基于多方公平的即时配送派单系统
本发明涉及一种订单分配领域,尤其在涉及基于多方公平的即时配送系统。
背景技术:
1、由于外卖服务的蓬勃发展,即时配送平台接受到的订单量正在飞速增加,因此需要一个优秀的订单分派模型来高效地将订单分配给最适合的骑手。由于骑手需要同时负责多个订单的配送,同时在配送途中仍在不断接受新的订单,这使得与订单相关的商家和用户的体验与骑手是否及时配送紧密相关。然而,在当前大部分的派单模型中,都是以平台的利益为唯一考核标准,这使得骑手、商家、用户的公平性都被忽视,有时会带来很糟糕的工作体验和使用体验。为了保障系统的可持续发展和系统中每一个利益方的工作体验,因此,我们需要设计一种系统,不仅仅可以考虑系统效益,还需要考虑参与系统中的每一个利益方的公平性,即骑手、商家和用户的公平性。
技术实现思路
1、为解决上述问题,本发明公开了基于多方公平的即时配送系统,该系统可以帮助他们获得较公平的配送服务体验;最后对于顾客而言,该系统可以确保他们的等单时间控制在最大容忍程度内。
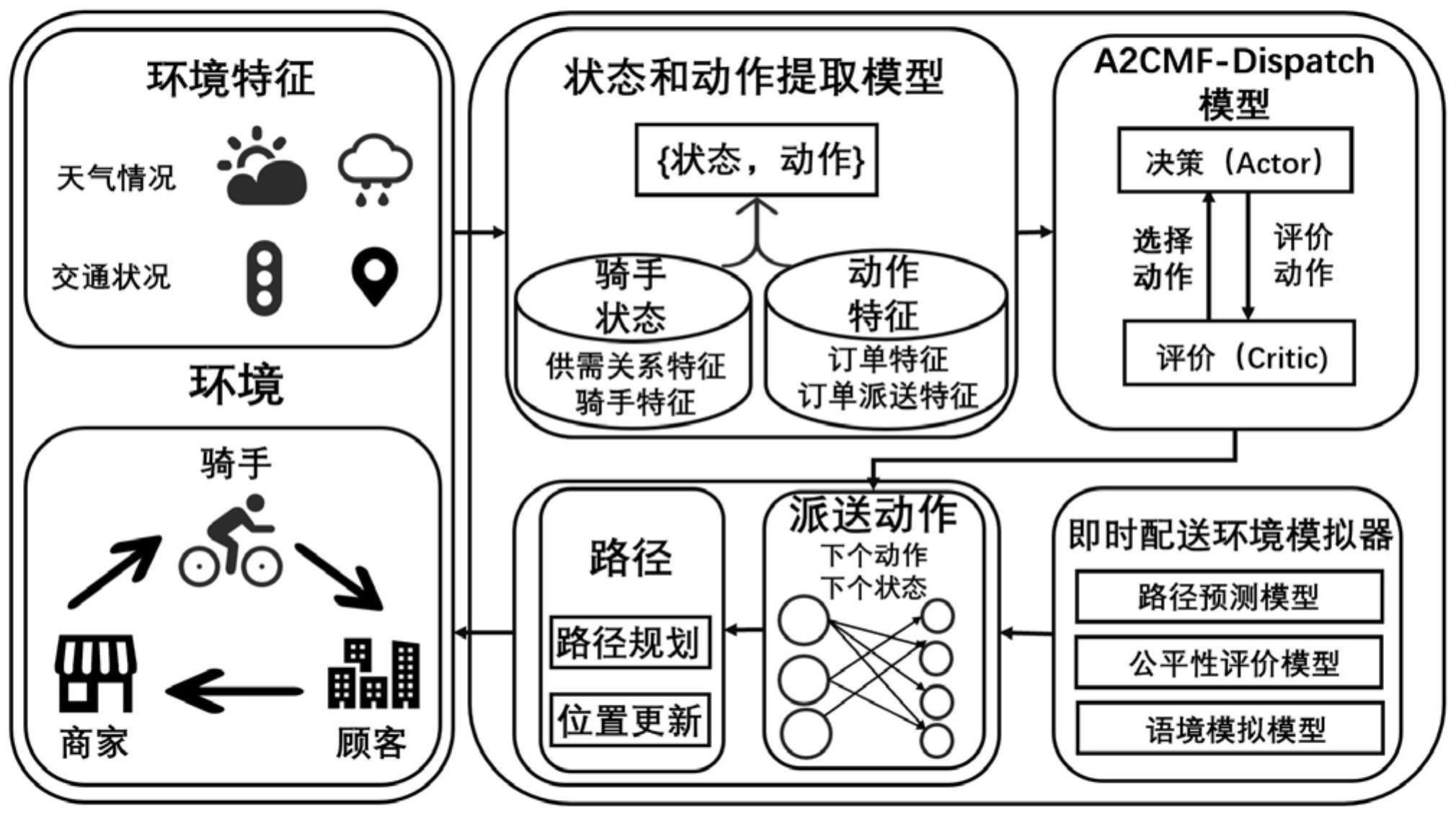
2、基于多方公平的即时配送系统,包括以下步骤:
3、步骤(1)特征处理模块:特征处理模块基于真实世界即时配送场景的数据和运行规则,收集不同派送区域的环境、历史订单记录和多方的公平性信息,经过预处理生成对应的特征信息。其中,多方公平性信息基于我们对于参与即时配送系统的利益方(骑手、商家和顾客)的公平性定义;
4、步骤(2)环境仿真模块:环境仿真模块基于真实的即时配送场景仿真骑手的配送环境。其中,环境仿真模块以马尔可夫决策过程为框架描述骑手状态转移的过程,并设计骑手接单模拟模块和骑手配送路径模拟模块;
5、步骤(3)即时派单模块:即时派单模块为每一个待分配的订单生成候选骑手集合并为其构建状态特征空间和动作特征空间,并利用强化学习中的advantage actor-critic算法在仿真环境中训练派单策略,基于输入的特征空间生成最合适的候选骑手并将订单分派给该骑手。在训练过程中,本模块会生成考虑多方公平的奖励系数并引导派单策略关注于每一个参与方的公平性信息。
6、进一步的,步骤(1)具体包括:
7、(1-1)收集不同派送区域的环境、历史订单记录和多方的公平性信息,具体步骤为:①记录派送区域在数据收集时间的环境信息,包含天气、是否是节假日、路况拥堵情况和路网信息。②从数据库中提取历史订单配送信息,包括订单id、订单价格、订单所属骑手、订单预计送达时间、订单中商家位置、订单中顾客位置、订单生成时间、骑手接单时间、骑手到店时间、骑手取餐时间和骑手送达时间。③收集骑手的历史收入信息、商家的订单历史接单时间和用户的历史订单送达时间,用于计算多方的公平性。
8、(1-2)明确多方公平的定义,具体步骤为:
9、顾客层面的公平基于least misery fairness定义,将订单时段分为高峰段与非高峰段,分别设置顾客最长容忍等单时间,满足某一时段内顾客最长等待的超时时间都在容忍阈值内,即可保障顾客在平台的公平性权益。当骑手当前的订单对应的顾客最长等待的超时时间超过了容忍阈值,则认为该顾客得到了不公平的对待,骑手需要优先解决该问题(将订单即时送达),否则系统将不给该骑手分配新的订单。
10、设置在时隙t时订单i的利润率pe(i,t)如下:
11、pe(i,t)=γδt×feei
12、其中δt是从顾客下单到最终配送花费的时间,γ∈[0,1]是与时间开销有冠的折扣因子,feei是订单i的配送费。注意到如果配送费相同,δt花的时间越短,订单i的利润率就越高。
13、确定以所有骑手在平台中的利润率ce的方差cf代表骑手之间利润公平性,计算方式如下:
14、
15、
16、可见骑手k在时隙t时所赚的利润ce(k,t)由单位劳动时长的收入来衡量,m表示骑手当前总共派送的订单个数,twork为骑手工作的小时数。
17、是时隙t时活跃在平台的所有骑手平均的利润率,nc是在线的骑手数,从而算出所有骑手的利润方差作为骑手之间的利润公平性。
18、本发明认为当商家的产品可以被骑手及时拿到以送给顾客即是公平的。基于此,对商家之间的利润公平mf的定义如下:
19、
20、
21、其中no是商家生产的订单数量,dist表示配送的距离,tm(i)表示商品i准备好的时间点,td(i)是送达顾客的时间点,即td(i)-tm(i)为商家等待骑手取走商品与骑手派送到顾客处的总时间。pv(m,t)越大意味着商品m在时隙t内越不及时,更小的mf代表对商家来说有更公平的平台体验。
22、(1-3)从数据中提取出能影响及时配送派单行为的特征,具体步骤为:①以每一个订单为锚点,记录订单与其关联的骑手、商家、用户中能影响派单算法的特征。②与订单相关的派单算法特征为:订单价格、订单预计送达时间。③与骑手相关的派单算法特征为:骑手当前位置、骑手当前订单量、骑手未来派单路径、骑手累计收入、骑手累计工作时间。④与商家相关的派单算法特征为:商家位置、商家平均等餐时间。⑤与顾客相关的派单算法特征为:顾客位置、顾客最长容忍等餐时间。
23、进一步的,步骤(2)具体包括:
24、(2-1)基于马尔可夫决策过程设计即时配送场景的仿真环境。本发明将基于多方公平的订单配送问题抽象建模为多智能体马尔可夫决策过程。其中,马尔可夫决策过程包含五个部分:代理人,状态s,动作a,奖励r,状态转移函数f(s|a,s)。马尔科夫决策过程的基本原理为代理人在环境中执行动作a,环境会反馈奖励r来评价这个动作的收益,代理人的状态s也会基于状态转移函数f(s|a,s)发生改变。在本发明中,马尔可夫决策过程被具体描述为:
25、①代理。每一个骑手被设定为一个代理,与环境进行交互,执行动作并接收环境反馈(奖励)的功能。在本模块中,骑手被设定能接收六个订单,在配送箱内有位置时参与附近订单的接单过程,并在没有接单任务时按照系统设定路径配送已经分配的订单。其中,配送过程分为前往商家位置取餐和前往顾客位置派餐两个步骤。在马尔可夫决策过程中,每个代码都拥有一个实时的状态st,并会执行接单动作at。
26、②状态s。状态st为描述骑手在当前时刻t与派单行为相关的特征。其中,状态s={pt,stt,dt,ct},其中p是骑手的个人特征,st是骑手的未来的竞争特征,d是区域内多方的整体供需特征,而c则是语境特征。其中:
27、pt:pt描述骑手在当前时间t的个人特征,pt=[loc,no,to,f,routep],其中loc表示骑手实时位置,no是骑手当前订单数目,f是一个公平性标志,表示该骑手是否能在不破坏当前订单对应的用户公平的前提下接收新的订单,如果f=0,则骑手则不可以接收新的订单直到当前所有已有订单对应的用户公平能被保障。routep表示骑手未来路径,在本模块中使用贪心算法进行预测。
28、stt:stt描述了骑手的竞争特征,表示骑手基于预测的未来路径routep所收到的竞争压力,no为当前该路径上所有的订单数目,而nt为当前该路径上的所有的骑手数目。
29、dt:dt描述了系统全局的供需信息,包括在每一个网格内当前的订单数目、骑手数目、商家数目和用户数目。
30、ct:描述骑手当前所在网格的语境信息,包括天气(晴天、雨天或者阴天)、拥堵情况(拥堵、稍微拥堵和通畅)和日期(工作日或休息日)。
31、③动作a。动作a为描述某个订单被分配给某个骑手的行为。具体的动作需要描述骑手与订单的匹配情况,具体情况为:at=[p,tc,lm,lc,dis,addt]。其中,p为订单价格,tc为订单产生时间,lm为商家位置,lc为用户位置,dis为骑手和订单的距离,addt为骑手收到该订单后增加的配送时间。
32、④奖励r。奖励r为描述环境对于代理人在当前状态s下执行动作a的反馈,一般而言,系统希望累计的奖励r越大越好。其中,奖励r的具体定义为:
33、r(i)(st,at)=(1-α-β)pe(i,t)+α·(-cf(t))+β·(-mf(t))
34、⑤状态转移函数f(s|a,s)。状态转移函数f(st+1|at,st)描述代理人在当前状态st下执行动作at,转移到下一个状态st+1的概率。其中,f(st+1|at,st)主要描述骑手在从t到t+1的过程中位置和订单信息的变化情况,位置收到骑手未来路径影响,而订单信息受到骑手接单和派单行为影响。
35、(2-2)设计骑手接单模拟模块。具体细节为:当有新订单产生时,系统会选定该订单一定范围内(比如一公里)的合适骑手,并生成候选骑手池。系统将根据即时派单模块为订单分配最合适的骑手,并将该订单分派给该骑手进行配送。
36、(2-3)设计骑手配送路径模拟模块,具体细节为:基于骑手当前的订单,提取出骑手未来要前往的商家位置和用户位置。在没有订单违反用户公平定义的前提下,骑手会前往最近的地点执行取餐或送达任务。在有订单违反用户公平定义时,骑手被强制要求优先完成该订单,再执行其他订单的配送任务。
37、进一步的,步骤(3)具体包括:
38、(3-1)为每一个待分配的订单生成候选骑手集合并为其构建状态特征空间和动作特征空间步骤为:基于每一个订单周围一定范围(比如一公里)收集待选骑手生成候选骑手集合,并集合每一个骑手的当前状态并生成状态特征空间,集合每一个骑手与订单的匹配动作得到动作特征空间。其中,为骑手i在时刻t的状态特征,而为假设骑手i接收到该订单后在时刻t与该订单匹配的动作特征。
39、(3-2)明确advantage actor-critic算法计算最优骑手的步骤为:
40、基于actor网络输出骑手-订单匹配价值其中输入为上一步得到的状态特征空间和动作特征空间中抽取的骑手i的和actor网络为一个五层全连接神经网络,激活函数为relu函数。骑手-订单匹配价值用来描述评估在接受该订单后收获的价值,即在当前状态下执行动作预计未来累计能收获的系统奖励r的总和。
41、基于critic网络输出骑手当前价值其中输入为上一步得到的状态特征空间中抽取的骑手i的critic网络为一个四层全连接神经网络,激活函数为relu函数。骑手当前价值用来描述骑手i基于当前状态未来能收获到的系统奖励r的总和,即:
42、
43、其中γ为一个小于1的折扣因子,用于表示未来获得的奖励对当前价值的影响情况。一般来说,距离当前越远,累计的折扣因子越高,获得的价值越小。
44、基于softmax函数为当前订单输出最优骑手。在为该订单对应的候选骑手集内所有骑手生成了骑手-订单匹配价值后,利用softmax函数输出当前订单最适合的最优骑手并将订单进行分配。
45、
46、在这一步后,该订单便被分配给了骑手i。对于每一个订单,都经历这些步骤后被分配给了对应的骑手,并完成了基于即时配送的序列派单。
47、(3-3)基于softmax函数为当前订单输出最优骑手。在为该订单对应的候选骑手集内所有骑手生成了骑手-订单匹配价值后,利用softmax函数输出当前订单最适合的最优骑手并将订单进行分配。
48、
49、在这一步后,该订单便被分配给了骑手i。对于每一个订单,都经历这些步骤后被分配给了对应的骑手,并完成了基于即时配送的序列派单。
50、(3-4)明确advantage actor-critic算法的网络更新步骤为:
51、对于actor网络,更新函数为:
52、
53、其中,θa为actor网络的参数。
54、对于critic网络,更新函数为:
55、
56、其中,θa为critic网络的参数。
57、(3-5)明确训练派单策略算法的具体步骤为:
58、在每个时隙t获取订单信息。每个时隙,环境从包含如商家位置、用户位置、价格、保证配送时间等真实的数据集中生成待分配的订单集合。
59、决定配送的范围。对于每个订单,在附近一定范围内的骑手获得接单机会。我们的模型在满足顾客满意度的严格限制下挑选合适数量的待选骑手。通过将顾客公平性作为限制项的方式实现兼顾整体公平性中的顾客公平。
60、提取订单及待选骑手特征。在确定了待选骑手后,通过环境仿真和特征提取模块,我们提取了包括时空、路径规划、现有订单和天气等信息的特征,并将这些特征表述为马尔可夫决策模型可以接受的形式。
61、将订单分配给找到的最优骑手。模型会将每个订单的信息送进advantage actor-critic网络。actor网络计算订单和骑手匹配价值后的价值并通过softmax函数推荐最优的骑手。critic网络评价骑手未来获取价值的能力并在更新actor网络时参与对actor网络的评估。
62、仿真并执行骑手的路径规划。此时当前时隙所有的订单都被分配到了最优解的骑手,系统基于步骤(2-3)中的骑手配送路径模拟模块对骑手未来路径规划进行更新。
63、本发明的有益效果:
64、(1)对于即时配送平台而言,通过该系统仍可以保障较高的派单效率,提高平台的总收入;对于提供派送服务的骑手而言,通过该系统可以为他们提供更公平的劳动收入分配,维护了他们同工同酬的权益;对提供商品的商家而言,该系统可以帮助他们获得较公平的配送服务体验;最后对于顾客而言,该系统可以确保他们的等单时间控制在最大容忍程度内,由此,是一个基于多方公平的即时配送派单系统。
65、(2)实验结果表明,本发明的系统算法不同于传统的调度算法,不仅提高了派单平台的总收入21.3%,还尽可能地最小化顾客等待时间,且分别缩小了骑手之间和商家之间收益差距达9.7%和6.2%。
- 还没有人留言评论。精彩留言会获得点赞!