一种基于转置DRAM单元的存内计算电路和装置
本发明属于边缘设备存内计算,更具体地,涉及一种基于转置dram单元的存内计算电路和装置。
背景技术:
1、在资源有限的移动边缘计算设备中,内存计算(computing in memory,cim)是高效执行神经网络等以数据为中心计算的一种方法,被广泛应用于人脸识别、目标检测、可穿戴健康检测等场景。通过将部分运算逻辑嵌入内存架构中,使内存能够完成部分逻辑计算,从而减少算术逻辑单元和存储器之间的数据通信,降低能耗和计算延迟。存内计算可以有效的解决上述存储墙问题,显著提高处深度神经网络(deep neural networks,dnn)的性能。
2、在基于存内计算技术的深度学习算法及模型的硬件实现中,以静态随机存取存储器(static random-access memory,sram)等存储介质的存内计算目前已有方案实现了片上训练功能,但传统sram的六晶体管电路结构带来了面积开销大、需要额外的外围电路支持两项重要问题。相比于非易失性存储器和sram,嵌入式同时动态随机存取存储器(dynamic random-access memory,dram)是一种高密度、工艺成熟、与互补金属氧化物半导体(complementary metal oxide semiconductor,cmos)工艺兼容的存储技术,具有较低的成本,且可以随工艺尺寸缩减实现尺寸缩减。传统的一晶体管/二晶体管/三晶体管结构嵌入式dram单元尺寸相比于同一工艺节点下的sram单元在面积上具有很大优势,且由于同样兼容于cmos逻辑工艺,嵌入式dram更容易实现大规模片上集成。基于上述这些优点,dram从众多嵌入式存储器中脱颖而出,近来已成为学术界和工业界在存内计算领域的研究新热点。
3、虽然dram具有高密度的显著优点,但目前基于dram单元的存内计算暂时无法支持需权重复用的片上训练的过程,导致边缘设备端训练模型仍需花费大量硬件及能量开销。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明提供了一种基于转置dram单元的存内计算电路和装置,其目的在于利用dram单元内晶体管的对称性,通过对dram单元读出端的选择实现阵列内的原位矩阵转置,从而构建能够支持权重复用的片上训练的存内计算电路和装置,由此解决现有dram存储器电路无法支持权重复用的片上训练导致边缘设备资源耗损高的技术问题。
2、为实现上述目的,按照本发明的一个方面,提供了一种基于转置dram单元的存内计算电路,包括:
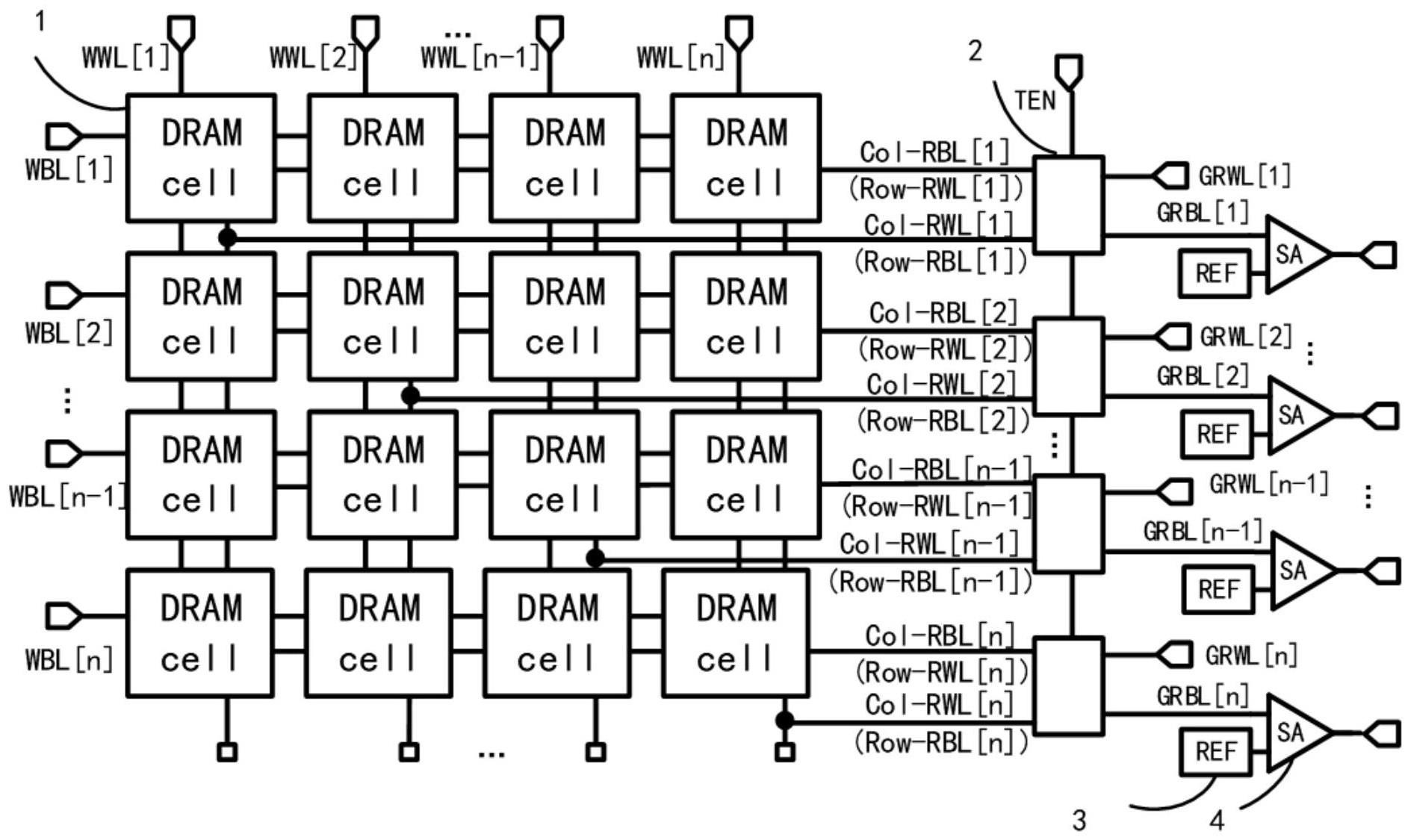
3、存储器阵列,包括n行n列转置动态随机存取内存dram单元;同一列上的所有dram单元共享同一条写字线wwl和列读字线col-rwl;同一行上的所有dram单元共享同一条写位线wbl和列读位线col-rbl;在n列wwl的控制下,n行n列的1-bit数据通过n行wbl写入n行n列dram单元;在非转置的常规读出模式下,通过col-rwl向存储器阵列输入读出控制信号,或,输入一组计算数据,通过col-rbl输出所述存储器阵列中一列的存储结果,或,输出所述存储器阵列中一列的计算结果;在转置的读出模式下,col-rwl被重命名为行读位线row-rbl,col-rbl被重命名为行读字线row-rwl,通过row-rwl输入读出控制信号,或,输入另一组计算数据,通过row-rbl输出所述存储器阵列中一行的存储结果,或,输出所述存储器阵列中一行的计算结果;
4、在其中一个实施例中,所述dram单元包括读出管tr和至少一个写入管tw;
5、n个转置使能开关组,其中,第i个所述转置使能开关组设有与第i行col-rbl又名row-rwl连接的第一端、与第i列col-rwl又名row-rbl连接的第二端、转置使能信号ten输入的控制端、与第i个全局读字线grwl连接的第三端,和与第i个全局读位线grbl连接的第四端,1≤i≤n;n个所述转置使能开关组根据控制端的输入信号将所述第一端和所述第二端的输入选通至第三端和第四端,通过grwl输入读出控制信号,从而使所述grbl输出所述存储器阵列中一列或一行的存储结果,或,输出所述存储器阵列中一列或一行的计算结果,同一行或列上的所有单元可以并行输出存储或计算结果。
6、在其中一个实施例中,所述转置使能开关组包括4个nmos管和4个pmos管;
7、n个灵敏放大器sa电路,与n个所述转置使能开关组的grbl一一对应连接,用于将输入数据与读参考电平的差值进行放大输出,得到所述存储器阵列对应行或列上存储数据或计算结果的电压水平。
8、在其中一个实施例中,所述dram单元的数据存储包括常规读出模式、转置读出模式、写入模式和待机模式。
9、在基于上述电路的基础上,按照本发明的另一方面,提供了一种基于转置dram单元的存内计算装置,包括:控制电路、外围计算电路和至少一个所述的基于转置dram单元的存内计算电路;
10、所述存内计算电路是存内计算装置内的一个存算子阵列,用于计算一组权重数据与另一组输入数据的按位乘法;在控制器的控制下,通过写字线wwl和写位线wbl将一组计算数据存储至对应dram单元,控制器对所述dram单元读出模式进行控制,执行常规或转置模式下的读出或计算;存算子阵列内同一row-rwl或col-rwl所在的一行或一列数据可以并行读出,或输入另一组计算数据,实现与存储计算数据的并行按位乘法计算;多个存内计算电路构成一个存算宏阵列,同一存算宏阵列内的所有存算子阵列间可以并行计算;
11、所述外围计算电路,与存内计算电路中sa电路的输出端连接,用于对存内计算电路的计算结果执行进一步运算;
12、所述控制电路控制存内计算电路中一组权重数据的写入、存内计算电路另一组输入数据向存内计算电路的输入、存内计算电路各个模块的整体运算过程、外围计算电路的运算过程和计算结果的输出。
13、在基于上述存内计算装置的基础上,按照本发明的另一方面,本发明还提供了基于上述存内计算装置的全连接层的正向传播和反向传播过程计算方法,具体包括:
14、基于存内计算装置的全连接层权重数据映射方法,基于所述的存内计算装置,所述基于存内计算装置的全连接层权重数据映射方法包括:将数据位宽为k-bit的h行j列的权重矩阵w按比特位拆分为k个h行j列的1-bit矩阵,将每个h行j列的1-bit矩阵按照行列位置关系映射在一个h行j列的dram存算子阵列中,k个h行j列的dram存算子阵列组成一个dram存算宏阵列,k个存算子阵列间并行计算。
15、基于存内计算装置的全连接层正向传播过程执行方法,基于所述的存内计算装置,其存内计算电路基于所述的全连接层权重数据映射方法将权重数据存储于存内计算电路的dram存算宏阵列中;在神经网络训练过程中对权重矩阵按正向传播时对转置权重矩阵的需求执行模式选择和并行计算,以实现全连接层的正向传播过程,具体包括:将1个数据位宽为k-bit的1行j列输入向量i按比特位拆分,以位串行的方式分时地逐列输入dram存算宏阵列中,其中j列对应j条col-rwl,第i条col-rwl对应输入向量i的第i个元素,1≤i≤j。通过h行的col-rbl完成与存储权重数据的按位乘法运算,并通过sa输出乘法计算结果,在外围计算电路完成移位相加及累加运算,得到1个h行1列的输出向量o;在这一计算模式下,共享同一col-rwl的h个单元之间可以并行计算;且k个存算子阵列间也可以并行计算。
16、基于存内计算装置的全连接层误差计算方法,基于所述的存内计算装置,在神经网络训练过程中对全连接层的正向传播输出向量o执行误差计算,以产生全连接层的反向传播过程的输入向量,具体包括:将h行1列输出向量o在外围计算电路中按照位宽为k-bit量化,并与位宽为k-bit的输出向量预测值o’作差,得到位宽为k-bit的h行1列误差向量δo=o’–o,作为反向传播的输入向量;
17、基于存内计算装置的全连接层反向传播执行方法,基于所述的存内计算装置,其存内计算电路基于所述的全连接层权重数据映射方法将权重数据存储于存内计算电路的dram存算宏阵列中;在神经网络训练过程中对权重矩阵按反向传播时对转置权重矩阵的需求执行模式选择和并行计算,以实现全连接层的反向传播过程,具体包括:基于所述的误差计算方法,计算得到正向传播后误差向量δo为反向传播过程的输入向量;通过转置使能开关组,将输入向量从所述正向传播过程中的col-rwl方向输入,变为反向传播过程中的row-rwl方向输入;通过h行row-rwl按行逐位输入位宽为k-bit的h行1列误差向量δo,其中第i条row-rwl输入误差向量δo的第i个元素,1≤i≤h;通过j列row-rbl完成j个δo向量按位乘法运算,并通过sa输出乘法计算结果,在外围计算电路完成移位相加及累加运算,得到输入误差向量δi;在这一计算模式下,共享同一row-rwl的j个单元之间可以并行计算;且k个存算子阵列间也可以并行计算。
18、在其中一个实施例中,所述存内计算装置首先依据所述基于存内计算装置的全连接层数据映射方法执行全连接层的权重数据映射,然后依据所述基于存内计算装置的全连接层正向传播过程执行方法执行全连接层的正向传播过程,其次依据所述基于存内计算装置的全连接层误差计算方法执行全连接层的正向传播误差计算过程,最后依据所述基于存内计算装置的全连接层反向传播执行方法执行全连接层的反向传播过程。
19、在基于上述存内计算装置的基础上,按照本发明的另一方面,本发明还提供了基于上述存内计算装置的卷积层的正向传播和反向传播过程计算方法,具体包括:
20、基于存内计算装置的卷积核矩阵数据映射方法,基于所述的存内计算装置,所述基于存内计算装置的卷积核矩阵数据映射方法包括:将数据位宽为k-bit,尺寸为m行m列的卷积核矩阵中的元素按照行方向从卷积核矩阵左上到右下的顺序展平为数据位宽为k-bit的m2行1列的数据,然后将展平后的数据按位拆分为k个m2行1列的1-bit数据,将拆分后的数据映射在一个m2行k列的dram存算子阵列中;对于同一卷积层的p个通道,按相同方式映射在p个m2行k列的dram存算子阵列中,p个m2行k列的dram存算子阵列组成一个dram存算宏阵列,p个存算子阵列之间并行计算。
21、基于存内计算装置的卷积层正向传播过程执行方法,基于所述的存内计算装置,其存内计算电路基于所述的卷积核矩阵数据映射方法将卷积核矩阵数据存储于存内计算电路的dram存算宏阵列中;在神经网络训练过程中对卷积核矩阵按正向传播时对转置的需求执行模式选择和并行计算,以实现卷积层的正向传播过程,具体包括:从数据位宽为k-bit的q行q列输入矩阵以步长为1的方式选择数据位宽为k的m行m列的输入矩阵i,其中,m≤q,分别进行下述计算;将输入矩阵i按与卷积核矩阵相同的方式,从矩阵左上到右下的顺序展平为一列数据位宽为k-bit的m2行1列的数据,以位串行的方式分时逐位输入m2行k列的dram存算子阵列的m2行对应的m2条col-rwl,第i条col-rwl对应输入矩阵i的第i个元素,1≤i≤m2;通过k条col-rbl完成权重数据与输入数据的按位乘法运算,并通过sa输出乘法计算结果,在外围计算电路完成移位相加及累加运算,得到输出矩阵o中的一个输出值;重复上述过程,以步长为1从数据位宽为k-bit的q行q列输入矩阵选择不同的m行m列的输入矩阵i,得到输出矩阵o中不同位置的输出值,输出值在输出矩阵o中的行列位置与m行m列的输入矩阵i在q行q列输入矩阵中行列位置相同,最终得到q-m+1行q-m+1列的输出矩阵o;在这一计算模式下,共享同一col-rwl的k个单元之间可以并行计算;且不同通道所在的不同存算子阵列间也可以并行计算。
22、基于存内计算装置的卷积层误差计算方法,基于所述的存内计算装置,在神经网络训练过程中对卷积层的正向传播输出矩阵执行误差计算,以产生卷积层的反向传播过程的输入矩阵,具体包括:将尺寸为q-m+1行q-m+1列的输出矩阵o在外围计算电路中按照位宽为k-bit量化,并与输出矩阵的预测值o’作差,得到位宽为k的q-m+1行q-m+1列误差矩阵δo=o’–o,将其外部补0,扩展为r行r列的误差矩阵,其中r=m+q-1,作为反向传播过程的输入矩阵。
23、基于存内计算装置的卷积层反向传播执行方法,在反向传播模式下,数据位宽为k的尺寸为m行m列的卷积核矩阵在dram存算子阵列中的部署方式与正向传播相同,从数据为宽为k的r行r列的误差矩阵以步长为1的方式选择数据为宽为k的m行m列的误差矩阵δo,按照所述输入矩阵i的展平方式将δo展平为m2列k行数据,第i条col-rwl对应误差矩阵δo展平后的第m2-i列数据,1≤i≤m2;通过k条col-rbl完成误差矩阵δo与卷积核矩阵的按位乘法运算,并通过sa输出乘法计算结果,在外围计算电路完成移位相加及累加运算;在这一计算模式下,共享同一col-rwl的k个单元之间可以并行计算;且不同通道所在的不同存算子阵列间也可以并行计算。
24、在其中一个实施例中,所述存内计算装置首先依据所述基于存内计算装置的卷积核矩阵数据映射方法执行卷积层的卷积核矩阵数据映射,然后依据所述基于存内计算装置的卷积层正向传播过程执行方法执行卷积层的正向传播过程,其次依据所述基于存内计算装置的卷积层误差计算方法执行卷积层的正向传播误差计算过程,最后依据所述基于存内计算装置的卷积层反向传播执行方法执行卷积层的反向传播过程。
25、总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
26、(1)本技术提供的基于转置dram单元的存内计算电路,包括n行n列动态随机存取内存dram单元构成存储器阵列、n个转置使能开关组、n个灵敏放大器sa电路;其填补了基于dram电路阵列实现矩阵原位转置的技术空白,利用dram读出晶体管的对称性,通过对dram读出端的选择,实现了阵列内的原位矩阵转置,能够支持片上训练、推理的存内计算系统的权重复用。
27、(2)本技术提供的存内计算装置充分利用了阵列的并行计算特性,阵列内同一行或同一列数据可以并行读出或计算,阵列间可以并行读出或计算,提高了整体计算的并行度。在实现高准确度、高密度的同时,降低了运算量硬件开销,提高了硬件利用率。同时,利用存储器阵列本身特性,在保持dram阵列存储功能的基础上,完成基于所述存内计算装置的神经网络映射方法。
28、(3)本技术提供的存内计算装置,用以实现神经网络的全连接层计算。能够实现神经网络中全连接层正向、反向传播过程在存内计算装置上的映射,且避免了反向传播计算转置权重矩阵时的重新写入;提升了权重阵列的复用率,降低了数据搬移量;
29、(4)本技术提供的存内计算装置,用以实现神经网络的卷积层计算。能够实现神经网络中卷积层正向、反向传播过程的电路映射,基于卷积层反向传播过程权重矩阵相比于正向传播旋转180°的原理,避免了反向传播计算转置权重矩阵时的重新写入,提升了权重阵列的复用率,降低了数据搬移量。
- 还没有人留言评论。精彩留言会获得点赞!