一种数据处理方法、装置、设备及介质与流程
本发明涉及数据处理,尤其涉及一种数据处理方法、装置、设备及介质。
背景技术:
1、spark是目前大数据分布式计算领域最常见、最热门的计算引擎,它完全基于内存进行任务计算,而不用像hadoop的mr一样将中间结果进行落盘,因此,计算性能大大获得了提升。它提供了多种计算算子,同时支持标准sql,让开发者进行大数据编程时更加灵活、开发效率更高。hive是一个基于hadoop的数据仓库工具,提供了类似于关系数据库sql的查询语言——hivesql,用户可以通过hivesql语句快速实现简单的mapreduce统计,hive自身可以自动将hivesql语句快速转换成mapreduce任务进行运行。它主要由hiveserver2和hivemetastore两个服务组成。hiveserver2主要用于接收thrift客户端的基于thrift协议的sql语句请求,并实现了sql语法解析、优化、生成计算引擎执行任务等功能。hivemetastore服务主要用于保存当前hive数仓中已经建立的库、表、字段等的元数据信息。
2、hive on spark是hive社区开发的让hive执行任务基于spark计算引擎进行计算的一种任务执行模式,hive侧(hiveserver2)进行sql语法解析、优化、生成执行任务等工作,spark侧(spark应用)仅根据hive侧生成的执行任务进行计算。
3、目前hive技术主要进行企业级使用,但是无论是hive on mr还是hive on spark的性能,无法满足企业对sql语句执行速度。
技术实现思路
1、本申请实施例提供了一种数据处理方法、装置、设备及介质,用以解决现有技术中hive的使用无法满足企业对sql语句执行速度的问题。
2、第一方面,本申请实施例提供了一种数据处理方法,所述方法包括:
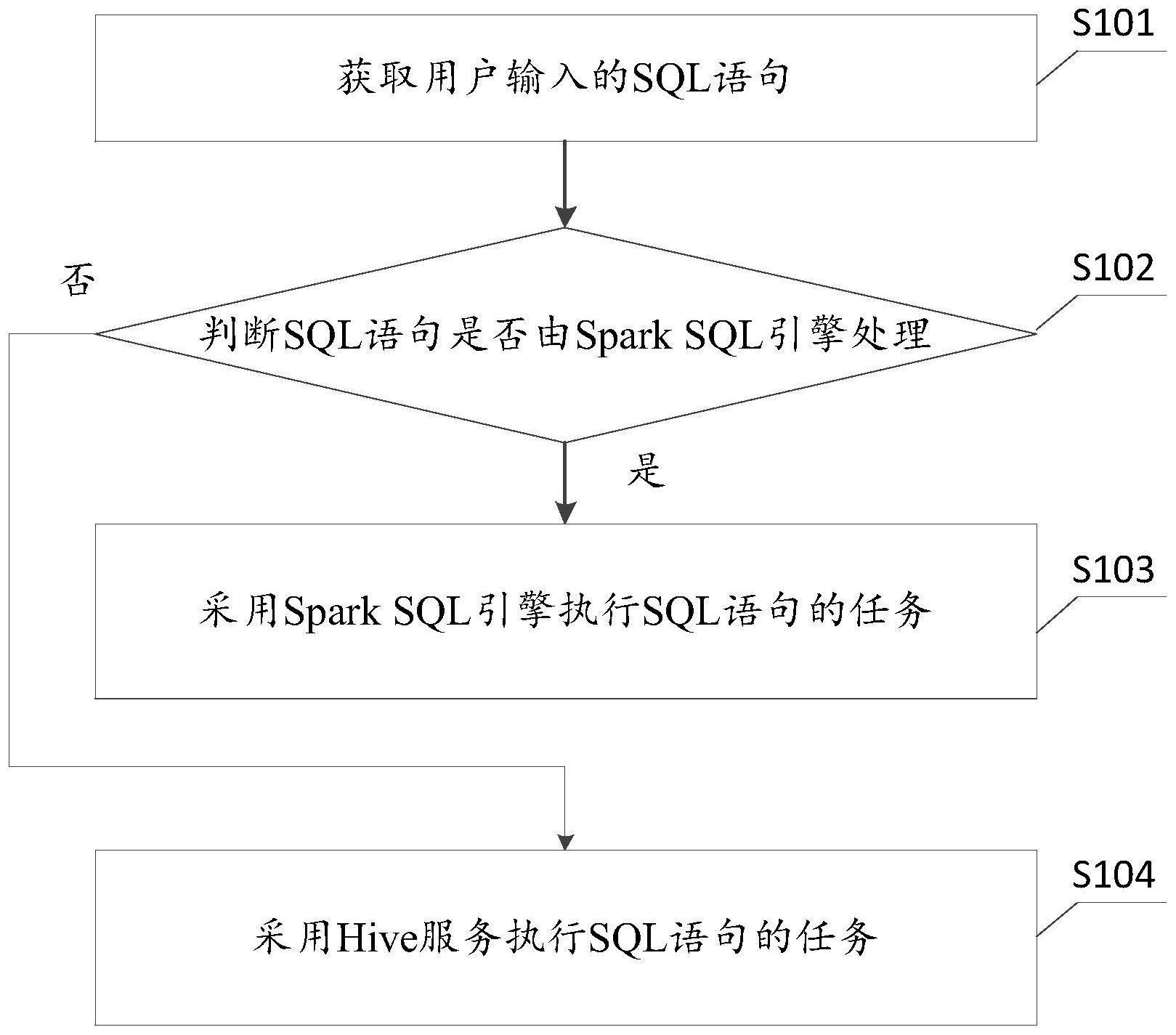
3、获取用户输入的结构化查询语言sql语句;
4、判断所述sql语句是否由spark sql引擎处理;
5、如果是,采用所述spark sql引擎执行所述sql语句的任务;
6、如果否,采用hive服务执行所述sql语句的任务。
7、第二方面,本申请实施例提供了一种数据处理装置,所述装置包括:
8、获取模块,用于获取用户输入的结构化查询语言sql语句;
9、判断模块,用于判断所述sql语句是否由spark sql引擎处理;
10、第一执行模块,用于在所述判断模块的判断结果为是时,采用所述spark sql引擎执行所述sql语句的任务;
11、第二执行模块,用于在所述判断模块的判断结果为否时,采用hive服务执行所述sql语句的任务。
12、第三方面,本申请实施例提供了一种电子设备,所述电子设备至少包括处理器和存储器,所述处理器用于执行存储器中存储的计算机程序时实现如上述任一项所述数据处理方法的步骤。
13、第四方面,本申请实施例提供了一种计算机可读存储介质,其存储有计算机程序,所述计算机程序被处理器执行时实现如上述任一项所述数据处理方法的步骤。
14、在本申请实施例中,获取用户输入的结构化查询语言sql语句;判断所述sql语句是否由spark sql引擎处理;如果是,采用所述spark sql引擎执行所述sql语句的任务;如果否,采用hive服务执行所述sql语句的任务。在该方法中,将hive与spark sql组合使用,保留了hive服务功能的同时,可以使用spark sql的sql语句执行能力,可以提升hive的sql语句执行性能。同时该方法可以兼容hive sql语法和spark sql语法,用户甚至可以不用修改任何sql语句,就可以使用spark sql引擎。
技术特征:
1.一种数据处理方法,其特征在于,所述方法包括:
2.如权利要求1所述的方法,其特征在于,所述判断所述sql语句是否由spark sql引擎处理包括:
3.如权利要求1所述的方法,其特征在于,所述判断所述sql语句是否由spark sql引擎处理包括:
4.如权利要求1-3任一项所述的方法,其特征在于,所述采用所述spark sql引擎执行所述sql语句的任务包括:
5.如权利要求4所述的方法,其特征在于,所述对象属性包括以下一个或多个:访问的数据库信息、存放任务结果的数据表信息、或者任务结果的输出路径。
6.如权利要求1所述的方法,其特征在于,所述采用所述spark sql引擎执行所述sql语句的任务之后,还包括:
7.如权利要求6所述的方法,其特征在于,所述将任务结果的数据类型由所述row类型转换为所述hive服务对应的数据类型包括:
8.一种数据处理装置,其特征在于,所述装置包括:
9.一种电子设备,其特征在于,所述电子设备至少包括处理器和存储器,所述处理器用于执行存储器中存储的计算机程序时实现如权利要求1-7任一项所述的数据处理方法的步骤。
10.一种计算机存储介质,其特征在于,其存储有可由电子设备执行的计算机程序,当所述程序在所述电子设备上运行时,使得所述电子设备执行权利要求1-7任一项所述的数据处理方法的步骤。
技术总结
本申请实施例提供了一种数据处理方法、装置、设备及介质,在该方法中,获取用户输入的结构化查询语言SQL语句;判断所述SQL语句是否由Spark SQL引擎处理;如果是,采用所述Spark SQL引擎执行所述SQL语句的任务;如果否,采用Hive服务执行所述SQL语句的任务。在该方法中,将Hive与Spark SQL组合使用,保留了Hive服务功能的同时,可以使用Spark SQL的SQL语句执行能力,可以提升Hive的SQL语句执行性能。同时该方法可以兼容Hive SQL语法和Spark SQL语法,用户甚至可以不用修改任何SQL语句,就可以使用Spark SQL引擎。
技术研发人员:赵鹏飞,钱浩东,周明伟,李丛
受保护的技术使用者:浙江大华技术股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!