一种基于不完整数据的空气质量预测方法及系统与流程
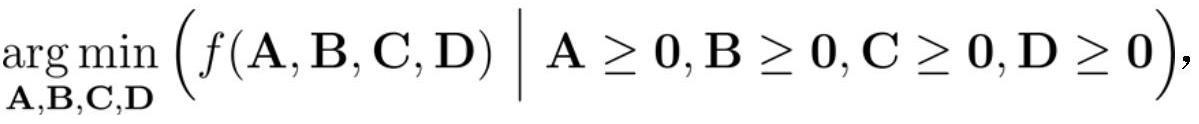
本发明涉及城市计算领域,尤其涉及一种基于不完整数据的空气质量预测方法及系统。
背景技术:
1、空气质量预测旨在预测给定的一个或多个监测点未来某段时间内的各种污染物的数值。一方面,已有方法大多假设空气质量监测数据是完整的。在现实生活中,由于传感器故障、网络中断等原因,空气质量监测数据中经常会出现一些缺失值。因此,如何设计一种能够在基于不完整数据进行空气质量预测的方法仍是一个有待解决的问题。另一方面,污染物之间有着复杂的空间、时间和类别相关性。比如,一个监测点的污染物会受到它附近监测点污染物的影响,进而导致两个相邻监测点的污染物数值比较相似。已有方法大多没有充分利用空气质量监测数据中蕴含的时间、空间和类别关联来提高预测性能。
技术实现思路
1、本发明目的:本发明旨在提供一种基于不完整数据的空气质量预测方法及系统,它不仅可以直接在不完整数据上进行预测,其中,不完整数据是指存在缺失值的空气质量监测数据;还充分利用了空气质量监测数据中蕴含的空间、时间和类别相关性以提高预测的性能。其中,不完整数据是指存在缺失值的空气质量监测数据。
2、本发明技术方案:一种基于不完整数据的空气质量预测方法,包括如下步骤:
3、步骤一:给定p个监测点、m种污染物(包括pm2.5、pm10等)和t天,将历史空气质量监测数据组织成一个三维张量其中表示第t天,第p个监测点监测到的第m种污染物的数值;
4、步骤二:给定集合ω,它包含三维张量中已知元素(即可观测到的元素)的索引,即如果xptm是已知的,那么(p,t,m)∈ω;
5、步骤三:给定预测天数k和张量维度i2,构造空气质量张量
6、步骤四:基于集合ω,构造权重张量
7、步骤五:基于空气质量张量和权重张量构造目标函数f(a,b,c,d),进而得到优化问题其中a、b、c、d是因子矩阵;
8、步骤六:利用交替最小化算法,求得因子矩阵的估计值
9、步骤七:根据因子矩阵的估计值计算t+1天到t+k天中,每个监测点各种污染物的数值。本发明有效解决了在不完整数据上进行空气质量预测的问题。
10、步骤三中,所述给定预测天数k和张量维度i2,构造空气质量张量具体包括:
11、将扩展为其中1≤p≤p,1≤t≤t+k,1≤m≤m;
12、构造一个四维张量来表示空气质量监测数据。这里,i1=p,i4=m,即待预测的监测点数和污染物种类数。i2设置为7的倍数,如7、14、21等,且i2>k;其中表示向下取整函数,即返回小于或等于给定数字的最大整数。令t′=t+k-i2×i3,按如下规则映射到
13、
14、1≤p≤p,t′+1≤t≤t+k,1≤m≤m。“mod”表示取模运算,返回一个数除以另一个数的余数。表示向上取整函数,即返回大于或等于给定数字的最小整数。
15、步骤四中,所述基于集合ω,构造权重张量具体包括:
16、构造权重张量其中和(p,t,m)之间的关系由如下映射规则确定:
17、
18、1≤p≤p,t′+1≤t≤t+k,1≤m≤m。
19、步骤五中,所述基于空气质量张量和权重张量构造目标函数f(a,b,c,d),进而得到优化问题其中a、b、c、d是因子矩阵,具体包括:
20、构造目标函数其中,*表示按位相乘,||·||f表示frobenius范数。是因子矩阵。r是一个正整数,称为张量的cp秩。即把分解为一系列秩为1的张量之和。是正则化项,这里令是一个参数,用于控制正则化项对目标函数的影响。
21、在此基础上,可得优化问题
22、步骤七中,所述根据计算t+1天到t+k天中,每个监测点各种污染物的数值,具体包括:
23、第t天,第p个监测点的第m种污染物的预测值由下式得到:
24、
25、1≤p≤p,t+1≤t≤t+k,1≤m≤m。其中,
26、一种基于不完整数据的空气质量预测系统,其中,不完整数据是指存在缺失值的空气质量监测数据。该系统的特征在于,包括:数据处理单元、张量构造单元、优化目标建模单元、模型训练单元和空气质量预测单元。
27、数据处理单元,用于将历史空气质量监测数据组织成一个三维张量其中p是监测点数、m是污染物种类数,t是天数,表示第t天,第p个监测点监测到的第m种污染物的数值;
28、张量构造单元,用于根据给定的预测天数k、张量维度i2和三维张量构造空气质量张量
29、所述张量构造单元还用于,根据给定的集合ω,构造权重张量
30、优化目标建模单元,用于根据空气质量张量和权重张量构造目标函数f(a,b,c,d),进而得到优化问题其中a、b、c、d是因子矩阵;
31、模型训练单元,用于利用交替最小化算法,求得因子矩阵的估计值
32、空气质量预测单元,用于根据计算t+1天到t+k天中,每个监测点各种污染物的数值。
33、数据处理单元,用于将历史空气质量监测数据组织成一个三维张量其中p是监测点数、m是污染物种类数,t是天数,表示第t天,第p个监测点监测到的第m种污染物的数值;
34、张量构造单元,用于根据给定的预测天数k、张量维度i2和三维张量构造空气质量张量
35、所述张量构造单元还用于,根据给定的集合ω,构造权重张量
36、优化目标建模单元,用于根据空气质量张量和权重张量构造目标函数f(a,b,c,d),进而得到优化问题其中a、b、c、d是因子矩阵;
37、模型训练单元,用于利用交替最小化算法,求得因子矩阵的估计值
38、空气质量预测单元,用于根据计算t+1天到t+k天中,每个监测点各种污染物的数值。
39、进一步地,所述张量构造单元,具体用于,将扩展为其中1≤p≤p,1≤t≤t+k,1≤m≤m;
40、构造一个四维张量来表示空气质量监测数据。这里,i1=p,i4=m,即待预测的监测点数和污染物种类数。i2设置为7的倍数,如7、14、21等,且i2>k。其中表示向下取整函数,即返回小于或等于给定数字的最大整数。令t′=t+k-i2×i3,按如下规则映射到
41、
42、1≤p≤p,t′+1≤t≤t+k,1≤m≤m。“mod”表示取模运算,返回一个数除以另一个数的余数。表示向上取整函数,即返回大于或等于给定数字的最小整数;
43、构造权重张量其中(i1,i2,i3,i4)和(p,t,m)之间的关系由如下映射规则确定:
44、
45、1≤p≤p,t′+1≤t≤t+k,1≤m≤m。
46、进一步地,所述优化目标建模单元,具体用于,构造目标函数其中,*表示按位相乘,||·||f表示frobenius范数。是因子矩阵。r是一个正整数,称为张量的cp秩。即把分解为一系列秩为1的张量之和。是正则化项,这里令λ是一个参数,用于控制正则化项对目标函数的影响。
47、在此基础上,可得优化问题
48、进一步地,所述空气质量预测单元,具体用于,根据下式得到第t天,第p个监测点的第m种污染物的预测值:
49、
50、1≤p≤p,t+1≤t≤t+k,1≤m≤m。其中,
51、有益效果:本发明有效解决了在不完整数据上进行空气质量预测的问题,并通过综合考虑空气质量监测数据中蕴含的时间、空间和类别关联性,提高模型的预测性能。
- 还没有人留言评论。精彩留言会获得点赞!