一种基于数字人的多视角表情识别方法
本发明涉及图像识别,尤其是涉及一种基于数字人的多视角表情识别方法。
背景技术:
1、面部表情是传达人情感信息的重要手段,有研究表明,在人的日常交流中,通过语言和声音传达的信息分别占7%和38%,而通过面部表情传达的信息占据高达55%。因此,面部表情识别也逐渐成为计算机视觉领域的一个热点问题,准确地识别出人的表情,就能准确把握人的心理和情感,就能更好地为人提供服务。
2、人脸面部表情识别相关领域的研究进展起步较早,但在早期的研究中主要是在心理学和生物学方面。随着近代计算机视觉的发展,利用计算机来进行面部表情识别成为了可能。面部表情识别的基本步骤包括图像预处理、面部特征提取与表情分类。其中又根据面部表情特征表示的不同,分为静态图片人脸表情识别与动态序列人脸表情识别。初期人脸表情识别主要是采用统计学习的传统方法,利用手工特征提取与浅层学习等提取特征;随着计算机硬件的不断发展,深度学习方法在人脸表情识别中也展现了其强大的能力。
3、如何推进面部识别技术更好地应用也是一个重要的课题。技术不能只停留在研究,投入应用才能为人类提供更好地服务。现有常见的基于深度学习的面部表情识别技术是基于数据集进行训练,最终结果取决于数据集和模型的结构。在实验室内采集的数据集上训练得到的模型识别准确率较高,但泛化性较差,在现实生活中应用时也很难再现实验室的环境,难以发挥作用;在采集于真实世界的数据集上训练得到的模型具有一定的泛化性,但是识别准确率较差。而且镜头捕获面部表情的视角的不同也会对表情识别的准确率带来影响,但是现如今拥有多视角的面部表情数据集较少,而且数目不多,这为深度学习的训练带来了很大的困难。
技术实现思路
1、本发明的目的就是为了提供一种基于数字人的多视角表情识别方法,实现小样本表情数据集下的模型训练,并提高真实场景下的表情识别精度。
2、本发明的目的可以通过以下技术方案来实现:
3、一种基于数字人的多视角表情识别方法,包括以下步骤:
4、获取真实世界表情数据集;
5、基于metahuman工具生成多角度下的多种表情的数字虚拟人脸,构建数字人表情数据集;
6、构建角度分类模型用于对输入的图像进行角度分类,并基于数字人表情数据集对角度分类模型进行训练;
7、构建表情分类模型用于将输入的图像分类为不同表情,并固定角度分类模型的网络权重,基于数字人表情数据集和真实世界表情数据集,结合角度分类模型的分类结果训练表情分类模型;
8、基于小样本学习方法,利用训练完成的角度分类模型和表情分类模型的输出,对表情分类模型的网络参数进行调整,得到最优表情分类模型;
9、基于角度分类模型和最优表情分类模型对输入的多视角表情进行识别。
10、生成的数字虚拟人脸包括七个角度的数字虚拟人脸数据,所述角度分别为:0°、15°、30°、45°、60°、75°、90°。
11、生成的数字虚拟人脸包括七种表情,分别为:生气、厌恶、恐惧、高兴、中性、伤心、惊讶。
12、所述数字人表情数据集的构建方法具体为:
13、获取采集于真实世界的表情数据集,将真实表情数据集输入到表情特征提取编码器中,根据其面部表情单元的不同动作编码出当前表情的面部特征组;使用metahuman工具生成具有不同特征的数字人;利用人脸面部表情动作单元,根据面部特征组控制数字人脸上的表情动作单元和识别到的真实世界数据集中的表情动作单元一一对应,在数字人脸上重现出真实世界中人脸的表情,并根据数字人脸的3d特性,旋转数字人的人脸,得到不同角度下的表情图像,为采集到的图像标注上表情和角度信息,生成数字人表情数据集。
14、所述角度分类模型由六层卷积层、三层池化层和一层全连接层组成,输入的图像分别经过三个由两层3×3卷积层和一层全连接层组成的block后,将其展平,得到编码后的长度为864的特征向量,输入到全连接层,经softmax函数激活后输出角度分类结果。
15、所述角度分类结果包括正面、半正面和侧面。
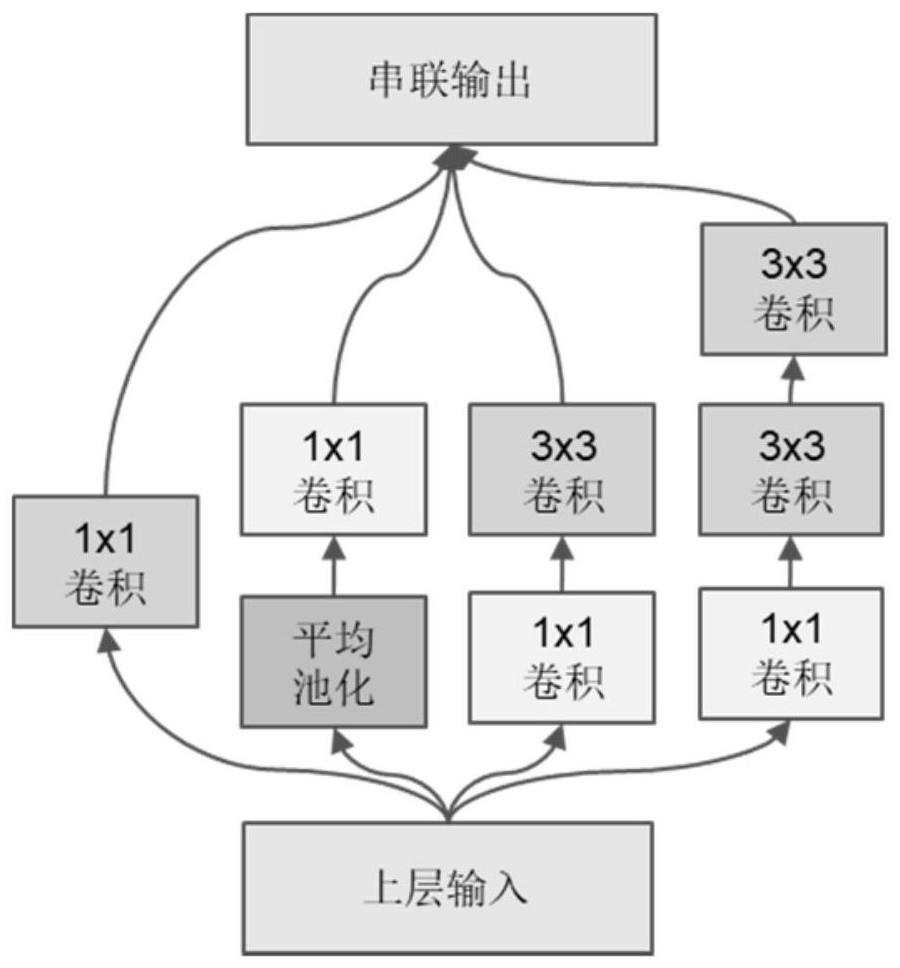
16、所述表情分类模型由五个block组成,输入的图像首先分别经过一层1×1卷积层、一层平均池化层和一层1×1卷积层、一层1×1卷积层和一层3×3卷积层、一层1×1卷积层和两层3×3卷积层,再将这四个输出合并成一个大小为(48,48,384)的张量,输入一个包含两层3×3卷积层和一层全局池化层的block,将其输出与重塑后张量大小为(24,24,1)的角度分类模型识别结果合并成一个大小为(24,24,129)的张量,连续经过三个包含三层3×3的卷积层和一层全局池化层的block,最后将输出的张量展平,得到长度为4608的特征向量,将特征向量输入到全连接层,经softmax函数激活后输出表情分类结果。
17、所述小样本学习方法中,将输入图像经过训练完成的角度分类模型和表情分类模型输出的特征向量进行截取,将其分别输入到余弦距离度量器和欧式距离度量器中,计算距离指标,分别将距离指标与一个尺度因子相乘再进行加和后,经过softmax层,得到最终输出:
18、
19、其中,cos<a,b>和euc<a,b>分别表示a、b之间的余弦距离和欧式距离,fθ(x)表示图像经过表情分类模型输出的特征向量,x为输入图像,wk为距离度量器中全连接层的参数,α、β为尺度因子。
20、所述余弦距离度量器计算的距离指标为:
21、
22、所述欧式距离度量器计算的距离指标为:
23、
24、其中,si,j为计算出的i、j之间的距离指标,wj为距离度量器中全连接层的参数,fθ(xi)为图像经过表情分类模型输出的特征向量,xi为输入的图像。
25、所述角度分类模型和表情分类模型在进行训练时,均使用交叉熵损失函数计算模型输出与真实值之间的损失值,再使用adam优化器对模型中参数进行优化,更新权值,直至得到最优模型。
26、与现有技术相比,本发明具有以下有益效果:
27、(1)本发明使用数字人技术来生成多角度的多表情的人脸图像来进行训练,数字人表情数据集可以大幅改善现有多视角表情数据集数据量小,表情分布不均衡,质量低的问题。
28、(2)本发明的表情识别模型采用一种新设计的条件级联卷积神经网络,结合了角度分类模型和图像分类网络,可以让网络学习到基于角度的表情特征,提高了多视角表情识别性能。
29、(3)本发明使用将数字人多视角数据集和真实世界表情数据集混合起来进行训练的方法,可以增加模型的信息量,提高模型在真实场景中的多视角表情识别准确率。
30、(4)本发明使用小样本学习方法将模型迁移到实际应用场景中,可以将模型在真实场景中快速部署,快速准确地识别场景中多视角的表情。
技术特征:
1.一种基于数字人的多视角表情识别方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于数字人的多视角表情识别方法,其特征在于,生成的数字虚拟人脸包括七个角度的数字虚拟人脸数据,所述角度分别为:0°、15°、30°、45°、60°、75°、90°。
3.根据权利要求1所述的一种基于数字人的多视角表情识别方法,其特征在于,生成的数字虚拟人脸包括七种表情,分别为:生气、厌恶、恐惧、高兴、中性、伤心、惊讶。
4.根据权利要求1所述的一种基于数字人的多视角表情识别方法,其特征在于,所述数字人表情数据集的构建方法具体为:
5.根据权利要求1所述的一种基于数字人的多视角表情识别方法,其特征在于,所述角度分类模型由六层卷积层、三层池化层和一层全连接层组成,输入的图像分别经过三个由两层3×3卷积层和一层全连接层组成的block后,将其展平,得到编码后的长度为864的特征向量,输入到全连接层,经softmax函数激活后输出角度分类结果。
6.根据权利要求5所述的一种基于数字人的多视角表情识别方法,其特征在于,所述角度分类结果包括正面、半正面和侧面。
7.根据权利要求1所述的一种基于数字人的多视角表情识别方法,其特征在于,所述表情分类模型由五个block组成,输入的图像首先分别经过一层1×1卷积层、一层平均池化层和一层1×1卷积层、一层1×1卷积层和一层3×3卷积层、一层1×1卷积层和两层3×3卷积层,再将这四个输出合并成一个大小为(48,48,384)的张量,输入一个包含两层3×3卷积层和一层全局池化层的block,将其输出与重塑后张量大小为(24,24,1)的角度分类模型识别结果合并成一个大小为(24,24,129)的张量,连续经过三个包含三层3×3的卷积层和一层全局池化层的block,最后将输出的张量展平,得到长度为4608的特征向量,将特征向量输入到全连接层,经softmax函数激活后输出表情分类结果。
8.根据权利要求1所述的一种基于数字人的多视角表情识别方法,其特征在于,所述小样本学习方法中,将输入图像经过训练完成的角度分类模型和表情分类模型输出的特征向量进行截取,将其分别输入到余弦距离度量器和欧式距离度量器中,计算距离指标,分别将距离指标与一个尺度因子相乘再进行加和后,经过softmax层,得到最终输出:
9.根据权利要求8所述的一种基于数字人的多视角表情识别方法,其特征在于,所述余弦距离度量器计算的距离指标为:
10.根据权利要求1所述的一种基于数字人的多视角表情识别方法,其特征在于,所述角度分类模型和表情分类模型在进行训练时,均使用交叉熵损失函数计算模型输出与真实值之间的损失值,再使用adam优化器对模型中参数进行优化,更新权值,直至得到最优模型。
技术总结
本发明涉及一种基于数字人的多视角表情识别方法,包括以下步骤:获取真实世界表情数据集;基于MetaHuman工具生成多角度下的多种表情的数字虚拟人脸,构建数字人表情数据集;构建角度分类模型用于对输入的图像进行角度分类;构建表情分类模型,并固定角度分类模型的网络权重,基于数字人表情数据集和真实世界表情数据集,结合角度分类模型的分类结果训练表情分类模型;基于小样本学习方法,利用训练完成的角度分类模型和表情分类模型的输出,对表情分类模型的网络参数进行调整,得到最优表情分类模型;基于角度分类模型和最优表情分类模型对输入的多视角表情进行识别。与现有技术相比,本发明具有真实场景下识别精准等优点。
技术研发人员:蒋烁,刘佳航,何斌,周艳敏,王志鹏,张文博
受保护的技术使用者:同济大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!