一种基于知识图谱的化妆品不良事件分级预警方法及系统
本发明涉及分级预警,具体涉及一种基于知识图谱的化妆品不良事件分级预警的方法及系统。
背景技术:
1、智能分级预警是将最新的大数据技术运用在社会中各个关键位置,以提高预警能力,达到提高预警质量的效果。在社会运转过程中有很多需要关注的事件,对实时发生的事件进行评级,并对超过阈值的事件进行预警已经是必不可少的工作。而随着数据大爆炸时代的来临,单纯通过人力来收集,甄别事件已经不可取,越来越多的行业使用人工智能技术来挖掘数据并进行分类,预警(如水利部门通过监察设备实时监控降雨量等信息,对即将超过,已经超过安全阈值的河段,地区进行不同级别的预警)。
2、目前化妆品不良事件的发生愈演愈烈,化妆品市场鱼龙混杂,无法有效甄别各种化妆品是否有过由于质量问题导致的不良事件以及不良事件的程度。大多数记录了不良、违规的化妆品信息都是零散存在于网络之中,这导致难以对化妆品的不良事件进行分级并预警,所以需要一个能收集信息并准确分析进行分级预警的方法。
3、近年来,随着大数据技术的发展,爬虫技术日渐成熟,可以在单位时间内爬取更多的高质量数据,所以利用爬虫来获取万维网中所需信息已成为获取信息的主要方式。将爬虫技术和知识图谱技术相结合,利用爬虫所获取的信息来构建知识图谱并进行语义情感分析,可以提高分级预警能力。再经过模型学习以及训练后,可以使系统的分级预警更加精准。
4、自然语言处理(nlp,natural language processing)技术计算机科学领域与人工智能领域中的一个重要方向。其中情感分析是重要的应用方向,它利用算法来分析提取文本中表达的情感。例如分析一个句子表达的好、中、坏等判断,高兴、悲伤、愤怒等情绪。如果能将这种文字转为情感的操作让计算机自动完成,可以节省了大量的时间。对于目前的海量文本数据来说,这是非常必要的。
5、由于互联网上公开可用的信息不断增长,在评论网站、论坛、博客和社交媒体中,可以获得大量表达意见的文本。在情感分析系统的帮助下,这种非结构化信息可以自动转换为结构化数据,关于产品、服务、品牌或人们可以表达意见的其他主题。这些数据对于商业应用非常有用,例如营销分析、公共关系、产品评论、网络发起人评分、产品反馈和客户服务。
6、知识图谱(knowledge graph,kg)是2010年由谷歌团队提出的语义知识库,它是人工智能技术的重要分支技术。知识图谱以符号形式来描述现实世界中的各种概念以及相互关系。它以实体和实体之间的关系的形式为信息来进行建模,遵循rdf(resourcedescription framework)标准,其中(主语,谓语,宾语)三元组是最常用的表达形式,其中主语和谓语是构建的实体,谓语表示它们之间的关系。通过组合多个三元组来构成多重图,其中节点表示实体(所有主题和对象),有向边表示实体间的关系。边的方向指示实体是作为主体还是作为对象出现,即边的指向是从主体到对象的方向。通过不同类型的边(边标签)表示不同的关系。这种结构就被称为知识图(kg),有时也称为异构信息网络。
7、在知识图谱出现之前,人工智能还处于感知智能阶段。感知阶段是指web 2.0产生的海量数据为机器学习和深度学习技术提供了大量标注数据,而gpu和cpu的算力增长,云计算技术的飞速发展为机器学习和深度学习的复杂数值计算提供了必要条件。机器学习和深度学习技术在语音、图像、交通领域均取得了突破性的进展,学习技术成果使得机器在感知能力上达到甚至超越了人类的水平,由此人工智能迈向了感知智能阶段。但深度学习的局限性也越发明显,主要表现在四个方面:第一点缺乏可解释性,由于它是端到端的黑盒模式使得很多模型不可解释,需要人参与决策,尤其是医疗诊断和金融投资方面;第二点常识缺失,特征数据的抽取缺乏关联逻辑,丧失了人类日常活动所需要的大量常识背景知识支持;第三点缺乏语义理解,模型并不了解数据中的语义知识,缺乏推理总结能力,对未知的数据模型泛化能力差;第四点依赖大量样本数据,大多数模型需要大量已标注数据来进行训练。而知识图谱的出现让人工智能由感知智能阶段迈向了认知智能阶段。在这个阶段,人工智能的计算能力逐渐从数据计算转化为知识计算,使机器拥有推理和总结能力,模型可以利用先验知识总结出人可以理解的、模型可以复用的知识。知识图谱提供一种基于符号语义的模型使用客观概念,实体,实体间的关系来描述现实世界中的关系,不仅增加了可解释性,而且可以为深度学习模型提供先验知识,将机器学习的结果转化为可复用的符号知识累积起来。
8、知识图谱已经成功运用在多个领域并发挥重要作用,国外知名的知识图谱有freebase、dbpedia、cyc、wordnet,国内也有openkg,阿里电商知识图谱、美团知识图谱、xlore(清华大学)等知识图谱。
9、目前,知识图谱在医疗、推荐系统、问答系统都有了成熟的应用,但在化妆品不良事件预警方面缺乏应用方法。而随着社会的发展,各类化妆品层出不穷,不良事件的发生也与日俱增。由于不良事件涉及的产品,公司关系复杂,相关数据难以统计和管理。及时发现,收集化妆品不良信息并进行分级对相关人员来说是困难的。此外,能够高效地对化妆品不良信息进行分级预警对于消费者和相关企业有着较高的意义,对于消费者的权益和健康起到了一定的保护作用。
10、当前化妆品分级预警所面临的问题主要有以下几点:(1)如何有效收集化妆品相关信息,并区分出其中不良信息;(2)如何划分不良事件的等级划分。这一问题同样也是知识图谱的化妆品分级预警所面临的问题,虚假的信息或非不良信息会直接影响不良事件的等级划分,各个等级的划分边界直接影响预警的功能及效率。
11、一般的分级预警系统都是使用已经标注好的数据进行统计分析,需要专门的人员来进行数据的收集、清洗以及标注,极大地增加了人力成本且无法做到实时更新。尤其是在化妆品分级预警中更难进行准确的数据标注,化妆品分级预警系统上线后,还需要专人核对数据进行检测,极大地增加了成本,随着化妆品数据规模的日益增加,这个问题会更加严重。通过利用知识图谱对化妆品不良事件进行分级预警,业界几乎还是空白。因此通过构建化妆品不良事件知识图谱并对化妆品不良事件进行分级预警就显得尤为迫切和重要
技术实现思路
1、有鉴于此,本发明的目的之一是提供一种基于知识图谱的化妆品不良事件分级预警方法,能够克服背景技术中存在的问题;本发明的目的之二是提供一种基于知识图谱的化妆品不良事件分级预警系统;本发明的目的之三是提供了一种计算机可读存储介质。
2、本发明的目的之一是通过以下技术方案实现的:
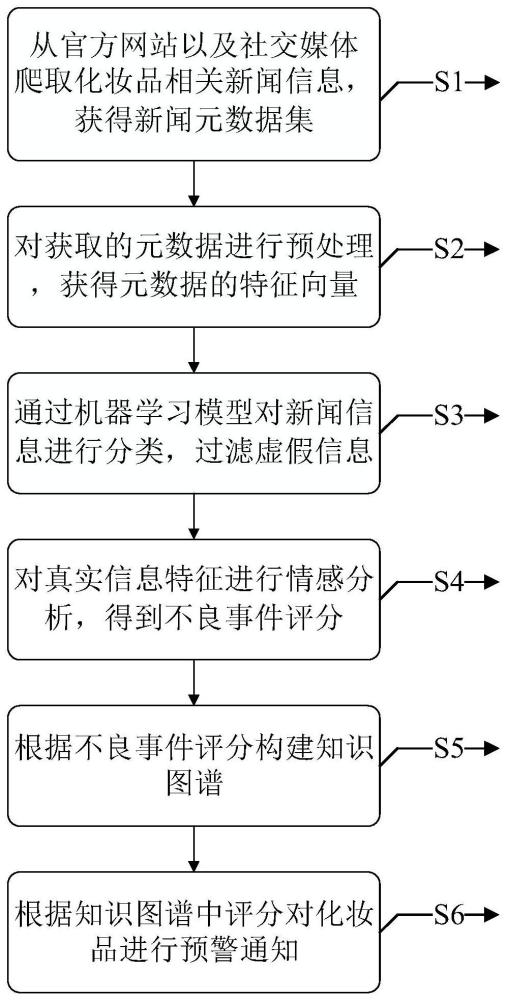
3、一种基于知识图谱的化妆品不良事件分级预警方法,包括以下步骤:
4、步骤s1:通过收集化妆品相关新闻信息,获得新闻元数据集;
5、步骤s2:对获取的元数据进行预处理,获得元数据的特征向量;
6、步骤s3:通过机器学习模型对新闻信息特征进行分类,过滤虚假信息;
7、步骤s4:对真实新闻信息特征进行情感分析,得到不良事件评分;
8、步骤s5:根据不良事件评分构建知识图谱;
9、步骤s6:根据知识图谱中评分对化妆品进行预警通知;
10、进一步,所述步骤s1具体包括:
11、从官方网站以及社交媒体中实时抓取化妆品相关新闻通告信息e∈q,q为新闻数据集,e为单一新闻。
12、进一步,所述步骤s2中,对新闻元数据进行特征提取的公式如下所示:
13、si=bilstm(li)
14、ci=bilstm(bij)
15、fi=wf·tanh(ws·si+(wc·ci)·tanh(cit·wl·si))
16、其中,bi是使用分词模型对获取的新闻e进行分词得到的分词表,i为当前获取新闻数量;bij是在第i个分词表中第j个词;li是使用字典da将bi进行编码获得的向量;si和ci是分别使用双向lstm对词向量进行编码获得正向和反向的句子序列以及单词序列;fi为句子特征,其中wf,ws,wc,wl均为可学习权重参数,其中f为句子特征,s为句子序列,c为单词序列,l用来融合句子序列和单词序列,tanh(·)为激活函数。
17、进一步,所述步骤s3中,通过机器学习模型对新闻信息特征进行分类,过滤虚假信息的训练公式如下所示:
18、y’0=softmax(w·fi+b)
19、lossg=-y’1*log(y’0)-(1-y’1)*log(1-y’0)
20、dis=leakrelu(wdis·y’+bdis)
21、lossd=-dis*log(y’0)-(1-dis)·log(1-y’0)
22、loss=α*lossd+β*lossg
23、其中,y’0为预测输出,y’1为真实标签;dis为鉴别器的一层输出;leakrelu(·)为激活函数;lossg为生成器的交叉熵损失函数;lossd为鉴别器的交叉熵损失函数;loss为模型总损失;wdis和w均为可学习权重参数;bdis和b为分类偏差;α和β分别表示鉴别器损失因子和生成器损失因子,α,β∈(0,1],其中β≥α,因为本发明中生成器损失的影响更大。
24、进一步,所述步骤s4具体包括:
25、步骤s401:获取s3中真实新闻的分词向量bi。
26、步骤s402:对真实新闻的分词向量进行语义情感分析,判断其是否属于不良事件,若为不良事件判断其不良级别并进行存储,其情感分析使用字典相似度进行评估,相似度分数计算公式如下:
27、
28、其中,dc为情感字典,li为分词向量,∑为累加符号。相似度分数从[0,1]每间隔0.2分化为一个等级,共5个等级,将不同t划分到不同的语义情感等级中,5个语义情感等级分别是:轻微不良,轻度不良,中度不良,重度不良,极度不良。
29、进一步,所述步骤s5具体包括:
30、抽取化妆品新闻中的实体,关系,以及不良事件评分,并对化妆品的不良事件即不良等级构建知识图谱。构建知识图谱使用知识图谱的具体构建过程如下:先抽取实体集合,得到e,实体抽取模型采用cnn+crf组成,输入为分词向量c:
31、h=conv(c)
32、y=softmax(h)
33、其中,h为卷积层提取的特征,y={y1,y2,y3,…,yn}为分类后的标签序列,crf概率公式如下:
34、
35、其中,y为标签,h(y1;x)为当前位置输出,g(·)为a-1位置上的标签ya-1转移到ya-1位置上的标签ya的值。然后,对品牌与化妆品关系进行抽取得到关系集合r,将e和r进行融合得到知识图谱图g=(e,r,t),属性t={∑i∈n ti,ei,n表示不良事件的数量}为s4中得到的不良事件ei及其分数ti的集合,即得到了不良事件知识图谱g。
36、进一步,所述步骤s6具体包括:
37、每当知识图谱g中新增了不良事件e∈q或者不良事件分数t∈t进行了改变,需要向平台发布预警信息。当不良事件分数t∈[0,0.4],在系统内弹窗并预警低级别不良事件;当不良事件分数t∈(0.4,0.6],在系统内弹窗并预警中级别不良事件;当不良事件分数t>0.6时,在系统内弹窗并预警高级别不良事件,并向管理人员发送短信预警。
38、本发明的目的之二是通过以下技术方案实现的:
39、一种基于知识图谱的化妆品不良事件分级预警系统,包括存储器、处理器及储存在存储器上并能够在处理器上运行的计算机程序,述处理器执行所述计算机程序时实现如前所述的方法。
40、本发明的目的之三是通过以下技术方案实现的:
41、一种计算机可读存储介质,其上储存有计算机程序,所述计算机程序被处理器执行时实现如前所述的方法。
42、本发明的有益效果是:
43、本发明的方法结合知识图谱的使用减少人工成本消耗,让系统以较低的成本迭代更新,通过深度神经网络来过滤虚假信息,并通过自然语言处理技术对新闻信息进行情感分析获取不良事件等级,根据不同的时间等级发布不同级别的预警,使各类严重的化妆品不良事件都能够得到更准确和可靠的处置,为类似事件的处理提供了一种效果良好,使用便捷可靠的思路。
44、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书和前述的权利要求书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!