一种融合连续性特征的单目深度估计方法
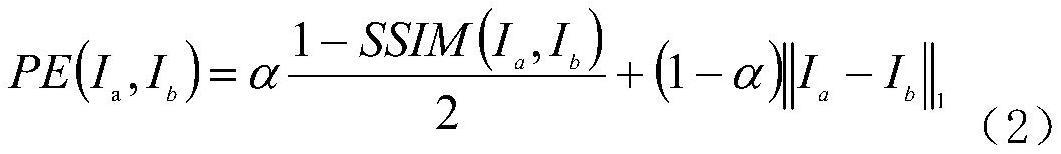
本发明涉及基于深度学习的单目深度估计算法,具体涉及一种融合连续性特征的单目深度估计方法。
背景技术:
1、从图像中估计准确的深度图对于计算机视觉中的很多任务都是一个重要的课题,它对自动驾驶、增强现实以及三维场景重建等应用都起了重要作用。在这些应用中,大多可以采用激光雷达、rgb-d相机等硬件设施来帮助获取深度信息。但是单目视频显然更容易获取,并且不容易因为对硬件设施的干扰而受到影响,维护成本较低。
2、相较于传统的深度估计方法,深度学习的方法已经被证实能够在该项任务上取得更好的结果。典型的是通过最小化预测深度与真实深度之间的误差来估计每个像素的深度,他们大多通过对网络结构以及损失函数的优化来提高深度估计的准确性,比如说使用多尺度卷积网络架构促进深度估计。还有一些工作通过多任务联合语义分割的方式或者通过包含条件随机场(crf)来提高准确性。但是这些方法都是完全监督的,训练时需要大量的标注数据,这显然是昂贵且麻烦的,而自监督的方法使用密集几何约束来消除对深度地面真实值的依赖,通过最小化图像重构误差来训练模型,有效规避了这个问题。garg等人首先提出了在没有深度标签的情况下,使用立体图像对建立深度模型来估计深度的新概念。zhou等人提出的sfmlearner从单目视频中预测深度,并且通过额外的姿态网络来学习相对位姿,这是开创性的工作。随后也有不少工作针对深度估计的一些难点进行优化:godard等人在monodepth2中提出了最小重投影损失来解决遮挡和动态对象问题。
3、然而,现有深度估计相关论文中对图像的特性的解读依旧不是很全面,导致仍然存在深度图中同一深度物体深度不一致,同一物体深度不连续的问题。这受影响于由摄像机的成像原理产生的图像中所处同一深度的像素点不位于同一图像高度问题。
技术实现思路
1、本发明要克服现有技术的上述缺点,提供一种融合连续性特征的单目深度估计方法来进一步提高深度估计精度。
2、本发明的一种融合连续性特征的单目深度估计方法,包括以下步骤:
3、第一步:对原始的三通道彩色图像进行预处理,由原图得到ipim ih三种图像;
4、第二步:将每种处理后的图像输入到特征编码器中,在保持高分辨率特征表示的同时逐渐融合低级特征;对多层卷积提取的特征进行拼接,通过对所有上一阶段小于自身的层数上的特征进行加权求和,得到该阶段特征;
5、第三步:解码器对多层卷积提取的特征进行拼接,对所有该阶段大于等于自身的层数上的特征进行加权求和,得到下一阶段特征;最终输出深度图。
6、1.根据权利要求1所述的融合连续性特征的单目深度估计方法,其特征在于:
7、所述第一步中,im ipih分辨率相同,im由原图通过resize操作获得,将原分辨率为(375,1242)的图转换为分辨率为h×w的图;ip在通过resize操作获得分辨率为h×w的图后,将原图投影到梯形区域;其中梯形的高就是图像宽度,梯形的顶边就是图像长度,梯形的底边边长由比例因子sp控制,与底边的比例在区间[0.7,0.9]内随机选择;ih先通过resize操作得到尺寸为hh×wh的图像,再通过裁剪操作得到分辨率为h×w的图像;其中裁剪窗口与原图比例由比例因子sh控制,在[0.5,0.7]的范围内动态变化。
8、进一步,所述第二步中,编码器包含四个阶段以及四个并行的子网,每个子网的分辨率降低为前一个子网的一半,相应的通道数增加了一倍;第一阶段的的卷积过程包含4个residual unit,每个unit由一个宽度为64的bottleneck组成,bottleneck之后使用一个3×3的卷积操作来降低特征图的通道数,重新变为residual unit输入时的通道数;第二,第三,第四阶段分别包含1、4、3个exchange unit,一个exchange unit包含4个residualunit;在这4个unit后,在每个不同分辨率的转换中都包含两个3×3的卷积;结束第四阶段后,也就得到了编码器的输出,对它使用3×3卷积得到解码器的输入。
9、进一步,所述第二步中,解码器整体上和编码器呈现对称结构,具体不同包括:每个阶段的多尺度融合特征不会融合层数比自己低的层次的特征;在获得了多尺度融合特征后需要进行一次3×3卷积,经过卷积后的特征才可以进入下一阶段;当某特征已经是该阶段最高层时,该层特征只作为输入进入下一阶段;解码器最后的输出在经过一个1×1卷积层后输出深度图。
10、进一步,第三步中使用了组合损失函数进行网络的学习训练,损失函数包含最小光度误差损失、平滑损失、跨尺度一致性损失以及连续性损失;此损失函数组合的表达式为:(其中γμλ为超参数)
11、
12、由于照片中物体无法满足视作漫反射模型--朗伯体模型,损失函数需要考虑光度误差损失:
13、
14、考虑某种情况:当多帧图像中同一位置,其中一帧图像被遮挡物所影响,此时使用平均值来进行处理显然是缺乏严谨的;为了解决遮挡带来的问题,使用最小重投影损失作为光度误差损失:
15、
16、损失函数中,为了只允许在灰度值差异较大的区域的深度差异较大,加入了边缘平滑损失:
17、
18、损失函数中,通过计算连续性损失lmp约束网络显式学习场景的连续性信息:
19、
20、损失函数中,通过计算跨尺度一致性损失lmh约束网络显式学习场景的尺度不变性信息:
21、
22、本发明参照逆透视的方法对图像进行投影,根据本发明方法在原图中选取一块区域作为投影内容,将它投影到与原图相同的形状作为输入,隐性的在网络中加入了连续性信息。受图中物体随深度变化尺度也发生连续变化特性启发,本发明认为尺度信息与连续性信息存在一定关联性,除了原图输入以及投影图像输入外,还加入了一个额外尺度的图像,来帮助网络学习尺度信息。本发明的网络框架采用dual hrnet,它旨在更好的学习多尺度特征信息,并且网络结构较为简单。在损失函数方面,本发明提出了联合连续尺度损失来显式约束网络学习图像的连续信息与尺度信息。
23、本发明的优点是:在保持轻量化的基础上,通过结合尺度不变性与连续性特征,有效提高了深度测量的精度;并且由于其自监督的特性,对数据集的要求低,使得训练门槛低。
技术特征:
1.一种融合连续性特征的单目深度估计方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的融合连续性特征的单目深度估计方法,其特征在于:
3.根据权利要求1所述的融合连续性特征的单目深度估计方法,其特征在于:所述第二步中,编码器包含四个阶段以及四个并行的子网,每个子网的分辨率降低为前一个子网的一半,相应的通道数增加了一倍;第一阶段的的卷积过程包含4个residualunit,每个unit由一个宽度为64的bottleneck组成,bottleneck之后使用一个3×3的卷积操作来降低特征图的通道数,重新变为residualunit输入时的通道数;第二,第三,第四阶段分别包含1、4、3个exchange unit,一个exchange unit包含4个residual unit;在这4个unit后,在每个不同分辨率的转换中都包含两个3×3的卷积;结束第四阶段后,也就得到了编码器的输出,对它使用3×3卷积得到解码器的输入。
4.根据权利要求1所述的融合连续性特征的单目深度估计方法,其特征在于:所述第二步中,解码器整体上和编码器呈现对称结构,具体不同包括:每个阶段的多尺度融合特征不会融合层数比自己低的层次的特征;在获得了多尺度融合特征后需要进行一次3×3卷积,经过卷积后的特征才可以进入下一阶段;当某特征已经是该阶段最高层时,该层特征只作为输入进入下一阶段;解码器最后的输出在经过一个1×1卷积层后输出深度图。
5.根据权利要求1所述的融合连续性特征的单目深度估计方法,其特征在于:第三步中使用组合损失函数进行网络的学习训练,损失函数包含最小光度误差损失、平滑损失、跨尺度一致性损失以及连续性损失;此损失函数组合的表达式为:(其中γμλ为超参数)
技术总结
一种融合连续性特征的单目深度估计方法,包括如下步骤:对原图进行预处理,使图像间存在隐性关系;同时输入三种图像,经过包含四个阶段以及四个尺度不同的并行子网的编码器与解码器,获得深度图输出。其损失函数包含最小光度误差损失、平滑损失、跨尺度一致性损失以及连续性损失。本发明在保持轻量化的基础上,通过结合尺度不变性与连续性特征,有效提高了深度测量的精度;并且由于其自监督的特性,对数据集的要求低,使得训练门槛低。
技术研发人员:毛家发,姚定凯,何政权,胡亚红,产思贤
受保护的技术使用者:浙江工业大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!