基于虚拟形象的语音交互方法及智能终端与流程
本说明书一个或多个实施例涉及电子设备领域,尤其涉及一种基于虚拟形象的语音交互方法及智能终端。
背景技术:
1、当前的智能终端大多支持与用户进行对话,但大多仅能通过语音的形式透出,形态相对单一,使用户的交互体验不高。
2、为了提高用户体验,相关技术引入了虚拟形象,建立三维虚拟人嘴部模型,获取语音信息中每个音素对应的口型模型,建立口型模型序列,从而可以驱动虚拟形象的嘴部动画。由于仅考虑了嘴部动作,使整个虚拟形象不够自然,无法给用户带来自然流畅的对话体验。
技术实现思路
1、有鉴于此,本说明书一个或多个实施例提供一种基于虚拟形象的语音交互方法及智能终端,以解决相关技术中存在的问题。
2、为实现上述目的,本说明书一个或多个实施例提供技术方案如下:
3、根据本说明书一个或多个实施例的第一方面,提出了一种基于虚拟形象的语音交互方法,包括:
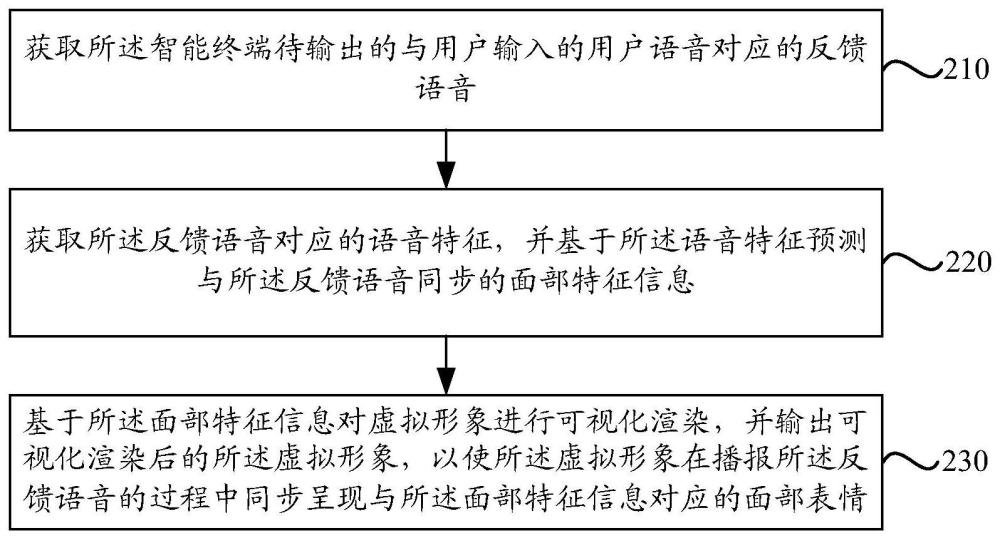
4、获取所述智能终端待输出的与用户输入的用户语音对应的反馈语音;
5、获取所述反馈语音对应的语音特征,并基于所述语音特征预测与所述反馈语音同步的面部特征信息;
6、基于所述面部特征信息对虚拟形象进行可视化渲染,并输出可视化渲染后的所述虚拟形象,以使所述虚拟形象在播报所述反馈语音的过程中同步呈现与所述面部特征信息对应的面部表情。
7、可选的,所述语音特征包括与所述反馈语音对应的文本特征和声学特征;
8、所述基于所述语音特征预测与所述反馈语音同步的面部特征信息,包括:
9、将所述文本特征和所述声学特征作为预测特征输入到预先训练的面部特征预测模型中进行预测计算,得到与所述反馈语音同步的面部特征信息;其中,所述面部特征预测模型为,将从预设的语音播报的视频样本中解析得到的面部特征信息作为训练样本特征,以及将从所述视频样本中解析得到的语音特征作为样本标签,进行有监督训练得到的机器学习模型。
10、可选的,所述方法还包括:
11、对所述反馈语音对应的反馈文本进行语义分析;
12、根据所述语义分析的分析结果,确定与所述反馈语音同步的肢体动作模板和表情模板;
13、所述基于所述面部特征信息对虚拟形象进行可视化渲染,包括:
14、基于所述面部特征信息、所述肢体动作模板和表情模板对虚拟形象进行可视化渲染。
15、可选的,所述根据所述语义分析的分析结果,确定与所述反馈语音同步的肢体动作模板和表情模板;包括:
16、根据所述语义分析的分析结果,分别从肢体动作库中查找与所述分析结果适配的肢体动作模板,以及从表情模板库中查找与所述分析结果适配的表情模板。
17、可选的,所述方法还包括:
18、获取所述虚拟形象的状态信息;
19、基于所述状态信息,确定与所述状态信息对应的肢体动作模板和表情模板;
20、基于所述肢体动作模板和表情模板对虚拟形象进行可视化渲染,并输出可视化渲染后的所述虚拟形象,以使所述虚拟形象呈现与所述肢体动作模板和和表情模板对应的虚拟动画。
21、可选的,所述虚拟形象为2d真人虚拟形象,所述面部特征信息为landmark特征信息;或者,所述虚拟形象为2d卡通虚拟形象或3d虚拟形象,所述面部特征信息为blendshape特征信息。
22、可选的,所述智能终端包括交互屏幕;
23、所述输出可视化渲染后的所述虚拟形象,包括:
24、通过所述交互屏幕输出可视化渲染后的所述虚拟形象。
25、根据本说明书一个或多个实施例的第二方面,提出了一种智能终端,所述智能终端包括交互屏幕,包括:
26、所述智能终端用于获取用户输入的用户语音;
27、所述智能终端还用于向所述用户输出与所述用户语音对应的反馈语音,并通过所述交互屏幕输出面部表情与所述反馈语音同步的虚拟形象;其中,所述虚拟形象为基于与反馈语音同步的面部特征信息进行可视化渲染后输出的,所述面部特征信息为基于与所述反馈语音对应语音特征信息预测得到的。
28、根据本说明书一个或多个实施例的第三方面,提出了一种电子设备,包括:
29、处理器;
30、用于存储处理器可执行指令的存储器;
31、其中,所述处理器通过运行所述可执行指令以实现如第一方面所述的方法。
32、根据本说明书一个或多个实施例的第四方面,提出了一种计算机可读存储介质,其上存储有计算机指令,该指令被处理器执行时实现如第一方面所述方法的步骤。
33、本申请实施例通过获取到的反馈语音的语音特征来预测与反馈语音同步的面部特征信息,再基于面部特征信息对虚拟形象进行可视化渲染,从而使输出的虚拟形象在播报所述反馈语音的过程中同步呈现与所述面部特征信息对应的面部表情,使得输出的虚拟形象能够更加自然得契合反馈语音,给用户带来自然流畅的对话体验。
技术特征:
1.一种基于虚拟形象的语音交互方法,其特征在于,应用于智能终端,包括:
2.根据权利要求1所述的方法,其特征在于,所述语音特征包括与所述反馈语音对应的文本特征和声学特征;
3.根据权利要求1所述的方法,其特征在于,所述方法还包括:
4.根据权利要求3所述的方法,其特征在于,所述根据所述语义分析的分析结果,确定与所述反馈语音同步的肢体动作模板和表情模板;包括:
5.根据权利要求1所述的方法,其特征在于,所述方法还包括:
6.根据权利要求1所述的方法,其特征在于,所述虚拟形象为2d真人虚拟形象,所述面部特征信息为landmark特征信息;或者,所述虚拟形象为2d卡通虚拟形象或3d虚拟形象,所述面部特征信息为blendshape特征信息。
7.根据权利要求1所述的方法,其特征在于,所述智能终端包括交互屏幕;
8.一种智能终端,其特征在于,所述智能终端包括交互屏幕,包括:
9.一种电子设备,其特征在于,包括:
10.一种计算机可读存储介质,其特征在于,其上存储有计算机指令,该指令被处理器执行时实现如权利要求1-7中任一项所述方法的步骤。
技术总结
本说明书一个或多个实施例提供一种基于虚拟形象的语音交互方法及智能终端。该方法包括:获取所述智能终端待输出的与用户输入的用户语音对应的反馈语音;获取所述反馈语音对应的语音特征,并基于所述语音特征预测与所述反馈语音同步的面部特征信息;基于所述面部特征信息对虚拟形象进行可视化渲染,并输出可视化渲染后的所述虚拟形象,以使所述虚拟形象在播报所述反馈语音的过程中同步呈现与所述面部特征信息对应的面部表情。
技术研发人员:吴佳伦,郏友涛,盖于涛,姜飞俊
受保护的技术使用者:浙江艾克斯精灵人工智能科技有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!