混合采样注意力机制的油井效率预测方法
本发明属于油气田智慧开发,具体涉及混合采样注意力机制的油井效率预测方法。
背景技术:
1、随着油气资源的开发和利用,传统的油田开发方式已无法满足当今石油行业的需求,这种仅仅依靠经验和规则进行决策的方式虽然有效但却忽略了数据背后的价值和规律,难以适应快速变化的市场和技术环境。由此油井开发逐渐向智能化方向发展。
2、油井效率是油井开发的关键参数之一,对油井开发的重要性不可低估,通过预测油井效率,可以了解油井的生产能力,进而优化采油过程中的操作和流程。例如,可以根据预测结果来调整注水量、注气量、井筒压力、采油时间等指标,以提高采油效率;同时,通过对油井效率的预测和监测可以帮助避免不必要的安全风险,提高油田的安全性。例如,油井效率的突然下降可能意味着油井内部出现了异常情况,需要采取紧急措施,从而降低可能发生的事故风险。预测油井效率可以帮助石油公司更好地规划采油计划和生产计划,从而在最短的时间内生产最多的石油,并且减少生产成本,从而提高石油公司的经济效益,增加公司的收入和利润。预测油井效率还可以帮助石油公司避免对环境造成不良影响,通过预测结果来避免过度开采和浪费资源,从而减少对环境的影响。总之,油井效率预测工作在提高生产效率、降低成本、保障安全、保护环境等方面都具有重要的意义。
3、油井效率预测技术一般是指利用数据分析和机器学习技术对油井进行性能分析和预测的一种方法。它可以帮助石油工程师和生产运营团队更好地利用数据分析技术来了解和优化油井的生产状况,从而提高产量和降低成本,使决策更加科学和准确。现阶段油井效率预测技术所用的主要方法有:回归分析模型、神经网络模型、支持向量机模型、遗传算法、模糊逻辑技术以及传统的arima时序分析模型等,但是现有预测方法所考虑因素的完整性和准确性较差、鲁棒性较差,从而暴露偏差积累的问题;基于此,我们提出了混合采样注意力机制的油井效率预测方法。
技术实现思路
1、本发明的目的在于针对现有技术的不足之处,提供混合采样注意力机制的油井效率预测方法,解决了现有预测方法所考虑因素的完整性和准确性较差、鲁棒性较差,从而暴露偏差积累的问题。
2、本发明是这样实现的,混合采样注意力机制的油井效率预测方法,具体包括:
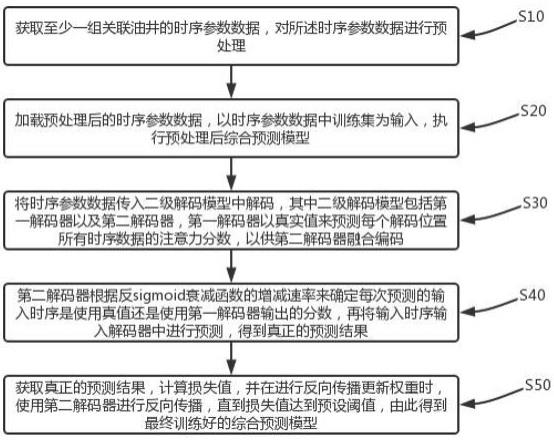
3、获取至少一组关联油井的时序参数数据,对所述时序参数数据进行预处理,其中,所述时序参数数据包括时序日期、动液面、产液量、含水率、油压、套压、沉没度、泵径、泵深、冲程、电压、电流、输入功率、油井效率参数数据;
4、加载预处理后的时序参数数据,将时序参数数据以8:2的比例划分为训练集和验证集,以时序参数数据中训练集为输入,执行预处理后综合预测模型,综合预测模型将有稀疏长尾现象的矩阵进行筛选后再进行缩放内积计算,而后将计算结果在蒸馏层进行下采样后再进入到下一层的计算;
5、获取预处理后的时序参数数据,将时序参数数据传入二级解码模型中解码,其中二级解码模型包括第一解码器以及第二解码器,第一解码器以真实值来预测每个解码位置所有时序数据的注意力分数,以供第二解码器融合编码;
6、第二解码器根据反sigmoid衰减函数的增减速率来确定每次预测的输入时序是使用真值还是使用第一解码器输出的分数,若使用分数则需要进行加权平均混合嵌入,再将输入时序输入解码器中进行预测,得到真正的预测结果。
7、优选地,所述混合采样注意力机制的油井效率预测方法方法,还包括:
8、获取真正的预测结果,计算损失值,并在进行反向传播更新权重时,使用第二解码器进行反向传播,直到损失值达到预设阈值,由此得到最终训练好的综合预测模型。
9、优选地,所述时序参数数据进行预处理包括缺失值处理以及统一编码处理。
10、优选地,在处理缺失值时,找到距离这条数据最近的k个数据点对应所缺失的特征的平均值来进行填补。
11、优选地,统一编码处理包括数据编码、位置编码以及时间戳编码三个部分;
12、其中,数据编码是通过对原始数据进行一维卷积得到,将输入维映射为模型需要的维度,位置编码使用sin和cos函数的线性变换来给各时序数据提供模型位置信息,时间戳编码为加上与时间关联的多组编码,最后将这三者编码结果相加,形成输入的统一编码结果。
13、优选地,所述第一解码器以真实值来预测每个解码位置所有时序数据的注意力分数的方法,具体包括:
14、获取经过整个时序参数数据集编码结果;
15、第一解码器进行标准自回归预测,在编码器和第一解码器交互过程中,编码器提供线性变化之后的矩阵,第一解码器计算得到注意力权重矩阵;
16、通过注意力权重与指定矩阵进行计算得到一个权重向量,同时在第一解码器中加入注意力掩码机制,让二级解码模型在训练过程中掩盖掉当前时刻之后所有位置上的信息,由此获得预测分数。
17、优选地,第一解码器为标准的自回归解码器。
18、优选地,第二解码器根据反sigmoid衰减函数的增减速率来确定每次预测的输入时序是使用真值还是使用第一解码器输出的分数时,为了弥合训练和预测之间的差距,选择反sigmoid衰减时间表来模拟预测任务,进而确定使用真值还是融合值,其曲线公式为:
19、
20、其中,其中k>1,k控制其衰减的幅度,i为训练轮数;
21、如果使用到第一解码器的预测分数,那么就需要进行编码嵌入,混合嵌入采用加权平均混合采样嵌入方式,采用混合方法混合真实值和注意力分数,这里使用含有softmax的混合编码,公式如下:
22、。
23、是将在当前位置使用的向量,为分数,y为真值,为预测值,通过所有时序数据的编码之和以及分数的softmax加权获得;将加权分数后的混合值作为模型中解码器的输入,最终通过全连接层得到最后的预测输出结果。
24、优选地,在处理缺失值时,其中,所述基于欧氏距离的最短距离点被认为是最近邻点的理论,根据缺失值所在数据,计算与其他数据点的加权欧氏距离:
25、
26、其中,i为本次采集的每个数据标识,n为数据总数量,x和y分别为两条计算距离的向量,对缺失值所在数据与其他数据全部计算完成加权欧氏距离后,取距离最近的k个数据点,取它们对应缺失特征的平均值作为填补值。
27、优选地,所述位置编码使用sin和cos函数的线性变换来给各时序数据提供模型位置信息,其编码公式为:
28、
29、
30、其中,pos指的是序列中每条时序数据的位置,i指的是时序向量的维度,dmodel为时序向量维度,分别用上面的sin和cos函数做处理。
31、与现有技术相比,本技术实施例主要有以下有益效果:
32、本发明在综合预测模型的编码阶段中使用稀疏自注意力机制和蒸馏机制,能够有效地对油井效率进行长时序的预测,并且无论是在速度方面还是内存占用方面都有不错的提升;同时,将混合采样思想融入解码器当中,有效减少了训练和预测之间的过大差距(暴露偏差的长时序累积问题),使其准确度更高,预测出的结果更可靠。
33、本发明模型中预测参数方法弥补了传统技术都依赖于预定义的参数的缺陷,可以做到灵活输入输出,更能适应油井领域数据的多变化环境,因而本方法具有较强的普适性。
34、本发明所采用的模型底层使用的是注意力机制,因而无需做特征工程以及在中途做额外的数据处理,相对更方便和高效。
- 还没有人留言评论。精彩留言会获得点赞!