28、2.本发明使用神经网络来进行选择特定的知识类型,其可以根据输入来自动学习相关特征,从而来决策在当前训练步中学生模型应该学习什么类型的知识,并不像现有的一些方法进行手动提取特征,具有很好地自适应能力。
29、3.本发明可以针对多个知识类型进行选择,并且可以根据现有的需求来进行扩展知识空间和奖励函数,具有易操作、易扩展等优势。
30、4.除了上述所述以外,本发明还具有很强的灵活性,比如教师模型可以采用性能比较强的集成模型,从而从集成的模型中来选择更加适合学生模型学习的知识类型。
- 还没有人留言评论。精彩留言会获得点赞!