一种金融数据实体关系的联合抽取方法及相关设备
本发明涉及金融文本自然语言处理,特别涉及一种金融数据实体关系的联合抽取方法及相关设备。
背景技术:
1、随着经济的发展,各类经济金融活动数据爆炸式增长,通过对此类数据进行分析,可以获得大量隐藏知识,以更好地服务金融行业。
2、关系抽取是自然语言处理中常见的一类任务。对于两个存在关系的实体,可以将其分别称为主体和客体,关系抽取即在非结构或者半结构化的数据中找出主体与客体之间存在的关系,并且表示为实体关系三元组,即〈主体,关系,客体〉。
3、近年来,以深度学习为代表的关系抽取技术,通过大型的预训练模型和海量的语料,还通过对文本特征的提取以及特定的映射,将文本中实体与关系的语义信息表示为低维连续空间向量,通过对向量进行计算和处理来预测实体之间关系相应的复杂语义信息。
4、目前,基于深度学习的关系抽取技术主要分为两类:管道抽取(pipeline)、联合抽取(joint)。管道抽取是指使用两个模型分别进行命名实体识别和关系分类,这样做通常会导致误差传播,两个任务交互不强的问题;联合抽取则在一个模型中,通过共享同一个编码器的方式,完成命名实体识别和关系分类两个任务。通用联合抽取方法通常存在以下两个问题,一是特征矛盾,即一个编码器输出的特征信息对实体识别和关系分类两个任务可能并非全部友好,两个任务需要的信息可能重叠也可能矛盾;二是交互方式,联合抽取通常只能实现实体识别到关系分类或者关系分类到实体识别的单向交互,而两个任务是相互促进的,如何实现任务的双向交互值得探索。
5、然而,大多数模型只注重文本特征的抽取过程,对于利用文本特征向量进行关系预测建模仍存在一些泛化性能差,语义解释性差等问题;且现有的关系抽取模型通常是通用化的,针对中文金融领域的研究比较少,大多针对英文文本进行分析,直接将英文领域的联合抽取模型用于中文金融数据,三元组抽取的准确率比较低,无法用于实践。
技术实现思路
1、本发明提供了一种金融数据实体关系的联合抽取方法及相关设备,其目的是为了提高金融数据实体关系抽取的准确性。
2、为了达到上述目的,本发明提供了一种金融数据实体关系的联合抽取方法,包括:
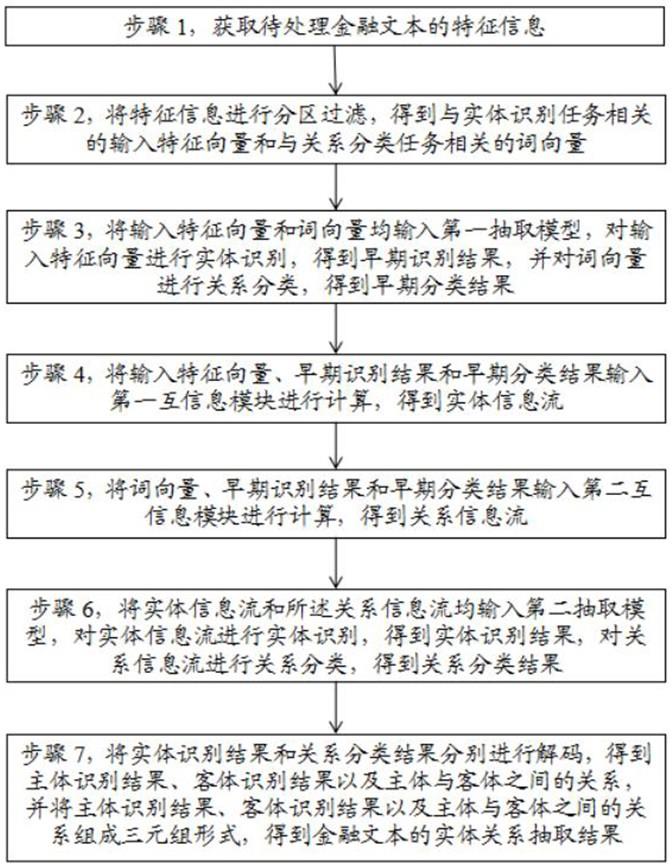
3、步骤1,获取待处理金融文本的特征信息;
4、步骤2,将特征信息进行分区过滤,得到与实体识别任务相关的输入特征向量和与关系分类任务相关的词向量;
5、步骤3,将输入特征向量和词向量均输入第一抽取模型,对输入特征向量进行实体识别,得到早期识别结果,并对词向量进行关系分类,得到早期分类结果;
6、步骤4,将输入特征向量、早期识别结果和早期分类结果输入第一互信息模块进行计算,得到实体信息流;
7、步骤5,将词向量、早期识别结果和早期分类结果输入第二互信息模块进行计算,得到关系信息流;
8、步骤6,将实体信息流和关系信息流均输入第二抽取模型,对实体信息流进行实体识别,得到实体识别结果,对关系信息流进行关系分类,得到关系分类结果;
9、步骤7,将实体识别结果和关系分类结果分别进行解码,得到主体识别结果、客体识别结果以及主体与客体之间的关系,并将主体识别结果、客体识别结果以及主体与客体之间的关系组成三元组形式,得到金融文本的实体关系抽取结果。
10、进一步来说,步骤1包括:
11、获取待处理的金融文本;
12、将金融文本通过finbert预训练模型进行特征提取,得到金融文本的深层次特征信息。
13、进一步来说,步骤2包括:
14、将金融文本的深层次特征信息分别输入两个卷积神经网络,通过控制卷积窗口和卷积步长的大小对深层次特征信息进行局部特征提取,得到多粒度实体分区任务特征和多粒度关系分区任务特征;
15、利用多粒度实体分区任务特征、多粒度关系分区任务特征以及深层次特征信息分别在每个卷积神经网络的输出端建立局部注意力模块,通过局部注意力模块的评分函数对深层次特征信息进行过滤,得到与实体识别任务相关的输入特征向量以及与关系分类任务相关的词向量。
16、进一步来说,多粒度实体分区任务特征的计算方式为:
17、
18、
19、多粒度关系分区任务特征的计算方式为:
20、
21、
22、其中,表示在卷积窗口为、卷积步长为、零填充为时得到的多粒度实体分区任务特征,表示在卷积窗口为、卷积步长为、零填充为时得到的多粒度关系分区任务特征,表示计算多粒度实体分区任务特征时卷积窗口每滑动一次得到的特征向量,表示计算多粒度关系分区任务特征时卷积窗口每滑动一次得到的特征向量,表示输入文本中第到的单词组成的词向量矩阵,表示输入文本中第到的单词组成的词向量矩阵,表示窗口所包含词的个数,表示单个词向量的维度,表示句子的长度,表示偏置量。
23、进一步来说,通过局部注意力模块的评分函数,对深层次特征信息进行过滤,包括:
24、将多粒度实体分区任务特征定义为查询向量,即:
25、
26、利用深层次特征信息得到键向量和值向量:
27、
28、
29、其中,表示深层次特征信息,表示得到的键向量,表示得到的值向量,表示可训练矩阵;
30、实体识别任务相关的输入特征向量为:
31、
32、其中,表示激活函数,表示键向量的转置,表示单个词向量的维度。
33、进一步来说,通过局部注意力模块的评分函数,对深层次特征信息进行过滤,包括:
34、将多粒度关系分区任务特征定义为查询向量,即:
35、
36、利用深层次特征信息得到键向量和值向量:
37、
38、
39、其中,表示深层次特征信息,表示得到的键向量,表示得到的值向量,表示可训练矩阵;
40、关系分类任务相关的词向量为:
41、
42、其中,为激活函数,表示键向量的转置,表示单个词向量的维度。
43、本发明还提供了一种金融数据实体关系的联合抽取装置,包括:
44、获取模块,用于获取待处理金融文本的特征信息;
45、分区过滤模块,用于将特征信息进行分区过滤,得到与实体识别任务相关的输入特征向量和与关系分类任务相关的词向量;
46、早期识别分类模块,用于将输入特征向量和词向量均输入第一抽取模型,对输入特征向量进行实体识别,得到早期识别结果,并对词向量进行关系分类,得到早期分类结果;
47、第一计算模块,用于将输入特征向量、早期识别结果和早期分类结果输入第一互信息模块进行计算,得到实体信息流;
48、第二计算模块,用于将词向量、早期识别结果和早期分类结果输入第二互信息模块进行计算,得到关系信息流;
49、识别分类模块,用于将实体信息流和关系信息流均输入第二抽取模型,对实体信息流进行实体识别,得到实体识别结果,对关系信息流进行关系分类,得到关系分类结果;
50、抽取模块,用于将实体识别结果和关系分类结果分别进行解码,得到主体识别结果、客体识别结果以及主体与客体之间的关系,并将主体识别结果、客体识别结果以及主体与客体之间的关系组成三元组形式,得到金融文本的实体关系抽取结果。
51、本发明还提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时实现金融数据实体关系的联合抽取方法。
52、本发明还提供了一种终端设备,包括存储器、处理器以及存储在存储器中并可在处理器上运行的计算机程序,处理器执行计算机程序时实现金融数据实体关系的联合抽取方法。
53、本发明的上述方案有如下的有益效果:
54、(1)本发明通过获取待处理金融文本的特征信息,在两个卷积神经网络的输出端将特征信息进行分区过滤,得到与实体识别任务相关的输入特征向量和与关系分类任务相关的词向量,在数据特征层面将特征按任务进行了区分,避免了特征矛盾问题;
55、(2)通过将第一抽取模型作为早期预测,将输入特征向量和词向量均输入第一抽取模型,对输入特征向量进行实体识别,得到早期识别结果,并对词向量进行关系分类,得到早期分类结果;将输入特征向量、早期识别结果和早期分类结果输入第一互信息模块进行计算,得到实体信息流;将词向量、早期识别结果和早期分类结果输入第二互信息模块进行计算,得到关系信息流,利用第一互信息模块和第二互信息模块计算,过滤了早期识别结果和早期分类结果中的噪声信息,得到的实体信息流和关系信息流;将实体信息流和关系信息流均输入第二抽取模型进行实体识别和关系分类,得到实体识别结果和关系分类结果,通过互信息模块计算后的实体信息流和关系信息流包含早期关系分类,实体识别的结果,并将其送入第二抽取模型进行命名实体识别任务,关系分类任务,实现了实体识别和关系分类的双向交互;
56、(3)将实体识别结果和关系分类结果分别进行解码,得到主体识别结果、客体识别结果以及主体与客体之间的关系,并将主体识别结果、客体识别结果以及主体与客体之间的关系组成三元组形式,得到金融文本的实体关系抽取结果;提高了金融数据实体关系抽取的准确率。
57、本发明的其它有益效果将在随后的具体实施方式部分予以详细说明。
- 还没有人留言评论。精彩留言会获得点赞!