基于自然语言处理和社交网络的科研成果归属预测方法及系统
本发明属于信息,主要涉及了一种基于自然语言处理和社交网络的科研成果归属预测方法及系统。
背景技术:
1、科研成果主要包括学术论文、发明专利、专著等,成果归属即把科研成果的作者与作者位次进行确定。在科研成果展示系统中,为了展现科研人员的科研学术成果,需要科研人员在成果认领平台认领已经发表的科研成果。但是由于科研成果具有时效性,科研人员通常不会主动认领过去已经不计入考核的科研成果,而历史成果数量众多、类型复杂,也无法通过科研管理人员进行确认,因而,众多的成果归属无法确认,为科研成果的可视化展示和平台后续对成果的分析造成了困难。所以在科研成果展示领域,迫切需要一个能对众多科研成果进行归属预测的方法,能够分析最新的科研成果的归属,为科研人员的成果认领提供智能推荐,也可以预测过去科研成果的数据,用于对成果的展示与分析。
2、现在,学术界越来越多的关注到科研成果归属预测的问题,例如已公开的中国发明专利申请cn114416959a“一种科研成果推送、认领方法及系统”。传统的成果归属预测方法只考虑成果的各类字段与作者的画像是否匹配,通常用科研成果的第一标签匹配作者,匹配不到或者匹配到多个作者的时候再用第二标签匹配作者,以此类推。这种做法的不足之处在于只考虑了科研成果(论文、专利、著作等)的单位、作者名称、期刊类型、成果关键字和科研工作者的单位、名称、关键字是否匹配,而对于科研人员认领成果这个行为本身价值,科研成果先后之间的联系以及科研工作者的合作关系网络没有办法顾及到,这样做的问题在于:
3、1.难以利用科研人员已经认领的成果与潜在成果之间的联系来确认成果的分配。科研人员的研究内容往往随着时间不断演化,同一个科研人员的成果往往不是毫无联系的,时间上相近的成果,研究领域通常较为相似或者具有一定的联系。
4、2.难以利用科研合作者的社交网络中包含的信息。科研成果的产出往往依靠科研人员合作,成果通常会有较多的作者,通过这些科研人员之间合作可以构建出社交网络。在实际合作关系中,往往科研人员之间的合作次数都不止一次,且社交网络呈现出社区化的情况。
5、随着近些年预训练模型在自然语言处理领域的重要进展,使用任务语料对模型进行少许训练即可构建适用的模型。这样通过自然语言处理的文本语义对比方式可以挖掘出科研成果之间的联系,作为科研成果作者分配的影响因素之一;同时,科研人员之间合作关系网络可以作为已经确认其中部分作者的科研成果的其他作者的归属预测的影响因素之一,更加符合科研成果逐步提升更新、群策通力合作的特点。
技术实现思路
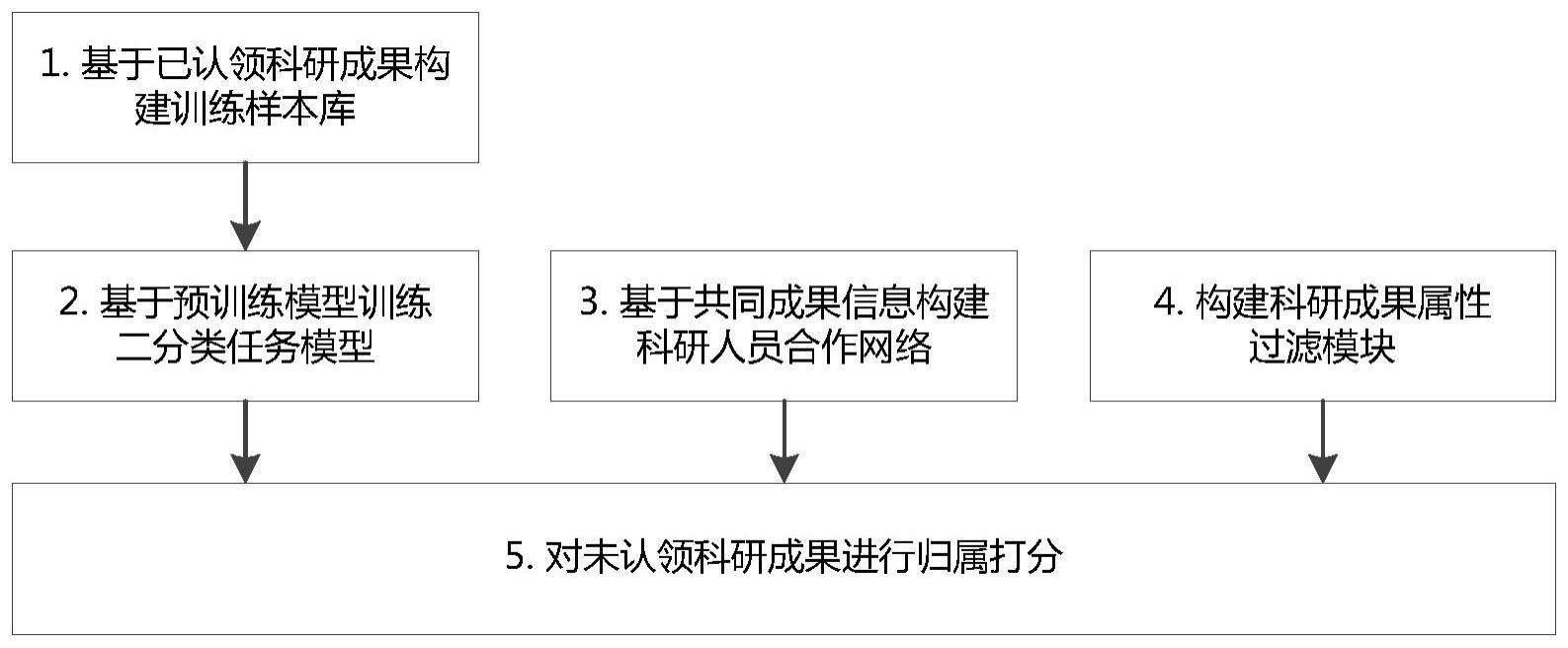
1、本发明正是针对现有技术中科研成果归属预测时未考虑成果时间特征及科研合作关系,匹配特征单一的问题,提供一种基于自然语言处理和社交网络的科研成果归属预测方法及系统,首先,基于现有的科研成果认领平台构建训练样本库,再基于预训练模型训练二分类任务模型,并构建科研人员合作网络,构建科研成果属性过滤模块,最后通过对未认领科研成果进行归属打分的方式完成科研成果的归属预测。本发明能够充分利用科研成果之间的发展关系和科研人员之间合作的信息,更加准确的得到科研成果的归属预测结果,减少人工参与的同时大大提高成果归属预测的准确性。
2、为了实现上述目的,本发明采取的技术方案是:基于自然语言处理和社交网络的科研成果归属预测方法,包括如下步骤:
3、s1,训练样本库建立:基于现有的成果认领平台,为每个已经认领过科研成果的科研人员构建成果集合,所述成果集合中,将同一科研人员的同一类型成果按照时间排序形成列表l;
4、所述列表l中的任一成果p,与该成果p的前列表lbefore、该成果p的后列表lafter共同构成正样本(p,lbefore,lafter);
5、以非同一科研人员的随机成果p′替换成果p,与成果p的前列表lbefore、成果p的后列表lafter共同构成负样本(p′,lbefore,lafter);
6、s2,训练科研人员成果识别模型:将任意成果p是否在某科研人员的成果列表l中定义为一个二分类问题。基于roberta构建科研人员成果识别预训练模型,将步骤s1中的正负样本集中的搜索文本通过tokenizer转换为token,然后将token转换为模型训练输入可以接受的排列格式,输入模型训练,得到科研人员成果识别模型;所述搜索文本至少包括成果关键词和标题。
7、s3:构建科研人员合作网络:将同一科研成果的合作者作为边的两端计算权值,计算所有的科研人员之间的边权值后,得到带权有向科研人员合作网络,其中合作网络的边权值的计算方法为:科研成果p的作者列表,按照参与程度排序为a(p)=[a1,a2,a3,…,an],其中,n表示成果p的作者个数;其中作者ai与aj在成果p中的合作价值为将作者ai与aj在所有合作成果中的价值累加可以得到合作网络中边的权值为:
8、
9、s4:构建成果属性过滤:针对待分配成果p,基于基础属性,排除不匹配的科研人员;所述基础属性至少包括人员姓名、所属单位、发表时间;
10、s5:打分预测:根据科研人员成果识别模型归属概率中位数设定模型推理最低有效值smin;
11、对于仍未被认领的成果,使用步骤s2训练的科研人员成果识别模型,计算集合中候选人对该成果模型推理分数s1,并令集合中候选人对该成果合作归属分数s2为0;
12、对于已被部分合作者认领,但合作者未认领齐全的成果,其中认领的作者记为[a1,a2,a3,…,an],通过步骤s3中构建的科研人员合作网络得到候选人集合m′,使用步骤s2训练的科研人员成果识别模型,计算集合中候选人对该成果模型推理分数s1,集合中候选人对该成果原始合作归属分数其中α为系统参数,将s1高过最低有效值smin候选人员的s2′进行同比例归一化得到合作归属分数s2,使其取值在0到1之间,令s1不高于最低有效值smin候选人员的合作归属分数s2为0;
13、合计s1与s2计算总分stotal,当候选人集合中最高的stotal>smin时,成果将会被归属于stotal最高的候选人。
14、作为本发明的进一步改进,所述步骤s2中,科研人员成果识别预训练模型的构建方法为:使用深度学习框架pytorch加载roberta预训练模型,在roberta模型后添加dropout层和2层全连接层;使用pytorch的sgd优化器来优化参数,交叉熵损失作为损失函数来训练模型。
15、作为本发明的一种改进,所述步骤s1成果集合中的成果类型至少包括论文lpaper、专利lpatent、项目lproject、专著lbook,训练集中的正样本总数量为
16、
17、其中,len()函数表示列表中的成果个数;m表示科研人员个数;
18、所述正负样本的比例为1:10。
19、作为本发明的另一种改进,所述步骤s4中的基本成果属性至少包括成果作者姓名、作者单位和发表时间,其中成果作者姓名和作者单位包括中文和英文。作为本发明的进一步改进,所述步骤s5中,总分stotal的计算方式为:
20、stotal=βs1+(1-β)s2
21、其中β为系统参数。
22、为了实现上述目的,本发明还采取的技术方案是:基于自然语言处理和社交网络的科研成果归属预测系统,包括计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述方法的步骤。
23、与现有技术相比,本发明具有的有益效果:
24、(1)依据社交网络中科研工作者的合作关系价值,提高已经被部分作者认领的科研成果的其他未认领作者预测准确率。科研合作的信息对成果归属预测具有非常大的帮助,科研人员之间往往会形成社区,人员与人员之间的合作也往往不止一次。相较于传统的为科研人员绘制个人画像来预测成果归属的办法,增加社交网络中的合作关系预测成果的归属,结果更加可靠,可解释性也更强。
25、(2)依据科研人员已经认领的成果与潜在成果之间的联系来提高成果预测准确率。传统的模型一是仅仅考虑的科研成果标签与科研人员标签在字面意义上相似,而没有考虑成果的关键词、标题等信息的语义与科研人员的研究领域、研究内容的语义之间的相似性;二是没有考虑到科研成果之间通常在时间上呈现出发展的态势,利用成果发展过程中的变化可以更加好的推断出成果归属于某个研究人员的可能性。本方法采取了从按照时间排序的列表中抽取成果构成样本的方式构建数据集来训练模型,这种做法相比较于传统模型多了对于时间维度的考量。
26、(3)本发明更能够充分利用科研成果的信息,并且可以做到随着新认领记录和新成果的加入持续自动优化模型,本发明在减少人工的参与的同时大大提高成果归属预测的准确性。
- 还没有人留言评论。精彩留言会获得点赞!