面向资源效率优化的服务器无感知计算工作流编排方法
本发明属于云计算领域,特别涉及面向资源效率优化的服务器无感知计算工作流编排方法。
背景技术:
1、近几年来,由于具备对资源和编程的高度抽象、按需使用计费以及动态扩容等优势,服务器无感知计算成为日益流行的云计算开发范式。为实现复杂的实际应用,用户通常以有向无环图的形式将一系列细粒度函数编排成工作流,工作流中定义了函数的顺序以及彼此间的数据依赖。当前主流的服务器无感知计算平台将每个函数部署在单独的沙箱执行环境之中,即一对一的部署模型。当请求到达时,平台需要依次启动各个函数的沙箱,导致严重的级联冷启动开销,甚至远远超出函数本身的执行时间。同时,由于服务器无感知计算的无状态特性和沙箱动态伸缩,ip互不感知的沙箱之间无法建立点对点的直接通信,只能通过第三方的函数编排器或者云存储实现中间数据的传输,进而导致不可忽视的通信开销。此外,一对一的部署模型需要为每个沙箱分配单独的cpu和内存资源,存在较大的资源冗余。因此,如何提高工作流的端到端性能和资源效率,是服务器无感知计算领域的一个重要挑战。
2、为了优化上述问题,现有技术公开了通过将同一个工作流的所有函数部署在同一个沙箱之中,即多对一部署模型。这种多函数复用同一个沙箱的编排方案可以减少冷启动的频率,同时各个函数之间可以通过沙箱内的编排器实现高效的进程间通信,因此一定程度上提升工作流的端到端性能,使得工作流的冷启动和通信延迟得到极大优化。在资源分配方面,cpu可以在不同次序执行的函数间复用,同时多函数共享编程语言运行时和第三方依赖,降低了沙箱间的内存冗余,大大减少了工作流的资源占用。由于常用的python、node.js等编程语言运行时中存在的全局解释器锁不允许多线程同时使用cpu,已有的基于多对一部署模型的编排方法使用多进程执行并行函数。但是,对于当前毫秒级的函数执行延迟,进程的启动开销是不可忽视的,更糟糕的是,进程启动开销随并行度的增加不断变大,甚至超过启动新沙箱的延迟。此外,已有方法为并行的每个函数分配单独的cpu资源,忽略了函数运行时特征,导致了严重的计算资源浪费。
技术实现思路
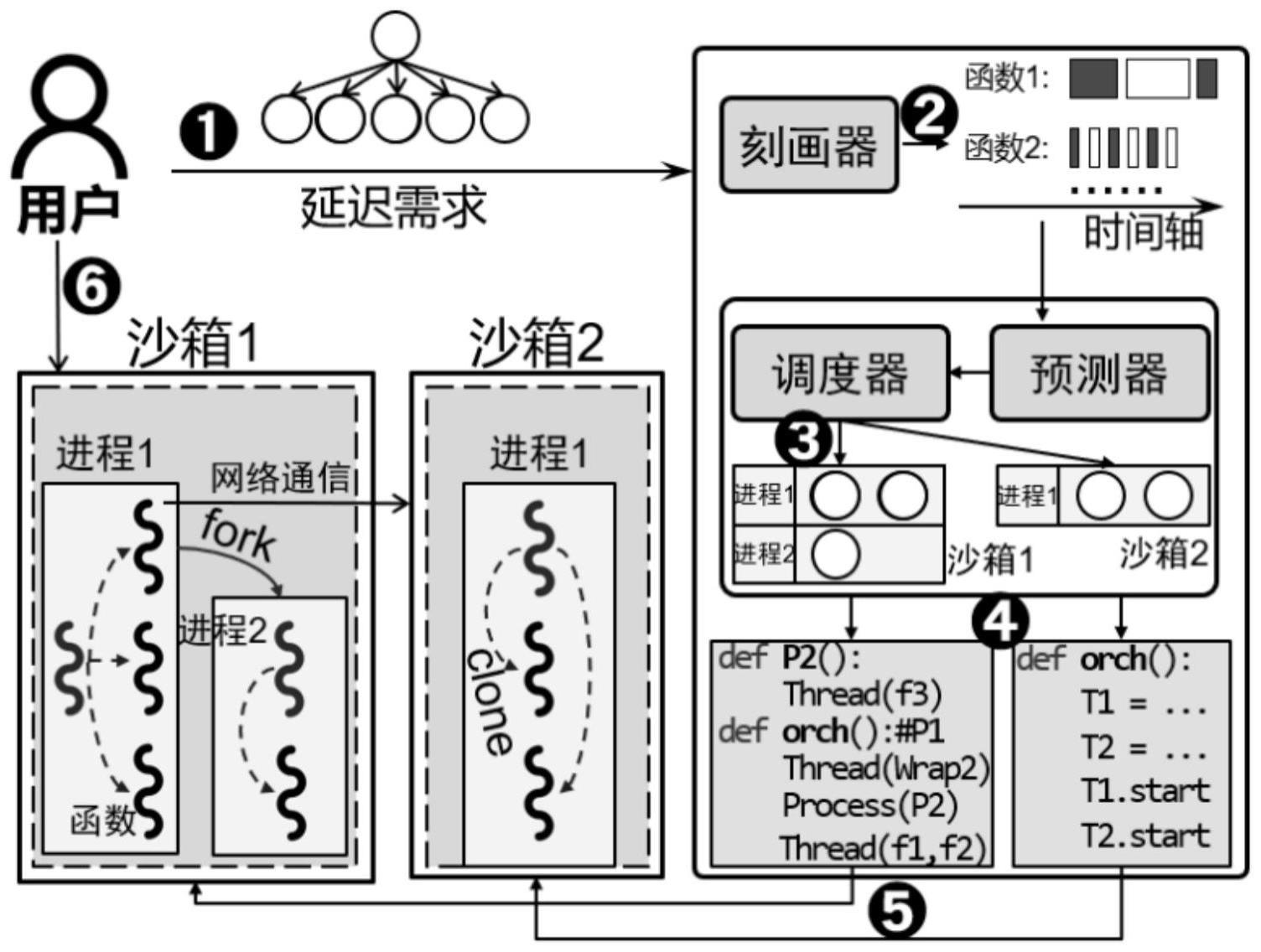
1、针对上述现有技术存在的问题,本发明的目的在于提供了面向资源效率优化的服务器无感知计算工作流编排方法,该方法通过将同一个工作流的所有函数分区部署至多个沙箱中,且每个沙箱内的函数采用混合进线程的形式运行,可在保障用户指定的端到端延迟的同时,实现资源效率的最优分配。
2、为了实现上述目的,本发明采用了以下技术方案:
3、面向资源效率优化的服务器无感知计算工作流编排方法,包括以下步骤:
4、s1、用户端给定工作流的cpu分配资源总量和整体延迟要求;
5、s2、遍历工作流的每个阶段;
6、s3、调度器基于kernighan-lin图分割算法设计启发式算法,探索包括函数分区和混合进线程执行模式在内的最优编排策略,并使用预测器判断所得最优编排策略是否违反给定性能需求;
7、s4、自动生成编排代码,并部署至服务器无感知计算平台上的各个沙箱中。
8、优选地,所述步骤s3中,调度器基于kernighan-lin图分割算法设计启发式算法,探索每个阶段的工作流函数分区的最优编排策略,具体步骤为:首先,调度器将并行的多函数平均分配到给定的n个进程中,即将被分配的函数以多线程形式在同一进程中运行;然后,调度器在确保多进程的创建开销不超过网络通信延迟的基础上确定主沙箱中并行进程的最大数量,而其余沙箱中仅包含一个进程,以此作为初始分区情况;之后调度器使用kernighan-lin图分割算法不断更新每个进程所包含的函数直至预测延迟最小化,获得工作流函数分区的最优编排策略。
9、优选地,所述步骤s3中,调度器采用kernighan-lin图分割算法探索混合进线程执行模式的最优编排策略,具体步骤为:
10、所述步骤s3中,调度器基于kernighan-lin图分割算法设计启发式算法,探索每个阶段的混合进线程执行模式的最优编排策略,具体步骤为:保持每个进程包含的函数不变,调度器首先生成所有进程的两两组合,使用kernighan-lin图分割算法在任意两个进程间不断选择交换后延迟收益最大的函数组合进行交换,直至两个进程不能再产生正收益的函数交换组合,待所有组合遍历完成后,即可获得当前部署方案下的混合进线程执行模式的最优编排策略策略。
11、优选地,所述步骤s3中,使用预测器判断所得最优编排策略是否违反给定工作流的延迟需求,具体步骤为:预测器先使用白盒方法对工作流的端到端的延迟进行建模和预测,再根据延迟预测结果判断当前cpu分配下的最优编排策略是否违反给定工作流的延迟需求。
12、优选地,所述预测器先使用白盒方法对工作流的端到端的延迟进行建模和预测,具体步骤为:
13、由于工作流由多个阶段组成,而每个阶段包含一至多个函数,故工作流的总延迟tworkflow,表示为n个阶段的延迟之和,具体采用下式(1)表示:
14、
15、每个阶段的多个函数被部署至多个沙箱中,而在实际运行中,编排器所在的沙箱需要通过网络调用其余沙箱,因此,每个阶段的延迟取决于沙箱执行时间和调用延迟之和的最大值,具体采用下式(2)表示:
16、
17、其中,表示第i个阶段的第k个沙箱内多函数执行的总延迟;trpc表示通过网络调用其他沙箱的通信开销,设为常量;由于与多个沙箱进行并行通信时会遭遇软件栈开销,使用常数tinv建模线性模型,表示并行调用开销;
18、每个沙箱的延迟可表示最大函数运行时间和进程间通信时间之和,具体采用下式(3)表示:
19、
20、其中,表示第i个阶段的第k个沙箱内的进程集合;表示第i个阶段的第k个沙箱内第j个进程的延迟;tipc表示每次主进程与其他进程通信获取执行结果的开销,这里将tipc设为常量;
21、每个进程的延迟包括等待其他进程创建完成的阻塞时间、启动时间以及内部多线程函数执行总时间三部分,具体采用下式(4)表示:
22、
23、tblock表示每个进程等待上个进程的时间,为常量;tstartup表示进程的启动时间;表示多线程的总执行时间;最后根据预测延迟结果判断所得最优编排策略是否违反给定性能需求,在产生所有阶段的编排方案且延迟之和满足给定性能需求时,调度器在不违反延迟约束的前提下为每个沙箱分配最大允许数量的进程,最终形成包含沙箱函数分区和混合进线程在内的完整编排方案。
24、优选地,所述步骤s4中,自动生成编排代码,并部署至服务器无感知计算平台上的各个沙箱中,具体步骤为:若判断所得最优编排策略不违反给定工作流的延迟需求,则调度器保持每个进程包含的函数不变,按照贪心算法为每个沙箱分配最大允许数量的进程,自动生成编排代码,并部署多函数至服务器无感知计算平台上的各个沙箱中。
25、本发明具备如下有益效果:
26、相比于现有技术,本发明提出了多对多的部署模型,即将同一个工作流的所有函数分区部署到多个沙箱中,同一沙箱内的函数使用混合进线程模型执行以平衡延迟和资源效率。本发明基于全局解释器锁的多线程切换原理和工作流结构设计了工作流的端到端延迟预测模型,以此为基础可以探索低延迟的混合进线程运行方案代替性能和资源效率低下的多进程运行方法。针对庞大的编排方案探索空间,本发明设计了基于图分割算法的启发式算法,在给定初始分区方案后,通过不断交换两两进程间的函数最大化性能收益,最终搜索到包括函数分区和混合进线程策略在内最优编排方案。在调度完成后,自动化生成编排代码并部署至服务器无感知计算平台上,不需要用户参与,有效降低了人工成本。在延迟预测精度上,本发明的预测器的预测误差仅为1.4%-14.2%。在资源分配方面,本发明在保持原有性能的基础上,降低了25.1%-43.4%的cpu资源分配以及22%-5倍的内存分配。在用户付费上,本发明相比已有方法实现了44.4%-95.4%的成本优化。在工作流的端到端延迟保障方面,本发明的延迟违反率相比现有方法进一步降低了88%。
- 还没有人留言评论。精彩留言会获得点赞!