嵌入式设备的多输入神经网络模型串行块的存储方法与流程
本发明属于嵌入式设备,具体地说是一种嵌入式设备的多输入神经网络模型串行块的存储方法。
背景技术:
1、神经网络模型已经被广泛应用于计算机视觉、自然语言处理等领域。随着技术的不断发展,人们对神经网络模型的期望越来越高。然而,由于神经网络模型需要大量的计算资源和存储空间,这使得在嵌入式设备上部署神经网络模型成为一个具有挑战性的问题。端侧嵌入式设备对神经网络有实时要求,功耗要求,算力要求,可配置性要求,隐私保护要求,这使得神经网络模型的部署变得更加复杂。对端侧神经网络模型部署的相关需求和常见解决手段主要如下:
2、可配置性要求:这个需求是神经网络落地实际产品时都会遇到的需求。这个需求主要出现在方案调试阶段以及客户使用阶段。在方案调试阶段,方案调试人员在推广客户时,灵活可配对于方案的快速落地会有非常大的帮助。由于网络模型是轻量级的,一般轻量级网络由于泛化能力的不足,并不能支持较多的配置项,以改变效果。常用的做法是训练很多个轻量级模型,这在选项较少的情况下可行,如果选项较多时,模型个数将会随着选项的个数成指数次上升,这对于训练模型海还是部署模型都是不可接受的。比如每个选项分2档进行训练,那么10个选项,排列组合将达到2的10次方个模型。在客户使用阶段,也有些个性化的选项需要调节,比如图像的清晰程度,降噪的强度等,端侧设备存储空间有限,无法存放过多的模型。
3、隐私保护要求:用户的图像,声音等都是隐私信息,在用户隐私越来越重视的今天很多产品都会限制端侧用户数据的搜集。
4、实时性要求:对端侧视音频处理网络而言,实时性要求是一个基本需求,实时性不能满足要求,可能会出现视频丢帧,声音断续等异常情况,这是方案上无法接受的。
5、功耗要求:功耗要求对于嵌入式设备,也是一个基本要求,特别对于电池供电设备而言,更是方案设计时考虑的主要因素之一。
6、算力要求:嵌入式设备由于成本和功耗的原因的导致计算资源有限,因此在部署和设计神经网络时需要采取很多优化手段。
7、以下列举一些为了满足,实时性,功耗和算力要求,而采用的模型优化部署方法:
8、第一类方法是对网络的权重进行量化和压缩,由于嵌入式设备上存储空间有限,这种手段主要目的是为了减少权重的存储量。
9、第二类手段是优化网络的结构采用知识蒸馏,结构化剪枝等手段使得网络结构轻量化。如专利cn108280453a公开一种基于知识蒸馏的图像超分辨率增强方法,通过知识蒸馏技术对超分辨率网络进行轻量化训练,从而实现低功耗和效果的平衡。但轻量化网络由于其计算复杂度的降低,在复杂场景下,势必导致泛化性能的损失。
10、第三类手段是采用云端结合的方式来解决轻量级网络在部署时效果问题,专利cn115170840a提供一种在云侧设备上部署有参数生成模型,端侧设备上部署有轻量级模型。通过端侧信息的搜集反馈给云端服务器,而云端服务器实时更新端侧模型参数。从而在不增加端侧模型资源负担的情况下,提升端侧模型的泛化能力。但端侧设备存在几个实际问题,是该方案无法解决的:首先,端侧设备存在无法联网的情况,模型无法更新。其次,端侧设备有隐私保护要求,无法提供当前用户的数据给云端。再次,对于实时性要求非常高的应用,如实时的超分辨率恢复,自动驾驶等,网络由于存在延迟和信号质量问题并不能确保实时性满足要求。
11、在端侧部署神经网络的过程中,通过配置信息,统计信息的输入,提升模型的可配置性和泛化能力,但由于端侧嵌入式设备存在资源,功耗,联网能力等限制,输入信息的增加需要模型计算复杂度相应增加,才能提高泛化能力,但模型的轻量化要求限制了其性能的进一步提升。特别是对于实时超分辨率网络而言,由于其处理图像的分辨率一般较大,其实时性要求较高,对算力的需求十分巨大,因此在端侧嵌入式设备往往只能采用极度精简的轻量化模型,场景的适应性较差,直接通过参数增加参数的方式,提升的泛化能力比较有限。训练多个模型的方法如上文所述将面临着模型个数爆炸问题。如果交给云端参数生成模型处理,又面临着隐私保护和实时性的问题。
技术实现思路
1、本发明的目的在于提供一种嵌入式设备的多输入神经网络模型串行块的存储方法。本发明方法利用输入数据更新速度的不同,通过对网络模型结构的优化,以及对应此结构的部署优化,降低该神经网络部署在端侧嵌入式设备上的算力需求,运行功耗要求。从而使得嵌入式设备可以部署更大规模的多输入神经网络模型,以提升模型的可配置性和泛化能力。
2、本发明的具体技术方案是:
3、所述嵌入式设备包含输入单元、神经网络计算单元、输出单元、中央处理器和存储器。其中:
4、输入单元进行数据的输入和前处理,如摄像头信号接收模块和传统isp模块;
5、神经网络计算单元通过对多输入神经网络模型进行推理计算,处理输入单元所获取的数据;所述的多输入神经网络模型包含多个输入数据接口,并且输入的数据之间具有多个更新频率差异;
6、输出单元将神经网络计算单元处理后的结果输出到显示设备或存储器中;
7、中央处理器负责调度、配置和部署神经网络模型;
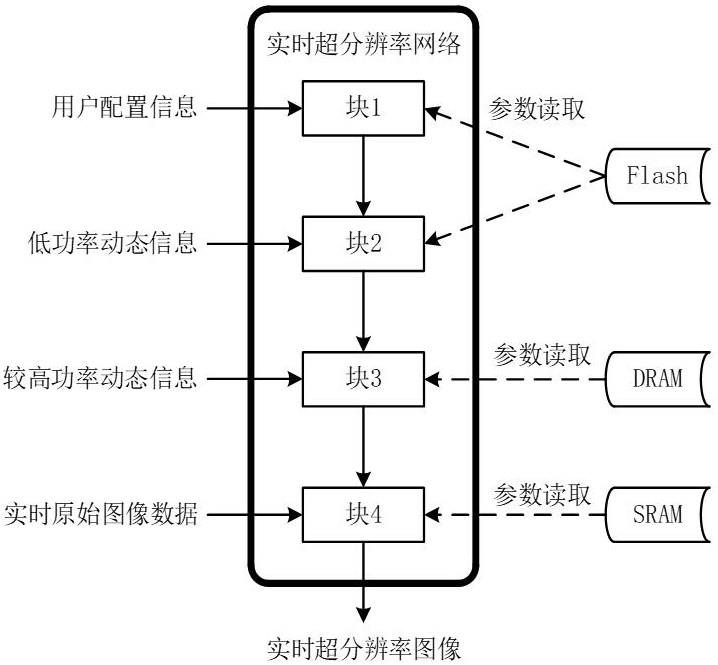
8、存储器用于存储神经网络模型的参数和数据,包括片内sram、dram和flash。
9、所述的多输入神经网络模型的参数包括神经网络的结构信息和权重信息,为神经网络模型训练完成后固化不变的信息;
10、所述的多输入神经网络模型的数据包括神经网络的输入数据和输出数据,以及推理过程中的每一层输出的临时数据;
11、所述的多输入神经网络模型的输入数据为配置信息、统计数据和图像数据中的一种或多种;
12、所述的多输入神经网络模型的结构按输入数据更新频率的不同,由低到高分为n个串行块,n≥2,数据更新频率相同的结构作为一个串行块;每个串行块包含一层或多层神经网络,如卷积神经网络、全连接神经网络和循环神经网络;串行块存储多输入神经网络模型该块的参数和数据;
13、第一串行块k1接收更新频率最低的数据输入,第一串行块k2接收更新频率次低的数据输入和第一串行块k1的输出,以此类推,第n串行块kn接收更新频率最高的数据输入和第n-1串行块kn-1的输出;如果更新频率相同,则作为同一个块的输入。
14、所述多输入神经网络模型采用有监督训练,并采用bp算法进行优化,不同串行块之间均为可导。
15、具体存储方案确定方法如下:
16、将多个存储器按照访问速度从慢到快进行排序,c1,…,cm,m为存储器数量;将n个串行块的参数和数据以串行块为单位存储到m个存储器中,更新频率低的串行块的参数和数据存储到访问速度慢的存储器,如果第n个串行块kn的参数和数据存储到第m个存储器cm中,则第n+1个串行块kn+1的参数和数据存储到第m个存储器cm或第m+1个存储器cm+1中;
17、运行所述的多输入神经网络模型,如果某个串行块kn的输入需要更新,则中央处理器调度神经网络计算单元,对该串行块kn进行计算,得到该串行块kn输出,作为第n+1串行块kn+1的输入,n=1,2,…,n-1;中央处理器调度神经网络计算单元,对第n+1串行块kn+1进行计算,得到第n+1串行块kn+1的输出,作为第n+2串行块kn+1的输入;以此类推,第n串行块kn的输出,完成推断。对串行块kn之前的串行块k1,…,kn-1不进行计算;
18、按照以上条件,遍历所有存储情况,并进行多输入神经网络模型的运行,测量和记录每种存储情况的功耗和运行时间数据,选取功耗最低,并满足运行时间要求的存储方案,作为最终串行块部署方案。
19、本发明通过对多输入神经网络模型在结构上进行了优化,在此结构的基础上提出了一种串行块的存储和推断方法,从而优化多输入神经网络模型的运行功耗和算力要求。在同等功耗和算力要求下,嵌入式设备可以部署更大规模的多输入神经网络模型,以提升模型的可配置性和泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!