非负右偏时间序列的模式识别与预测方法
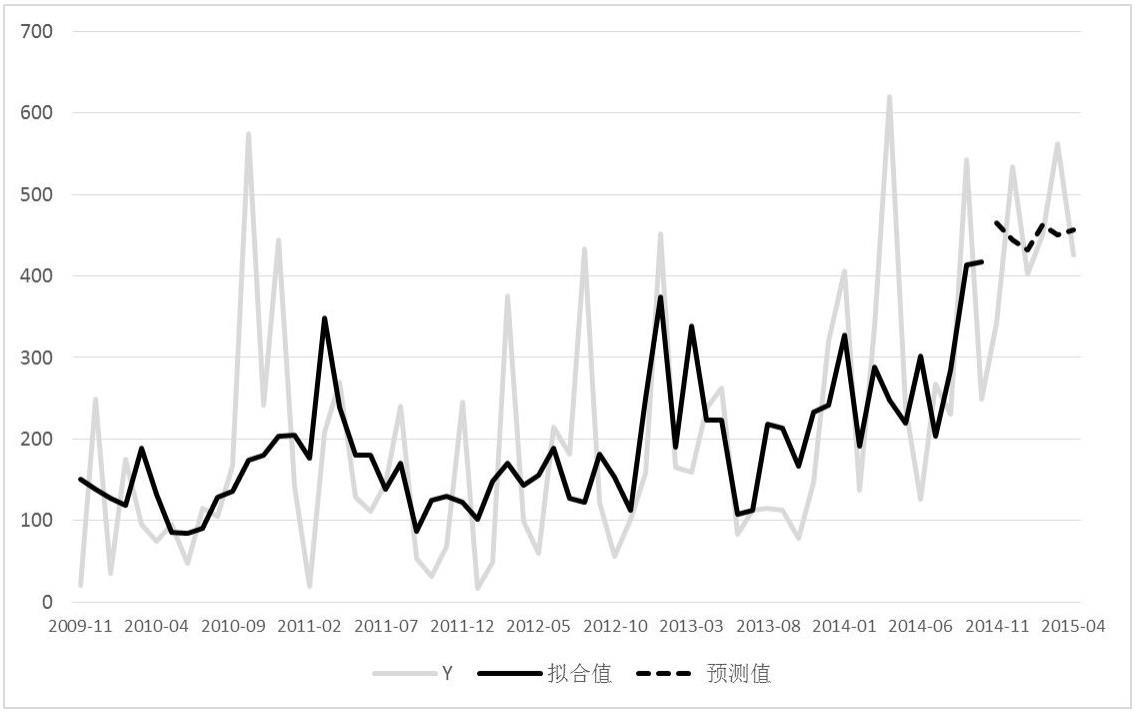
本发明涉及数据处理,具体为非负右偏时间序列的模式识别与预测方法。
背景技术:
1、目前时间序列的预测方法,是借助序列发展的延续性,通过对过去的规律进行分析,进行模式的识别,在此基础上对未来的趋势进行预测,现阶段的主要方法普遍是针对具有正态分布的数据进行的研究,对分布不符合正态分布的数据进行变换,使其满足正态分布的要求后再进行分析和预测,存在着方法不统一,效果不直观和对数据处理后信息不完全等问题。
2、在时间序列的数据中,很多数据具有非负和右偏的特征,传统的时间序列分析中,针对此类数据的分析方法多是采用取对数的方式再进行分析,导致其在分析和预测过程中存在着不直观的问题。本发明针对一类常见特殊的非正态(非负右偏)时间序列数据,提供了非负右偏时间序列的模式识别与预测方法
技术实现思路
1、针对现有技术的不足,本发明提供了非负右偏时间序列的模式识别与预测方法,针对非正态时间序列数据进行定制化的分析和预测,为解决经济管理、医学分析和生物统计等方向的类似时间序列的分析和预测问题提供算法工具的支持。
2、为实现以上目的,本发明通过以下技术方案予以实现:一种非负右偏时间序列的模式识别与预测方法,包括以下步骤:
3、步骤一、针对数据所具有典型的非负和右偏特征,采用了tweedie分布作为模式识别和预测的基础模型,并引入随机效应来刻画个体效应与序列的相关性;
4、步骤二、通过对分布函数中的参数进行迭代算法的计算,得到相应的参数值,然后,再对协变量进行预测,结合模式识别过程的参数值给出预测值;在模式识别部分,分两步算法进行参数的初值估计和迭代更新,得到参数值;在预测部分,分两步算法先对协变量x进行预测,再对因变量y进行预测。
5、优选的,所述步骤一中,引入了随机效应u来刻画个体效应与序列的相关性, u=(u1,u2,…,un); 其中n为时间序列的时间点,包括日、周和月等,ut代表时间序列在t时间点的随机效应,ut的期望给定为1,ut的方差为τ2 , ui和uj分别为时间序列在i和j时间点的随机效应,ui和uj的相关系数记为ρ|i -j|,τ和ρ需要通过对数据的分析进行计算获取;
6、y作为模式识别和预测的时间序列对象,记为y=(y1,y2,…,yn),x是协变量,记为x=(x1,x2,…,xn),yt的条件分布函数为公式:
7、 (1)
8、其中,μt=,为t时间点的协变量,为回归参数,μt为t时刻yt的均值,q是tweedie分布中的超参数,用来控制其对应不同的分布,q需大于2,满足对非负右偏时间序列的特征刻画,是分散度参数,用来刻画数据的分布特征,ut代表时间序列在t时间点的随机效应,是时间序列在t时间点的值,是根据来确定的满足tweedie分布的参数值,需要通过对数据的分析进行计算获取。
9、优选的,步骤二具体包括:
10、第一步、迭代初始值确定
11、使用gamma回归模型获得的初值,并对其他参数进行迭代初始值赋值:
12、u=y/[n×(y1+y2+…+yn)];τ2=|(u-1)|2 /n;ρ*=0.5;=1;μ=;
13、μ为(μ1, μ2,…, μn),是 (y1,y2,…,yn)的均值向量;
14、第二步、循环迭代更新参数
15、1)更新参数向量:
16、回归参数向量的迭代过程中,首先假定随机效应是已知情况下进行计算,后续通过替换随机效应为其最佳线性无偏预测后,得到对的无偏估计;
17、=-inv(-diag(μx)'×inv(y)×diag(μx))× diag(μx)'×inv(var(y))×(y-μ) (2)
18、其中,
19、diag是指生成对角矩阵,inv是对矩阵求逆,var是计算方差;
20、是第一步中获取的初始值;
21、var(y)=×diag(μ)p+ diag(μ)× var(u) × diag(μ),
22、var(u)是ρ和τ2的张量积;
23、ρ是元素如下的矩阵:
24、ρ(i,j)= ρ* (j-i),i=1:(t-1) j =(i+1):t;
25、ρ(i,j)= ρ* (j,i),i=2:t j=1:(i-1);
26、ρ(i,j)=1, i=j;
27、至此,参数向量的更新完毕;
28、2)随机效应参数τ2和算法:
29、随机效应部分的相关参数有τ2和,使用最佳线性无偏预测方法进行计算获取;
30、τ2=mean|u-1|2+(τ*)2-mean(diag(cov(u))) (3)
31、=mean(((y-μu)2+(μ2×τ2-(μ2)×diag(cov(u)))/(μp))(4)
32、其中,cov(u)=var(u)×diag(μ)×inv(var(y))×diag(μ) × var(t)
33、t是t行1列的单位向量;
34、u=t+var(t)×diag(μ) × inv(var(y))×(y-μ);
35、mean是求平均值;
36、至此,随机效应参数τ2和计算完毕;
37、3)相关系数ρ的估计算法:
38、模型中引入自回归模型ar(1)作为序列相关性结构的刻画,使用矩法估计进行计算;
39、ar(1) 模型具体形式为 = b0+b1+εt+1
40、其中,是在t+1时间点u的值,代表时间点t时间点u的值;b0、b1分别是ar(1)模型的待估参数,εt+1是t+1时间点的误差项;
41、 (5)
42、其中,,cov是求协方差,是最佳线性无偏估计得到的随机效应数值;
43、至此,相关系数ρ计算完毕;
44、第三步、检查循环的收敛性,确定各参数迭代循环完毕
45、此部分是对上述1)至3)步骤算法迭代是否终止进行判定,将迭代过程中新输出的参数β、τ2、ρ和的数值与上一组输出数值的差值求平方和后,与终止循环给定的阈值(给定的一个充分小的正数)进行比较,直到小于阈值后终止循环,给出的输出参数值作为最终的参数值,至此模式识别算法部分完成;
46、在模式识别完成后,对协变量使用自回归模型进行预测,并带入估计的模式识别算法给出的参数值,进行预测值的估计;
47、1)自回归模型进行协变量预测:自回归模型ar(n)是通过使用时间序列的前n期的数据对当期的数据进行预测的模型,使用ar(n)模型判断自变量的相关关系,并用其对自变量进行预测:
48、ar(n) 模型具体形式为 xm= α0+α1xm-1+α2xm-2…αi xm-n+εm (6)
49、其中,xm是在m时间点自变量的值,xm-1、xm-2和xm-n分别代表时间点m-1、m-2和m-n时间点自变量的值;α0、α1和αn分别是ar(n)模型的待估参数,εm是m时间点的误差项;
50、2)使用tweedie分布对y进行预测:使用公式(1),引入预测协变量,使用模式识别过程给出的分布参数计算出y的预测值。
51、本发明提供了非负右偏时间序列的模式识别与预测方法。具备以下有益效果:
52、1、本发明通过借助具有随机效应的tweedie分布,给出针对具有非负右偏特征的时间序列进行模式识别和趋势预测的算法,达到对其发展趋势进行预测的效果,为后续针对非负右偏特征的时间序列的预测提供算法工具支持。
53、2、通过给出针对具有非负右偏特征的时间序列进行模式识别和预测的分析,给出了相应的具体算法和案例,为解决经济管理、医学分析和生物统计等方向的时间序列分析和预测问题提供算法和案例的支持。
- 还没有人留言评论。精彩留言会获得点赞!