一种应用于动态环境的基于多模态语义框架的SLAM方法及系统
本发明属于智能定位与导航领域,具体涉及一种应用于动态环境的基于多模态语义框架的slam方法及系统。
背景技术:
1、煤矿巷道、采掘工作面、仓储物流等作业区域具有典型的非结构化环境特征,且gnss技术无法直接应用于井下和室内,进而导致煤矿开采时矿难频发,急需机械化换人、自动化减人和提高矿山智能化水平。亟需构建适用于煤矿无人驾驶的自主定位系统方案,解决井下无人驾驶精准定位、姿态感知等问题。如何快速突破视觉、惯导和激光等多信息融合的井下无人驾驶精准感知与定位技术,是实现井下无人驾驶局部自主的关键,故融合视觉、激光雷达和惯性测量单元的slam方法非常重要。大多数slam框架目前基于静止场景的假设,然而现实世界是复杂且动态的,可能因为不能匹配到足够的正确特征导致系统失败。因为小尺度对象、遮挡、运动模糊导致语义分割结果在动态环境下不理想,误差较大。
技术实现思路
1、为了克服上述现有技术的不足,本发明提供了一种应用于动态环境的基于多模态语义框架的slam方法及系统。
2、本发明充分考虑了矿山井巷非结构化及动态的环境特征且gnss技术无法直接运用的因素,由于矿山井巷非结构化环境特征,所以使用多模态融合的方式进行误差补偿,从而使整个系统保持稳定。由于矿山井巷以及仓储物流的动态环境特征,所以在一定情况下,静态地图无法监测物体的移动属性,导致误差较大,但是语义理解可以辅助多模态传感器构建3d动态地图,保证了系统的准确率和实时性。本系统突破了传统slam方法以静态环境假设为前提的局限,可以预知物体(人、汽车、动物等)的可移动属性。共享相似物体知识表示,可实现智能路径规划。通过维护共享知识库,提高slam系统的可扩展性和存储效率。
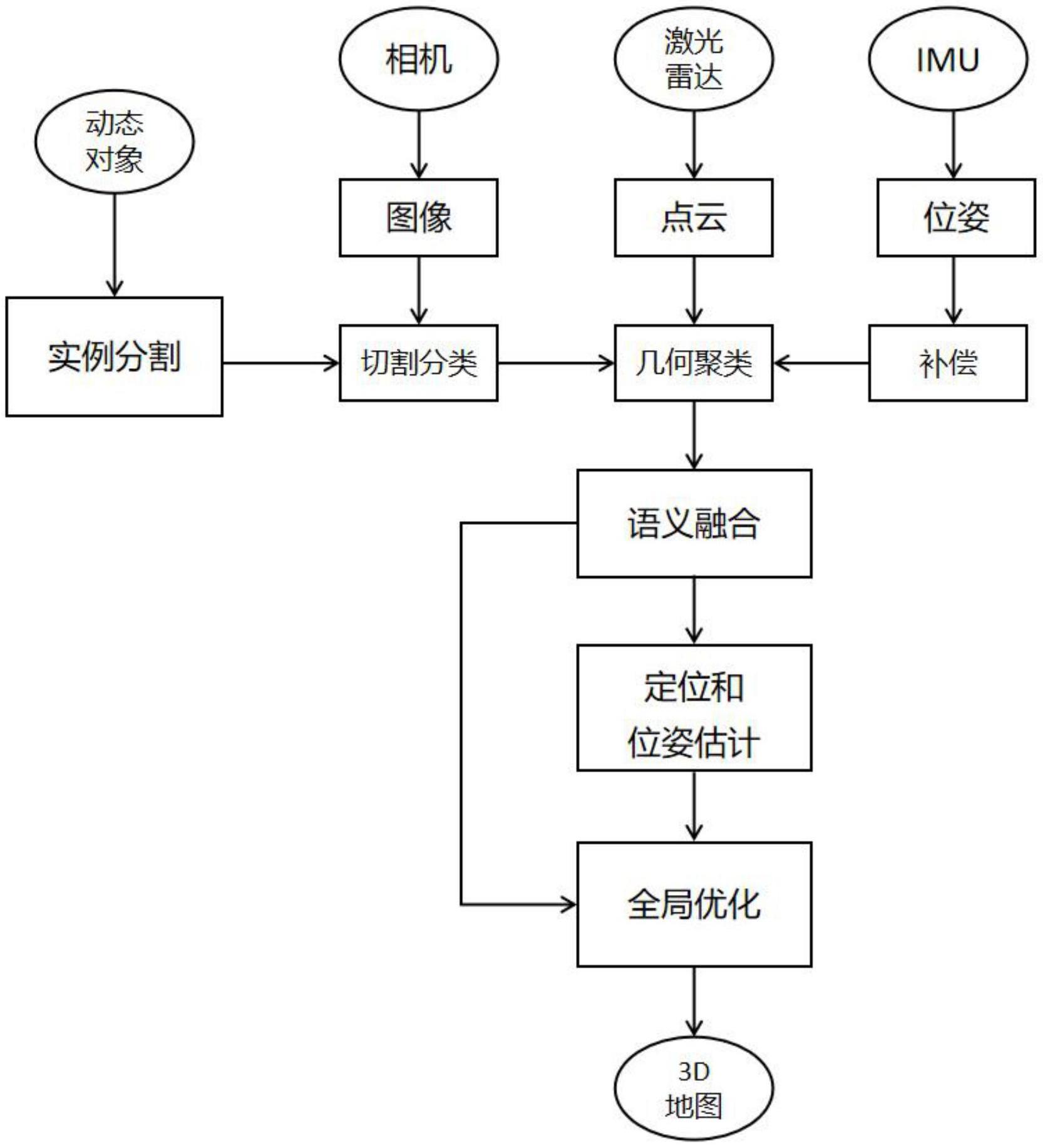
3、本发明所采用的技术方案是:一种应用于动态环境的基于多模态语义框架的slam方法及系统,包括以下步骤:
4、步骤一,通过相机获取图像,提取当前帧的信息,进行切割和分类。
5、步骤二,订阅激光雷达所采集到的原始点云数据。对其进行初步矫正,获取当前帧经过畸变校正之后的有效点云数据、位姿角、初始位姿等信息。进行聚类,检测出障碍物的边缘。
6、步骤三,进行imu预积分,并将结果进行传播。订阅激光和imu里程计,按照之前时刻的激光里程计,距离当前时刻的imu里程计改变增量,进行当前时刻imu里程计的计算;通过rviz来展示局部imu里程计轨迹。通过激光里程计的两帧激光之间的imu预积分构造因子图,优化当前帧的位姿、速度、偏置等状态;将优化后的状态作为基础,添加imu预积分,得到每个时刻的imu里程计。
7、步骤四,实例分割:为多模态信息融合提供实时动态物体分割的语义信息。实现形态膨胀,将动态对象及其边界作为动态信息,结合点云聚类结果和分割结果来更好地细化动态对象。
8、步骤五,多模态信息融合:获取激光雷达的点云信息、相机的连续关键帧信息和惯性导航模组的位姿信息进行融合作为精准的感知信息。
9、步骤六,定位和位姿估计:先后经过特征提取、数据关联、位姿估计等捕捉,通过最小化点到边缘和点到平面的距离及残差的总和来计算最终位姿。通过姿态估计,更新特征地图并选取其中的关键帧。
10、步骤七,全局优化和建图:构建全局语义地图,包括静态地图和动态地图。视觉信息通过将3d点重新投影到图像平面中来实现,同时能够反投影3d点到图像平面。动态地图用于显示动态对象。
11、在步骤一中,包括如下步骤:
12、①订阅当前相机提取到的当前帧的信息;
13、②从当前帧的信息中选取一个像素,根据当前帧的信息采用fast算法检测当前帧的角点,并判断该像素是否为一个角特征点。
14、具体判断方法如下:将所选取像素p的亮度值设为ip,亮度阈值设为t;以像素p点为中心设定一个半径等于3像素的离散化的bresenham圆,bresenham圆的边界上有16个像素;在大小为16个像素的bresenham圆上有9个连续的像素点,若9个连续像素点的像素值大于或小于ip+t,则判定像素p为一个角特征点;若9个连续像素点的像素值等于ip+t,则判定像素不是一个角特征点。
15、在步骤二中,包括如下步骤:
16、①订阅imu采集到的原始数据;订阅imu增量用于位姿估算,当新的imu数据传递进来时,通过之前imu积分数据以及当前得到的数据,预估当前时刻的位姿;订阅激光雷达所采集到的原始点云数据。
17、②默认在激光扫描一帧的时间内仅发生了旋转并没有发生平移,对齐imu数据与时间戳,同时计算imu队列中每帧包括rpy在内的imu积分数据,再对激光帧中的每个扫描点进行线性插值。
18、③发布当前帧经过畸变校正之后的有效点云,发布当前帧经过畸变校正之后的点云数据、位姿角、初始位姿等信息。
19、④进行聚类,检测出障碍物的边缘。具体方法为:找到最近点,只要点与点之间的距离在一定半径范围内就认为这些点属于一个聚类。
20、在步骤三中,包括如下步骤:
21、①对激光里程计数据进行接收,将数据统一为指定格式并且将当前激光里程计的时间戳进行保存。
22、②移除imu队列中时间戳早于激光里程计时间戳的imu增量数据;计算imu队列中起始和终止时刻对应的imu里程计之间的相对位姿变换;将先前接收到激光里程计的数据和之前计算得出的相对位姿变换得到的数据进行结合并发布。
23、③订阅imu原始数据加入到队列中,利用之前时刻优化后得到的结果作为积分的起始值,对imu队列中的数据进行积分计算,发布imu增量。
24、④对于imu角速度和加速度的公式定义如下:
25、角速度:
26、加速度:
27、t时刻下的imu观测源数据为和并且和都会受到白噪声nt和imu零偏bt的影响。矩阵是世界坐标系到机器人坐标系的变换矩阵。重力常数向量g属于世界坐标系w。
28、⑤对系统进行初始化判断;每当接收到100帧的激光里程计数据,优化器就进行一次重置,初始化与重置不同,进行重置时,当前的速度与位姿和之前优化得到的速度与位姿保持一致,噪声模型采用之前优化后模型的边缘分布;添加imu因子,进行imu数据两帧之间的积分计算;添加先验因子,以当前接收到的激光里程计作为先验因子;对变量节点进行赋予初值,执行优化并且更新之前时刻的状态;使用当前优化后的状态对预积分器进行初始化,对当前帧之后的imu数据进行计算。
29、⑥通过imu预积分来获得不同时间戳之间的相对运动。预积分得到的第m和第n时刻之间的位置变化δpmn、速度变化δvmn和旋转变化δrmn计算公式如下:
30、
31、
32、在步骤四中,包括如下步骤:
33、①使用2d实例分割网络,一张图像的实例分割结果为:
34、
35、c代表类别,m是物体的掩码信息,n代表当前图像中存在物体数量。图像在空间上被分成n×n个网格单元。如果一个对象的中心落入一个网格单元,该网格单元负责分别预测类别分支bc和掩码分支pm中对象的语义类别cij和语义掩码mij:
36、bc(i,θc):i→{cij∈rλ|i,j=0,1,...,n},
37、pm(i,θm):i→{mij∈rφ|i,j=0,1,...,n},
38、λ是类的数量。φ是网格单元的总数。
39、②采用solov2的轻量级版本,实现实时实例分割。在骨干网络中构建更有效和更健壮的特征表示鉴别器:输出每个动态对象的像素级实例掩码,以及它们对应的边界框和类类型。输出二进制掩码转换为包含场景中所有像素级实例掩码的单个图像。蒙版落在其上的像素被认为是“动态状态”,否则被认为是“静态”。然后将二进制掩码应用于语义融合模块以生成3d动态掩码。
40、在步骤五中,包括如下步骤:
41、①首先实现形态膨胀,将2d像素级掩模图像与结构元素进行卷积,以逐渐扩展动态对象的区域边界。形态膨胀结果标志着动态对象周围的模糊边界。将动态对象及其边界作为动态信息,将在多模态融合部分进一步细化。
42、②通过欧几里得空间的连通性分析进行补偿。结合点云聚类结果和分割结果来更好地细化动态对象。对几何信息进行连通性分析,并与基于视觉的分割结果合并。
43、③首先将3d点云缩小以减少数据规模,并将其用作点云聚类的输入。然后将实例分割结果投影到点云坐标上,对每个点进行标注。当大多数点(90%)是动态标记点时,点云簇将被视为动态簇。当静态点靠近动态点簇时,它会被重新标记为动态标签。并且当附近没有动态点聚类时,动态点将被重新标记。
44、在步骤六中,包括如下步骤:
45、①特征提取:多模态动态分割后,点云分为动态点云pd和静态点云ps。静态点云用于定位和建图模块,对于每个静态点pk∈ps,在欧几里得空间中通过半径搜索来搜索其附近的静态点集sk。让|s|是集合s的基数,因此局部平滑度定义为:
46、
47、边缘特征由σk大的点定义,平面特征由σk小的点定义。
48、②数据关联:
49、通过最小化点到边缘和点到平面的距离来计算最终位姿。对于边缘特征点pε∈pε,通过将其转换为局部地图坐标,其中t∈se是当前位姿。从局部边缘特征图中搜索2个最近的边缘特征和点到边缘残差定义:
50、
51、给定一个平面特征点pι∈pι及其变换点从局部平面图中搜索3个最近点。点到平面残差定义为:
52、
53、③位姿估计:通过最小化点到平面和点到边缘残差的总和来计算最终的位姿。
54、
55、④特征地图更新和关键帧选择:位姿优化完毕,将特征点更新到局部地图和平面地图中。这些点将被用于下一帧的数据关联。当平移或者旋转的值大于阈值时候,该帧将被选作关键帧。
56、在步骤七中,包括如下步骤:
57、全局语义地图由静态地图和动态地图构成。
58、①静态地图:视觉信息用于构建彩色密集静态地图。通过将3d点重新投影到图像平面中来实现视觉信息。视觉信息能够反投影3d点到图像平面。
59、②每次更新后,使用3d体素化网格方法(3d voxelized grid approach)对地图进行下采样,以防止内存溢出。具体方式为:pcl实现的voxelgrid类通过输入的点云数据创建一系列三维的体素栅格,即微小的空间三维立方体的集合,然后在每一个体素中用这个体素栅格内所有点的重心来近似的显示体素中的其他点。
60、③由pd构建动态地图,用于显示动态对象。动态信息可用于运动规划等高级任务。
61、与现有技术相比,本发明的有益效果是:
62、1.本发明采用激光雷达、视觉相机和imu对煤矿井下和智能仓储系统实现高精准定位,并提高对非结构化环境的姿态感知,由此实现对煤矿井下和智能仓储系统进行高精度定位,同时平衡了精度与计算量,提高矿山井巷的和仓库的定位与建图准确率与实时性,有效的解决了非结构化环境特征下且gnss无法作用的井下定位与建图难的问题。
63、2.本发明提出了一个强大且快速的多模态语义slam框架,旨在解决复杂和动态环境中的slam问题。将仅几何聚类和视觉语义信息相结合,以减少由于小尺度对象、遮挡和运动模糊导致的分割误差的影响。学习更强大的对象特征表示,并将三思机制部署到主干网络,从而为实例分割模型带来更好的识别结果,能够提供可靠的定位和语义密集的地图。
- 还没有人留言评论。精彩留言会获得点赞!