一种基于时空注意力机制的动物行为识别方法
本发明涉及智能行为检测,具体涉及一种基于时空注意力机制的动物行为识别方法。
背景技术:
1、当今全球养殖业向规模化、标准化的方向发展,工厂化养殖方式越来越普遍。在工厂化养殖模式下,对牲畜行为的智能检测尤为重要。在动物患病的临床和亚临床体征表现之前,通常会伴有动物自身行为的改变。利用非接触式的计算机视觉技术监控并识别牲畜的异常行为,能减少牲畜病瘦甚至死亡,从而控制经济损失,提高养殖效益。因此,智能行为检测是养殖业迫切需求的一种技术。
2、在计算机视觉方面,智能行为检测的研究主要可以分为基于图像的分析和基于视频的分析两类。基于图像的动物行为分析方法通常研究的是动物的姿态,仅仅以单帧图像作为数据来源,主要有图像分类、区域分类等方法。基于视频的动物行为分析方法不只关注动物行为在单帧图像上的空间位置特征,还考虑了在动作持续时间内图像变化的时序特征,主要有3d卷积模型、双流模型等方法。
3、但是,基于图像的处理方法只能实现静态行为的分类,难以提取动态特征;而基于视频的处理方法仍不成熟,在多类别、空间特征不明显的行为识别任务中准确率低。并且光流估计和3d卷积的计算复杂,计算量大,难以满足实时性要求。
4、综上所述,现有技术主要存在计算量大、准确率低的问题,主要原因有特征提取不全面,模型结构不合理,算法流程过于复杂,视频采集难度大等方面。
技术实现思路
1、本发明的目的在于,提供一种对目标动物视频数据采集,并实现行为识别、目标的检测与分割,从而进行视频分类与识别的动物行为识别方法。
2、为此,本发明采用以下技术方案:
3、一种基于时空注意力机制的动物行为识别方法,包括以下步骤:
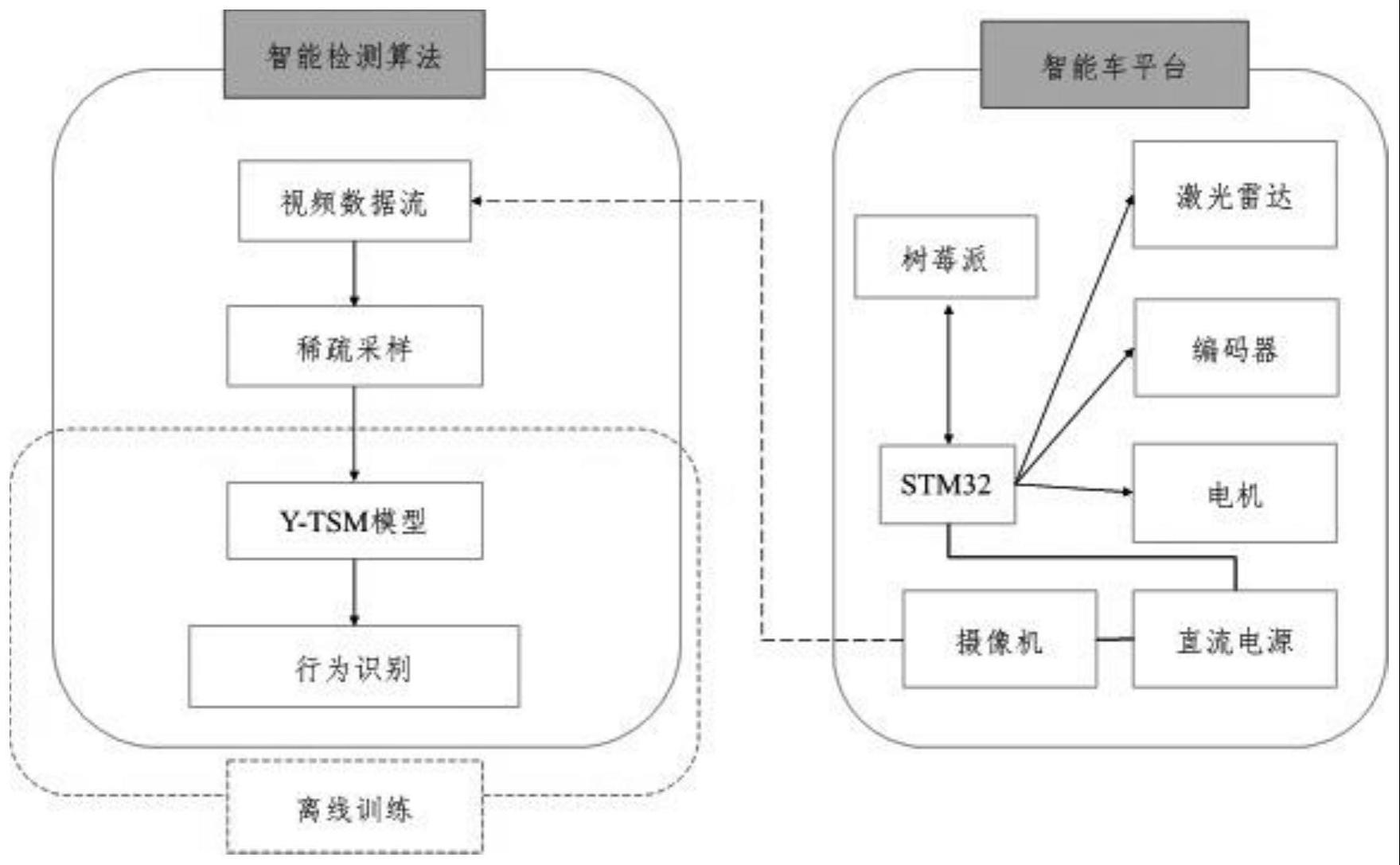
4、(1)利用具备移动检测的硬件平台,采集并记录每个目标动物的视频数据;
5、(2)视频数据通过无线传输至远程主机,首先进行视频图像的稀疏采样,数据由视频流转换为图像序列,然后进行张量拼接与数值标准化等预处理;
6、(3)训练yolov5s模型,检测目标并输出目标回归框的高度、宽度与坐标,分割图像,输出各子图序列;
7、(4)对一条子图序列数据,使用基于时空注意力机制的tsm模型进行特征提取与分类识别,用通道注意力模块增强时序特征,用空间注意力模块增强空间特征,以进行各特征的权重占比的分配,并对改进后的整体模型进行端到端的训练,获得动物行为特征分类结果,训练后的模型用于行为识别实际场景。
8、进一步地:上述步骤(1)中移动检测的硬件平台,包括智能车平台,智能车平台配备目标检测模块、数据处理模块、驱动装置以及摄像机,通过目标检测模块进行目标动物找寻,并经由摄像机进行视频数据录取。
9、进一步地:上述步骤(2)中所述的视频数据经由同一无线网段发送至远程主机,进行均匀采样输出视频帧序列,读取各帧图像,添加时间维度并拼接为张量格式,对各维度值进行z-score数值标准化。
10、进一步地:上述步骤(2)中所述的视频图像稀疏采样,将视频均匀地划分为数个片段,每个片段时长为额定的毫秒时间段,在每个视频片段中随机抽取一帧图像,作为该时段的动物行为图像数据,所有抽取的图像按时间顺序生成序列数据。
11、进一步地:上述步骤(3)中yolov5s模型使用经过数据集训练后的参数,输出目标回归框的高度、宽度与坐标。
12、进一步地:根据回归框分割所有采样得到的图像序列,输出画面内只存在单个目标的子图序列。
13、进一步地:上述步骤(4)中改进后的整体模型采用resnet50作为主干网络,加入tsm模块和cbam注意力模块,包括依次串联的卷积层、最大池化层、第一模块、第二模块、第三模块、第四模块、平均池化层以及全连接层;
14、卷积层使用64个7×7的卷积核,步长为2;
15、最大池化层使用3×3的池化核,步长为2;
16、第一模块使用3个相同的bottleneck串联结构,每个bottleneck包括依次串联的tsm模块、1×1×64卷积层、3×3×64卷积层、1×1×256卷积层;
17、第二模块使用4个相同的bottleneck串联结构,每个bottleneck包括依次串联的tsm模块、通道注意力模块、空间注意力模块、1×1×128卷积层、3×3×128卷积层、1×1×512卷积层;
18、第三模块使用6个相同的bottleneck串联结构,每个bottleneck包括依次串联的tsm模块、通道注意力模块、空间注意力模块、1×1×256卷积层、3×3×256卷积层、1×1×1024卷积层;
19、第四模块使用3个相同的bottleneck串联结构,每个bottleneck包括依次串联的tsm模块、1×1×512卷积层、3×3×512卷积层、1×1×2048卷积层;
20、平均池化层使用7×7的池化核;
21、全连接层配合softmax函数输出分类结果。
22、进一步地:上述步骤(4)中改进模型的tsm模块,包括两条计算路径,一条为主线,将空间特征图直接送入下一层卷积网络;另一条为支线,在时间序列上对部分通道进行移位操作,并用2d卷积提取特征,最后以残差的形式送入下一层;
23、改进模型的cbam注意力模块,包括依次串联的通道注意力模块和空间注意力模块;
24、通道注意力模块,将输入的特征图f(h×w×c)分别送入基于宽度和高度的全局最大池化层和全局平均池化层,得到两个1×1×c的特征向量;将两个特征向量分别送入一个两层的神经网络mlp,第一层神经元个数为c/r,r为减少率,激活函数为relu,第二层神经元个数为c;按通道拼接mlp输出的两个特征向量,经过sigmoid激活函数后生成最终的通道注意力权重,即m_c;最后对m_c和输入特征图f进行基于通道的相乘操作,输出特征图f’;
25、空间注意力模块,输入是通道注意力模块输出的特征图f’:首先进行基于通道的全局最大池化和全局平均池化,得到两个h×w×1的特征图;将这两个特征图按通道拼接,经过一个7×7卷积层,降维为1个通道,即h×w×1;经过sigmoid激活函数后生成空间注意力权重,即m_s;最后将m_s和该模块的输入特征按空间位置做乘法,得到最终生成的特征。
26、进一步地:上述步骤(4)中改进后的整体模型,计算损失函数的公式如下:其中,c是类别总数目,yi表示标签,gi表示视频属于每个类别的得分;
27、
28、上式中,g是融合函数,采用全连接层和softmax函数,输入是在时间序列上采样的各视频帧经过主干网络后的输出,输出是整个视频数据分类为每个类别的概率。
29、与现有技术相比,本发明具有以下有益效果:
30、本发明通过将算法模型与硬件平台相结合,从视频采集、目标检测到行为识别形成完整的体系;同时利用注意力机制合理分配了各特征的权重占比,研究了cbam注意力模块在tsm模型中的最佳嵌入方式,提高了行为识别的准确率。本发明设计的模型结构简洁轻量,较之其他行为识别模型如3d卷积网络和双流模型,计算量小,实时性高。
- 还没有人留言评论。精彩留言会获得点赞!