基于可变形关键点注意力的轻量化视频连续情感识别方法
本发明属于视频处理,具体涉及一种基于可变形关键点注意力的轻量化视频连续情感识别方法。
背景技术:
1、情感是人对客观事物的态度体验以及相应的行为反应。如今人工智能越来越朝着理解人类、服务人类、以人类为中心的方向发展,准确地识别人类的情感是实现以人为中心的人工智能的目标之一。通过获取人类的情感,越来越多的现实应用走进了大众的视野,如在医疗领域通过分析情感可以实现对抑郁等精神疾病的筛查、实现更智能和人性化的人机交互等。连续情感是在连续的维度上通过几种指标编码每一种情感强度的微小变化,可以更加精细和准确的表述人类的情感。两个最常用的指标为唤醒程度(arousal)和效价值(valence)。唤醒程度反映了情感的激动或平静程度,效价值反映了情感的积极或消极程度。
2、视频中包含丰富的情感线索。一般而言,视频连续情感识别方法包含两个阶段。在第一阶段,空间编码器从视频的每帧中提取出单帧情感表征;在第二阶段,时间编码器对不同帧情感表征之间的时序依赖进行建模以细化每一帧的情感表征。传统的空间情感表征提取方法主要基于手工设计,比如局部二值模式(lbp)、三个正交面板的局部二值模式(lbp-top)、非负矩阵分解(nonnegative matrix factorization)等。这些方法基本依赖于先验知识,并且鲁棒性很差,尤其在长时序范围内难以获取复杂的情感变化。最近基于深度识别的方法在情感识别的性能上取得了突破性的进展。卷积神经网络(cnns)因其卓越的特征提取能力成为目前的主流方法,例如vgg、resnet、densenet等。现有的方法大多将整张人脸图像作为模型的输入,忽略了人类情感主要依赖于局部面部关键区域这一先验知识。yong li等人在2018年提出基于面部关键点从人脸图像中裁剪出局部区域,然后对这些局部区域的特征进行聚合得到人脸的表征,但是这些方法依赖于人脸关键点检测器,而它的性能容易受到光照变化、遮挡等因素的影响。如何精准的定位出面部关键区域并在全局范围内建立不同局部区域之间的依赖关系仍然是个亟待解决的问题。
3、另外,在时序建模阶段,循环神经网络(rnns)和时序卷积神经网络(tcns)体现了它们在建模时序依赖方面的能力。然而rnns受着梯度消失等问题的干扰,tcns理论上可以通过膨胀卷积或下采样扩大时序感受野,但其实际感受野远低于理论感受野。这些因素限制了它们在建模长时序依赖方面的能力。近年来,transformer凭借其更强的远距离建模能力逐渐成为视频理解任务的新趋势,anurag arnab等人在2021年提出了vivit,gedasbertasius等人在同年提出了timesformer,它们在视频理解任务上表现出了超越以往方法的性能。但是这些方法的参数规模往往过于庞大,在小规模的视频数据集上很容易出现过拟合的问题。因此,在提高长时序依赖建模能力的同时如何使模型轻量化以适应小规模数据集成为提升情感识别性能的关键。
技术实现思路
1、针对上述视频连续情感识别方法中存在的技术缺陷,本发明的目的在于提出一种视频连续情感识别方法,特别涉及一种基于可变形关键点注意力的空间域情感表征提取方法和基于transformer的轻量化长时序依赖特征提取方法。基于现有视频连续情感识别方法对与情感有关的面部关键区域定位不准确,无法良好的建立不同区域之间的依赖关系,以及在小规模的视频情感数据集上的过拟合问题,本发明充分发挥面部关键区域对情感识别的作用,使提取的情感表征更加鲁棒,且能够防止过拟合问题,使得模型轻量化,由此提高了识别效率。
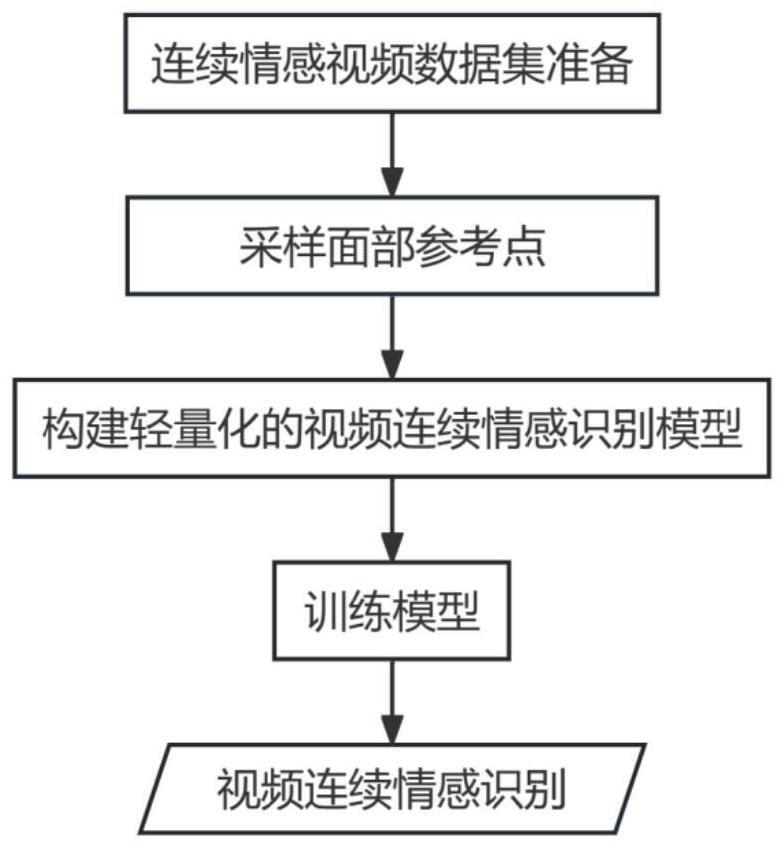
2、本发明提供的一种基于可变形关键点注意力的轻量化视频连续情感识别方法,具体步骤包括:
3、获取带有连续情感标签的视频数据集;视频数据集包括训练视频数据集;
4、基于训练视频数据集采样面部参考点;
5、构建轻量化视频连续情感识别模型;视频连续情感识别模型包括空间编码器和时序编码器;输入按时序排列的多帧人脸图像到空间编码器,空间编码器提取每帧人脸图像的浅层情感特征和高层情感特征;将所有人脸图像的高层情感特征按时序输入到时序编码器中建立时序依赖获得人脸情感表征序列;将人脸情感表征序列输入推理子网获取每帧人脸图像的情感预测值;
6、基于训练视频数据集训练轻量化视频连续情感识别模型;
7、使用训练后的轻量化视频连续情感识别模型进行视频连续情感识别。
8、可选地,基于训练视频数据集采样面部参考点的具体步骤包括:获取训练视频数据集中每帧人脸图像的面部关键点;基于面部关键点选取候选点;基于候选点生成二维高斯激活热图;使用二维高斯激活热图中每个像素点的像素值作为其被采样的权重值;从该热图的所有像素点中进行采样,被采样的点为面部参考点。
9、可选地,对二维高斯激活热图的所有像素点进行两次采样,分别获得两次采样的多个面部参考点。
10、可选地,二维高斯激活热图中的像素点被采样概率和该像素点的像素值成正比时,采样该像素点为面部参考点。
11、可选地,基于swin transformer构建空间编码器,具体步骤为:将输入的每帧人脸图像划分为若干个相互不重叠的区域;将每个区域展平为区域特征嵌入序列;将每帧人脸图像的每个区域特征嵌入序列输入swin transformer提取该帧人脸图像的浅层情感特征图;基于浅层情感特征图通过可变形关键点注意力法提取高层情感特征。
12、可选地,基于浅层情感特征图通过可变形关键点注意力提取高层情感特征的具体步骤为:获取浅层情感特征图的网格点n×n,n×n为浅层情感特征图的网格点总数;将第一次采样获得的多个面部参考点投影到浅层情感特征图的网格点n×n上进行可变形注意力处理获得二次处理特征图和第一高层情感特征;将第二次采样获得的多个面部参考点投影到二次处理特征图的网格点m×m上进行可变形注意力处理获得第二高层情感特征,m×m为二次处理特征图的网格点总数。
13、可选地,可变形注意力处理的操作步骤为:
14、将面部参考点投影到对应的特征图上,通过双线性插值法获取各个面部参考点的情感表征:
15、
16、其中,表示双线性插值;p表示面部参考点的位置坐标,r表示空间编码器提取图像的高层语义特征时使用的特征图,r′表示面部参考点的情感特征。
17、可选地,将面部参考点的情感特征r′输入偏移子网中,获得每个面部参考点在x轴和y轴方向上的偏移量;基于面部参考点的位置坐标和偏移量,获取各个面部参考点偏移后的坐标:
18、△p=θ(r’);
19、p′=+δp;
20、式中,θ表示偏移子网,△p表示偏移量,p′表示偏移点的位置坐标;
21、将偏移点p′的位置坐标投影到特征图r上,通过双线性插值获得偏移点的情感表征r″:
22、
23、基于特征图r和偏移点的情感表征r″,采用多头注意力法提取图像的高层情感特征,表达式为:
24、q=rwq,k=r″wk,v=r″wv;
25、其中,特征图r用于生成多头注意力的查询特征q,偏移点的情感表征r″用于生成多头注意力的键特征k和价值特征v;wq、wk和wv分别表示查询投影矩阵、键投影矩阵和价值投影矩阵;
26、通过查询特征q、键特征k和价值特征v获得人脸图像的高层情感特征z:
27、
28、z=concat(z(1),...,z(m))o;
29、其中,z(m)、q(m)、k(m)和v(m)分别表示第m个注意力头的输出高层情感特征、查询特征、键特征和价值特征,m’表示注意力总头数;wo表示输出投影矩阵;σ表示softmax函数;d表示每个注意力头的维度。
30、可选地,基于transformer编码层构建时序编码器;时序编码器包括多层transformer编码层堆叠;每层transformer编码层包括多头注意力层和前馈层。
31、可选地,视频数据集还包括验证视频数据集;基于验证视频数据集评估训练好的轻量化视频连续情感识别模型的性能;如果性能评估满足性能评估阈值,则轻量化视频连续情感识别模型满足要求。
32、本发明至少具有如下有益效果:
33、(1)本发明为视频连续情感识别任务提出了一种全transformer时空模型,充分利用了transformer具有全局感受野和捕捉长时序依赖的优势,同时改善了现有的全transformer模型参数规模过大的问题,使得模型轻量化,提升了视频连续情感识别的有效性和高效性。
34、(2)本发明的方法能够对面部关键点采样,相比于直接通过关键点检测器获取的面部关键点,该方法提取的关键点更加准确与全面。
35、(3)本发明的方法基于面部关键点的可变形注意力充分挖掘面部局部关键区域的作用,使得在识别过程中更能关注于与表情识别有关的面部局部关键区域并能在全局范围内建模不同局部区域之间的依赖关系,提高了情感识别的效果。
36、本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本实发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!