一种基于跨层注意力机制的多维特征提取投诉文本智能分类方法、系统及存储介质
本发明涉及人工智能,尤其是涉及一种基于跨层注意力机制的多维特征提取投诉文本智能分类方法、系统及存储介质。
背景技术:
1、随着网络技术的不断发展,互联网中存在着海量的信息数据,特别是文本数据,其数据量最为丰富。这些数据具有较高的实用价值,可以将其利用起来,挖掘出其中隐藏的信息,帮助决策人员减轻工作量,降低人力成本,以及观察事情的发展趋势,有利于后续工作的开展。如何快速有效地获取需要的文本信息,是人工智能领域所研究的一个重要分支,基于文本内容的分类任务也正在逐步融入每个人的日常生活中。各类基于自然语言处理(natural language processing,nlp)技术的智能设备在智能家居、智慧医疗乃至生产生活的各类领域都得到了广泛的应用。
2、文本分类作为自然语言处理中的一项基础性工作,在情感分析、问题分类等诸多工作中起着至关重要的作用。众所周知,不同的nlp任务需要不同的语言特征。文本分类等任务需要更多的语义特征,而依赖关系解析等任务则需要更多的语法特征。现有的大多数方法主要是通过混合和校准特征来提高性能,而没有区分特征类型和相应的效果,导致分类识别的准确率有所折扣。在特征提取之前,对分类结果有着相同影响力的还有对数据的预处理,如果直接对原始数据进行建模,这种做法是非常不负责任的。一方面,数据的质量参差不齐,充斥着各种噪声,甚至可能存在错误,我们必须认真考察原始数据的分布情况,把握数据的整体特征,将这些错误数据剔除;另一方面,建模之前的预处理可以减轻模型的负担,提高识别的准确率。
3、基于文本的分类识别任务主要采用机器学习和深度学习算法。从60年代到2010年前后,基于机器学习的浅层学习文本分类模型占主导地位。浅层学习即基于统计的模型,例如朴素贝叶斯(naive bayes,nb),k近邻(k-nearest neighbor,knn)和支持向量机(support vector machine,svm)。与早期的基于规则的方法相比,该方法在准确性和稳定性方面具有明显的优势。但是,这些方法仍然需要进行功能设计,这既耗时又昂贵。此外,它们通常会忽略文本数据中的自然顺序结构或上下文信息,这使学习单词的语义信息变得困难。自2010年以来,文本分类过程中所使用的主流模型已逐渐从浅层学习模型变为基于人工神经网络的深层学习模型。与基于浅层学习的方法相比,深层学习方法避免了人工设计规则和功能,并自动为文本挖掘提供了语义上有意义的表示形式。因此,大多数文本分类研究工作都基于深度神经网络(deep neuralnetworks,dnn),dnn是数据驱动的方法,具有很高的计算复杂性。很少有研究专注于使用浅层学习模型来解决计算和数据的局限性。
技术实现思路
1、本发明的目的是提供一种基于跨层注意力机制的多维特征提取投诉文本智能分类方法、系统及存储介质,采用更细致的文本预处理方法来提高文本信息的可信度,从而提升文本的最终分类效果,能够更加全面的提取文本的各方面特征,使本系统具有较强的鲁棒性,可用于企业对客户的投诉进行及时的监管,减少投诉处理时的人力投入以及提高投诉处理的效率,也可用于涉及文本分类的智能家居及智慧医疗等领域。
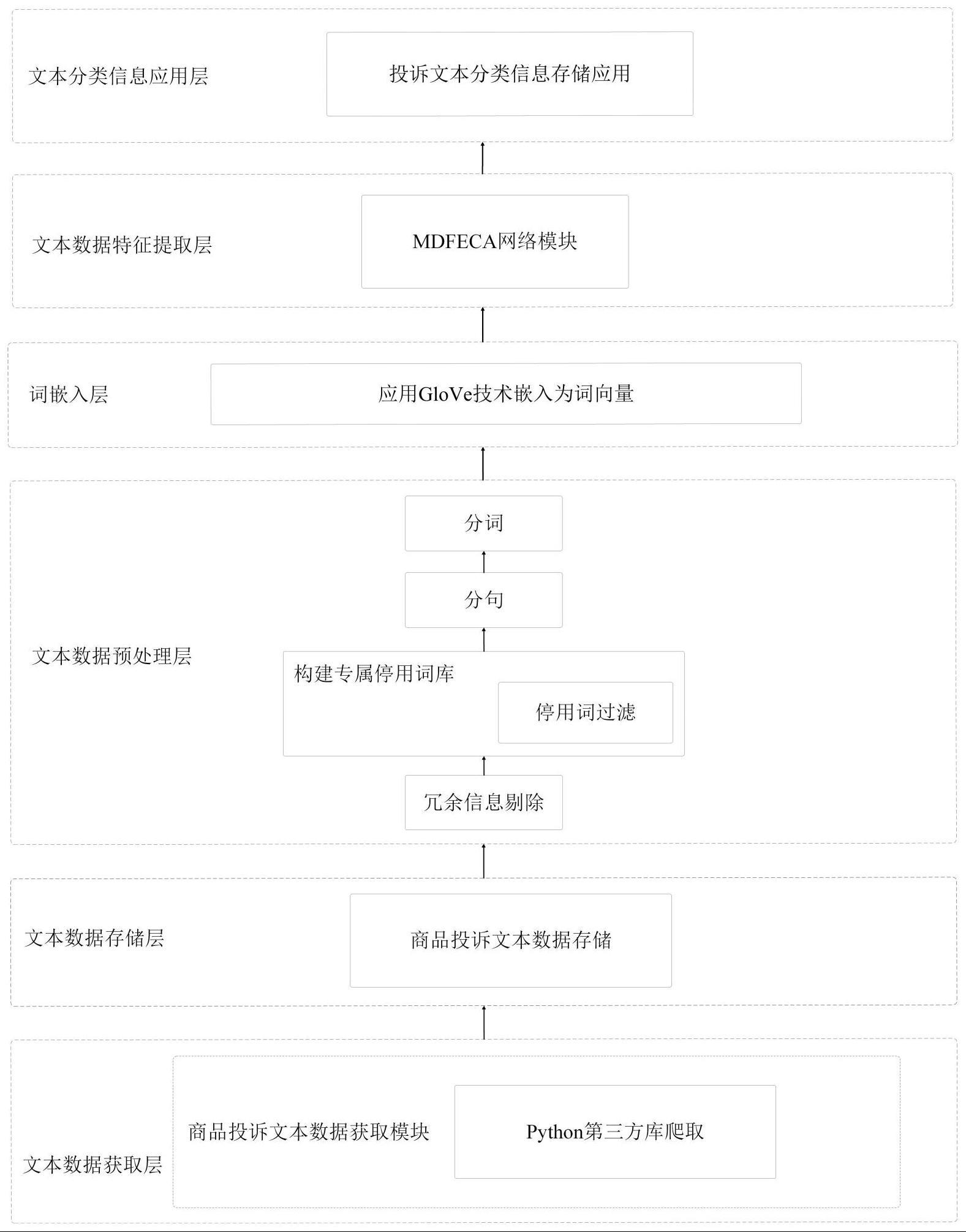
2、为实现上述目的,本发明提供了一种基于跨层注意力机制的多维特征提取投诉文本智能分类系统,包括依次连接的文本数据获取层、文本数据存储层、文本数据预处理层、词嵌入层、文本数据特征提取层和文本分类信息应用层;
3、所述文本数据获取层使用爬虫程序进行所需的商品投诉文本数据获取;
4、所述文本数据存储层将采集的商品投诉文本原始数据存储至本地服务器或云服务器中;
5、所述词嵌入层将预处理后的文本信息应用glove技术嵌入为词向量,使各字词在低维向量空间得到表达,便于后续分类器进行特征提取。
6、优选的,所述文本数据预处理层包括对爬取到的原始文本数据进行预处理,以得到预处理后的投诉文本信息。
7、优选的,所述文本数据特征提取层包括mdfeca网络模块,所述mdfeca网络模块包括堆叠transformer结构全局特征提取单元、最大池化单元、跨层注意单元、卷积块注意力模块时空特征提取单元、特征融合单元、多层感知器单元和输出单元。
8、优选的,所述文本分类信息应用层用于:将文本数据及识别结果同时在数据库服务器中进行分类存储,并将同类型的投诉信息分发至相应的部门进行处理。
9、上述的一种基于跨层注意力机制的多维特征提取投诉文本智能分类方法,包括以下步骤:
10、步骤s1:投诉文本数据获取,从消费者服务平台,选择用户对投诉内容进行文本数据爬取;
11、步骤s2:文本数据存储,将获取到的原始文本数据存储至本地服务器或云服务器;
12、步骤s3:原始文本数据预处理,对获取到的原始文本数据进行预处理,以得到预处理后的投诉文本数据,便于后续词嵌入操作;
13、步骤s4:构建文本预训练模型,将预处理后的文本信息,应用glove技术嵌入为词向量,使各字词在低维向量空间得到表达;
14、步骤s5:构建并训练文本分类模型,将经过投诉文本预训练模块处理好的数据输入到已经训练好的投诉文本分类模块中的文本分类器中进行分类识别,输出文本内容相对应的分类识别结果;
15、步骤s6:文本分类信息存储应用,通过文本分类信息存储应用模块,将投诉文本分类的结果进行存储,并可将该信息进行分类投放至对不同类别投诉信息处理的部门。
16、优选的,步骤s1中,数据的爬取采用pycharm编辑器,利用python中的urllib模块,通过定义爬虫类的方式编写爬虫程序,将网页上非结构化的各种信息转化为半结构化的表格储存在本地服务器或者云服务器,便于后续分析处理。
17、优选的,步骤s3,所述原始文本数据预处理包括以下步骤:
18、步骤s31:冗余信息处理,获取的原始文本数据包含许多字段的信息,其中一部分是对于本任务中文本分类无用的字段,经过冗余信息处理,剔除掉这一部分内容;
19、步骤s32:文本清洗,文本清洗阶段涉及专属于投诉文本内容制定的停用词库;
20、步骤s33:标准化,对于投诉内容中常出现的繁体字,需要将其标准化为简体字,标准化采用opencc工具包来完成;
21、步骤s34:分句,引入re模块进行分句处理,采用re.split(·)来执行分句操作,设置好需要切分的字符串;
22、步骤s35:分词,使用中文分词库结巴分词来完成中文分词工作,分词完成后得到完整预处理的文本数据。
23、优选的,步骤s4,所述文本预训练模型为:
24、s=w(e)v
25、式中,v表示句子转化成向量的形式,w(e)表示词嵌入权重矩阵,s表示句子的低维密集向量表示。
26、优选的,步骤s5,所述构建并训练文本分类模型是通过应用glove技术得到的词向量,将其输入到构建的mdfeca网络模块文本分类器中进行文本分类输出,包括以下步骤:
27、步骤s51:捕捉全局上下文信息;
28、步骤s52:跨层注意力机制;
29、步骤s53:捕捉重要局部特征;
30、步骤s54:特征拼接;
31、步骤s55:全连接层。
32、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行计算机程序时实现上述的一种基于跨层注意力机制的多维特征提取投诉文本智能分类方法的步骤。
33、本发明所述的一种基于跨层注意力机制的多维特征提取投诉文本智能分类方法、系统及存储介质的优点和积极效果是:
34、1.实用性:文本信息的分类对原始数据质量的要求和准确率有较高的要求,本发明使用合适的数据获取方式能够准确的获取针对特定任务场景的文本数据;同时在文本分类的准确率方面也具备了一定的优势。
35、2.自适应性:针对不同的应用场景,通过修改堆叠的transformer层数、卷积块注意力模块网络单元结构等,提高了输入数据的普适性。
36、3.高可靠性:与主流的模型算法相比,充分的数据预处理过程与能够提取更加丰富特征的分类神经网络,使本系统具有较强的鲁棒性,同时在准确率方面有了进一步的提升。
37、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!