多副本非原子写的TLB作废操作实现方法与实现装置与流程
本发明属于非原子写的tlb作废操作,尤其是涉及一种多副本非原子写的tlb作废操作实现方法与实现装置。
背景技术:
1、现代微处理器一般采用多核多线程共享存储架构,存储一致性是支撑并行程序在该架构下能正确运行的基础。存储一致性定义了对不同地址的存储访问操作的排序规则,根据其所允许的排序规则不同,存储一致性可以有多种存储一致性实现模型,例如顺序(sequential)一致性模型、tso(total store order)模型、松弛(relaxed)一致性模型等。由于不同的存储一致性模型定义了不同的合法存储序,因此软件编程人员必须清楚多核多线程共享存储架构所采用的存储一致性模型,才能在该架构上编写出正确的并行程序。
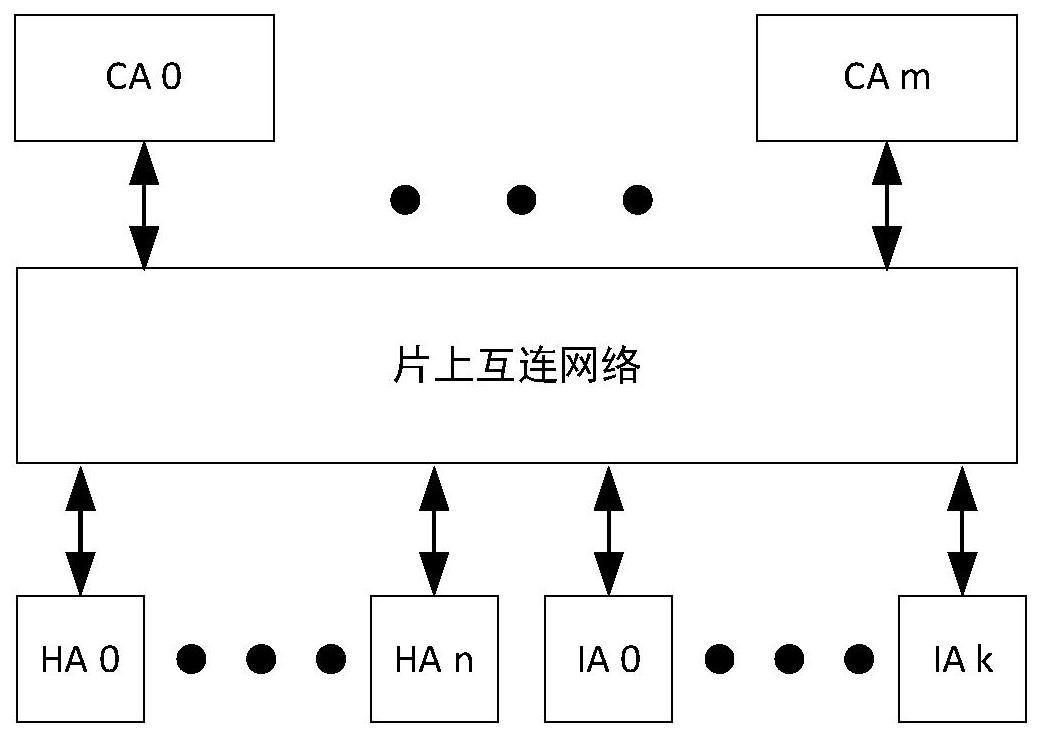
2、为了提高访存性能,现代多核多线程微处理器一般都会实现多级cache。cache的引入会导致相同地址多个数据副本之间的不一致性,为了解决该问题,多核多线程微处理器一般会采用cache一致性协议来保证不同cache中数据副本的一致性。cache一致性协议的实现一般需要cache代理(cache agent,ca)、目录代理(home agent,ha,现代多核多线程微处理器大都采用基于目录的cache一致性协议)、io代理(io agent,ia)。ca中的cache可以缓存数据副本,能发出访问请求、接收数据响应和监听请求(用于作废数据副本或获取最新数据)。ha用于记录数据副本的状态,能接收访问请求、发出数据响应和监听请求。ia不能缓存数据副本,能发出访问请求和数据响应、接收访问请求、数据响应和监听请求(用于获取最新数据)。从上可看出,为了避免协议死锁,一致性协议的实现至少需要三个消息通道,即请求通道、响应通道和监听通道,分别用于传输访问请求、数据响应和监听请求。ca、ha和ia通过片上互连网络进行连接,且该网络一般是维序网络(即从相同源agent发出的消息会顺序到达同一个目的agent)。
3、多核多线程微处理器的处理器核到内存之间可能存在多级缓存,处理器核硬件线程发出的最新写数据需要经过多个缓存才能最终达到内存,这使得有些缓存中的数据是最新的数据副本,而有的缓存中的数据是旧的数据副本,这会引入写操作的原子性问题。存储一致性除了要定义合法的存储序规则,还需要定义写操作的原子属性,以描述写操作的原子性问题。根据不同硬件线程所能观察到的写数据的新值的时间不同,写操作的原子属性可以分为多副本原子写(multi-copy atomic write,mcaw)和多副本非原子写(non-multi-copy atomic write,non-mcaw)两类。mcaw保证了当某个硬件线程观察到了某个写操作,且该硬件线程不是该写操作的发起者,则所有其它线程都能观测到该写操作。mcaw使得某个硬件线程的写数据要么能被其它硬件线程同时观察到(即都能读取新值),要么都不能被观察到(即都只能读取旧值),这说明写操作具有原子特性。non-mcaw则无法保证写操作的原子特性,当某个硬件线程观察到了某个写操作时,其它线程不一定能观察到该写操作,即有的硬件线程能读取该写操作的新值,而有的线程只能读取该写操作的旧值。
4、采用mcaw实现方式的微处理器架构有x86、armv8等。这些架构一般采用写回cache,并且在cache一致性协议中,只有在获得了写操作权限(即作废所有其它被缓存的数据副本)之后才能在cache中写入新值。由于mcaw能使软件人员看到具有原子特性的写操作视图,因此可以简化软件的并行编程,但是这些架构为了支持写的原子特性需要付出较大的硬件代价。采用non-mcaw实现方式的微处理器架构主要是power系列处理器。这些架构一般采用写穿透cache,并且在cache一致性协议中,cache可以被直接写入新值,而不需要获取写权限、等待所有其它被缓存的数据副本的作废完成。non-mcaw可以简化硬件设计,但会增加并行编程难度,因为此时软件人员看到的是具有非原子特性的写操作视图。
5、现代微处理器的处理器核中一般都实现了tlb(translation lookaside buffer)用于缓存常用的虚地址到物理地址的映射关系,以加速操作系统的虚存管理操作的执行速度。操作系统一般会以页面单位在页表中维护每个已分配页面的虚地址到物理地址的映射关系。当页面被释放回收或其映射关系发生了变化时,tlb中用于缓存该映射关系的表项需要被作废掉。由于每个处理器核的tlb都有可能缓存同一页面的虚地址到物理地址的映射关系,所以当该页面被释放回收或其映射关系发生变化时,为使得所有tlb中缓存的页面地址映射关系与操作系统维护的页表保持一致,所有处理器核中缓存了该映射关系的tlb表项都需要被作废掉(即tlb shootdown)。为缩短tlb作废操作的执行时间,现代高性能微处理器一般在硬件上支持tlb shootdown操作:即由执行tlb shootdown指令的处理器核向所有其它处理器核广播tlb作废请求;当处理器核收到tlb作废请求后将本地tlb中的对应表项作废掉,然后向发起tlb shootdown的处理器核返回tlb作废响应;当执行tlb shootdown指令的处理器核收集齐所有的tlb作废响应并完成本处理器核的tlb作废操作之后,tlbshootdown指令执行完毕。
6、当页面的虚地址到物理地址的映射关系发生变化时,必须确保发生变化后的新的写操作数据能覆盖发生变化前的旧的写操作数据,这样后续新的读操作才能获得最新的数据。因此,当处理器核收到tlb作废请求时,除了需将对应的tlb表项作废,还需等待前序发出的所有写操作都已完成之后,才能返回tlb作废响应。现代微处理器中的ha和ia一般为写操作的存储一致性点,即先到达ha或ia的写操作数据会被后到达的写操作数据所覆盖。因此,处理器核所发出的前序写操作的完成标志为所有这些写操作都已经达到了微处理器的存储一致性点ha或ia。
7、采用mcaw实现方式的微处理器架构能比较容易判别写操作完成标志,因为在该架构下,写操作只有在获得了写权限之后才能执行,由于写权限是由存储一致性点ha或ia颁发的,当处理器核执行完写操作时,该写操作肯定已经到达了存储一致性点。因此基于mcaw实现方式的处理器核能很容易判别写操作完成标志,从而能很容易实现tlb作废指令。但是,对于采用non-mcaw实现方式的微处理器架构,写操作完成标志的判别比较困难,因为在该架构下,写操作的执行不需要获得写权限就能执行,只要处理器核发出了写操作,则代表写操作执行完毕,但此时写操作可能还未达到存储一致性点ha或ia。
8、在本技术之前,申请人针对non-mcaw实现方式的微处理器架构有提出过专门用于解决在该架构中的强同步语义实现问题的方案—多副本非原子写的存储序同步操作实现方法与实现装置[公开号:cn113900968a],该方案考虑到了对于采用non-mcaw实现方式的微处理器架构,当处理器核的cache处理完所有的存储访问请求时,此时只能保证所有的读访问响应都已返回,而无法保证写全局可见,因此提出用于解决强同步语义实现问题的方案。但是,该方案仅解决了强同步语义实现问题,无法解决non-mcaw情形下的tlb作废操作的实现问题,也无法通过使用同步处理模块的处理方式解决non-mcaw下的tlb作废操作实现问题。此外,现有技术也未有公开文献给出non-mcaw情形下的tlb作废操作的实现方法。
技术实现思路
1、本发明的目的是针对上述问题,提供一种多副本非原子写的tlb作废操作实现方法与实现装置。
2、为达到上述目的,本发明采用了下列技术方案:
3、一种多副本非原子写的tlb作废操作实现装置,包括采用非原子写实现方式的微处理器架构,所述的微处理器架构包括若干ca、若干ha和若干ia,若干ca通过片上互连网络连接于若干ha和若干ia,每个ca均对应有一tlb作废处理模块,每个tlb作废处理模块分别连接在其对应的ca与片上互连网络之间;
4、所述的片上互连网络至少具有请求通道、响应通道和监听通道三个消息通道;
5、所述的tlb作废处理模块包括处理器核请求队列、tlb作废监听请求队列、非tlb作废监听请求队列、tlb作废响应计数器和响应通道过滤器;
6、处理器核请求队列,用于存储来自与本tlb作废处理模块相连的本地ca发出的访问请求;
7、tlb作废监听请求队列,用于存储来自片上互连网络的,由tlb作废请求转换而来的tlb作废监听请求,即当tlb作废处理模块不是源tlb作废处理模块时,用于存储该种情况的tlb作废监听请求;存储来自处理器核请求队列的,由tlb作废请求转换而来的tlb作废监听请求,当tlb作废处理模块是源tlb作废处理模块时,用于存储该种情况的tlb作废监听请求。
8、非tlb作废监听请求队列,用于存储来自片上互连网络的监听请求;
9、tlb作废响应计数器,用于记录本地ca在执行了tlb作废指令之后,还未收到的tlb作废响应数量,当tlb作废响应计数器归零后,产生tlb作废完成响应发送给本地ca;
10、响应通道过滤器,用于从片上互连网络发往本地ca的响应消息中识别出tlb作废拒绝响应消息和tlb作废完成响应消息,并对tlb作废响应计数器进行相应的减操作,其余响应消息直接发送给本地ca;接收来自处理器核请求队列的tlb作废拒绝请求,产生发往源tlb作废处理模块的tlb作废拒绝响应消息,并通过响应通道发送到片上互连网络。
11、在上述多副本非原子写的tlb作废操作实现装置中,采用公平轮转调度方式从tlb作废监听请求队列和非tlb作废监听请求队列中调度出一个监听请求发送至本地ca。
12、在上述多副本非原子写的tlb作废操作实现装置中,tlb作废响应计数器由来自处理器核请求队列的tlb作废请求进行初始化,tlb作废处理模块在接收到本地ca发出的tlb作废请求时,将tlb作废响应计数器初始化为m*(n+k),m为ca的数量,n为ha的数量,k为ia的数量,且
13、当接收到来自处理器核请求队列的tlb作废拒绝请求时,tlb作废响应计数器减n+k;
14、接收到来自响应通道过滤器的tlb作废拒绝响应消息时,tlb作废响应计数器减n+k;
15、接收到来自响应通道过滤器的tlb作废完成响应消息时,tlb作废响应计数器减1。
16、一种多副本非原子写的tlb作废操作实现方法,包括以下步骤:
17、s1.tlb作废处理模块在接收到本地ca发出的tlb作废请求时,
18、初始化tlb作废响应计数器,
19、通过请求通道向所有其它tlb作废处理模块广播tlb作废请求消息,
20、向本地ca发送tlb作废监听请求;
21、s2.各tlb作废处理模块接收到来自片上互连网络的tlb作废请求消息后,分别向各自本地的ca发送tlb作废监听请求;
22、s3.每个ca在接收到tlb作废监听请求时,将tlb相关表项作废,并等待前序写访问请求发送完毕,随后通过请求通道向所有存储一致性点ha和ia广播tlb作废完成请求消息;
23、s4.ha和ia在接收到作废完成请求消息后,向发起tlb作废请求的源tlb作废处理模块返回tlb作废完成响应;
24、s5.每接收到一个tlb作废完成响应,源tlb作废处理模块的tlb作废响应计数器记一次数,直到收齐所有tlb作废完成响应,向本地ca返回tlb作废完成响应。
25、在上述的多副本非原子写的tlb作废操作实现方法中,步骤s1中,初始化tlb作废响应计数器的值为m*(n+k),m为ca的数量,n为ha的数量,k为ia的数量;
26、步骤s5中,每接收到一个tlb作废完成响应,源tlb作废处理模块的tlb作废响应计数器减1,如果减操作执行完毕之后tlb作废响应计数器为零,则认为已收齐所有tlb作废完成响应。
27、在上述的多副本非原子写的tlb作废操作实现方法中,步骤s2中,当ca收到tlb作废监听请求时,如果ca判断到从未使用过与该tlb作废监听请求相对应的虚地址到物理地址的映射关系,则不进行tlb相关表项作废操作,直接通过响应通道向源tlb作废处理模块返回tlb作废拒绝响应。
28、在上述的多副本非原子写的tlb作废操作实现方法中,步骤s3中,当ca接收到相应tlb作废处理模块发出的监听请求时,检测该请求是否为tlb作废监听请求;
29、若是,继续判断是否使用了该tlb监听请求对应的虚地址到物理地址的映射关系,若是,则作废对应tlb表项,等待前序写访问请求全部发送完毕之后,发送tlb作废完成请求至tlb作废处理模块;若否,则发送tlb作废拒绝请求到tlb作废处理模块;
30、若该请求不是tlb作废监听请求,则按原来的cache一致性协议处理该请求。
31、在上述的多副本非原子写的tlb作废操作实现方法中,当tlb作废处理模块接收到与之相连的本地ca发出的访问请求时,检测其请求类型;
32、若该请求是tlb作废请求,则对tlb作废响应计数器进行初始化;产生发往本地ca的tlb作废监听请求存入tlb作废监听请求队列,等待调度成功后发送该监听请求至本地ca;产生发往所有其它tlb作废处理模块的tlb作废请求消息,并通过请求通道将tlb作废请求消息发送至片上互连网络;
33、若该请求是tlb作废完成请求,则产生发往所有ha和ia的tlb作废完成请求消息,并通过片上互连网络将tlb作废完成请求消息发送到片上互连网络;
34、若该请求是tlb作废拒绝请求,且tlb作废请求的发起方为本地ca,则将tlb作废响应计数器减n+k,若减操作执行完毕之后tlb作废响应计数器为零,则发送tlb作废完成响应至本地ca;
35、若该请求是tlb作废拒绝请求,且tlb作废请求的发起方不是本地ca,则产生发往源tlb作废处理模块的tlb作废拒绝响应消息,并通过响应通道将tlb作废拒绝响应消息发送至片上互连网络;
36、若是其它请求类型,则通过请求通道将该请求消息发送至片上互连网络。
37、在上述的多副本非原子写的tlb作废操作实现方法中,当tlb作废处理模块接收到来自片上互连网络的响应消息时,检测其响应类型;
38、若该响应为tlb作废拒绝响应消息,则将tlb作废响应计数器减n+k,若该响应为tlb作废完成响应消息,则将tlb作废响应计数器减1,若减操作执行完毕之后tlb作废响应计数器为零,则发送tlb作废完成响应到本地ca;
39、若是其它响应类型,则将该响应发送给本地ca。
40、在上述的多副本非原子写的tlb作废操作实现方法中,当tlb作废处理模块接收到监听消息时,将该消息存入非tlb作废监听请求队列,接收到tlb作废请求消息时,将该消息存入tlb作废监听请求队列,采用公平轮转调度方式从两个队列中选择其中一个请求队列,并将该队列头的监听请求发送到本地ca;
41、当ha或ia接收到来自片上互连网络的请求消息时,若该消息是tlb作废完成请求消息,则向源tlb作废处理模块返回tlb作废完成响应,否则按原来的cache一致性协议处理该请求消息。
42、本发明的优点在于:提供包括三种请求队列、一个tlb作废响应计数器和一个响应通道过滤器的tlb作废处理模块,通过独特的协议流程、处理方法和计数方式确保在tlb作废指令执行完成之时,前序发出的写操作都已真正执行完毕,从而解决了non-mcaw的tlb作废操作的实现问题。通过写操作到达存储一致性点来作为前序写操作的完成标志,同时通过增加两级广播协议流程和tlb作废响应计数器来解决写操作完成标志的判别问题,具有判断结果可靠,且硬件实现开销较小等优点。
- 还没有人留言评论。精彩留言会获得点赞!