一种基于自适应学习技术的狭窄场景轨迹生成方法与流程
本发明属于智能汽车自动驾驶,具体涉及到一种基于自适应学习技术的狭窄场景轨迹生成方法。
背景技术:
1、近年来,随着多种类型的传感器成本降低、感知检测算法的智能化以及底盘线控技术的普及,自动驾驶技术越来越多的在普通乘用车和商用车上得到了应用,轨迹规划是自动驾驶系统中不可或缺的模块之一,在整个自动驾驶系统中,承担了承上启下的作用,该模块需要接收上游的所有环境输入,再综合决策后计算出安全、高效、舒适的行车轨迹,之后控制执行机器跟踪该轨迹从而完成自动驾驶任务。
2、现有的自动驾驶轨迹规划技术主要有以下几类:1.基于搜索与采样的算法,以open space场景的hybrid a star以及结构化道路的lattice planner算法应用最为广泛;2.基于曲线拟合的算法,主要是基于圆弧、螺旋线、多项式曲线、b样条曲线等方式来生成轨迹;3.基于数值优化的算法,主要是构造优化函数以及约束来生成最优轨迹;4.基于深度学习强化学习的数据驱动的方法。
3、上述不同的轨迹算法都在目前的大多数自动驾驶系统中得到了应用或者尝试,也在过去的一段时间内解决了大量自动驾驶任务中轨迹生成的任务。然而,上述的几种方法仍然存在一定的局限性,主要体现在如下几个方面:1.基于采样和搜索的算法存在算力消耗不稳定、轨迹帧间连续性较差、多维搜索较耗时等问题;2.基于曲线拟合的算法,需要在不同场景下维护多套曲线生成算法和参数,例如圆弧直线螺旋线在泊车场景中对不同起始位置、轨迹段数等都需要不同的处理;3.基于数值优化的算法,大多需要先找出一个可行的凸空间来求解,同时在障碍物复杂场景较为耗时;4.基于深度学习的end-to-end算法存在可解释性差,安全性难以保证的问题;另外,前3种算法还普遍存在生成的轨迹拟人化差的情况,部分场景虽然能完成任务却不能像人类司机一样智能,诸如在泊车场景存在轨迹换挡点位置不合理,生成多余的换挡轨迹等问题。
技术实现思路
1、针对上述问题,本发明的主要目的在于设计一种基于自适应学习技术的狭窄场景轨迹生成方法,综合考虑了传统轨迹生成算法稳定、可靠以及深度学习算法,解决园区、泊车等狭窄场景下轨迹规划过程中,智能化、拟人化差的问题。
2、为了实现上述目的本发明采用如下技术方案:
3、一种基于自适应学习技术的狭窄场景轨迹生成方法,该方法包括离线训练步骤和在线轨迹生成步骤;
4、所述的离线训练步骤包括:
5、步骤1:自车及环境数据获取;包括自车状态数据、环境数据信息、历史状态累积信息;
6、步骤2:针对步骤1获取的数据信息进行特征提取;
7、步骤3:根据步骤2提取的特征数据,通过轨迹生成模型得到轨迹生成的参数,并得到车辆的轨迹点;
8、步骤4:基于步骤3生成的轨迹点结合专家驾驶数据,进行车辆轨迹点的优化;
9、所述的在线训练步骤包括:
10、步骤5:加载步骤3轨迹生成模型中训练好的参数,根据步骤1的数据输入,在固定时间步通过步骤3的轨迹参数,生成行车轨迹。
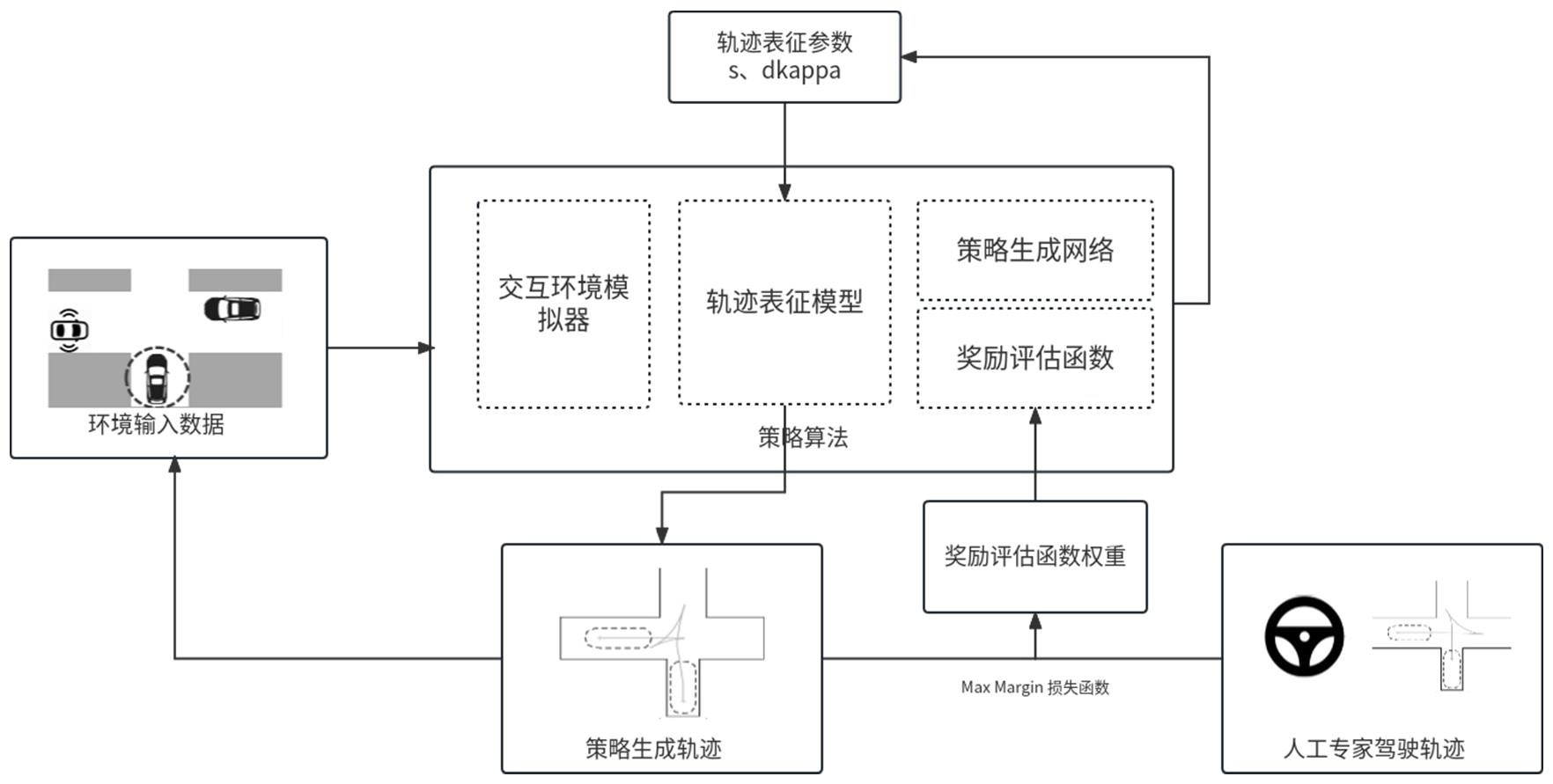
11、作为本发明进一步的描述,步骤1中,所述的自车状态数据,包括车辆位置、速度、加速度、方向盘转角、油门刹车、档位中的一种或多种;
12、所述的环境数据包括地图信息、动态障碍物信息;
13、所述的地图信息包括车道边界、库位边界、停车线中的一种或多种;所述的动态障碍物信息包括障碍物的位置、速度、轮廓信息中的一种或多种;
14、所述的历史状态累积信息,包括当前档位方向累计行驶距离、累计换挡次数中的一种或多种。
15、作为本发明进一步的描述,步骤2中,对于自车状态数据和历史状态累积信息,使用普通数据归一算法组成1*n维的向量s;
16、对于动态障碍物信息和地图信息,使用图神经网络的算法表达几何边界信息。
17、作为本发明进一步的描述,步骤3中,所述轨迹生成模型的构建包括:simulator模块、策略生成网络模型、轨迹表征模型、奖励评估模块;
18、根据步骤2提取的特征数据,通过策略生成网络模块和奖励评估模块得到轨迹生成的参数,将该参数输入到满足车辆运动学约束的轨迹表征模块得到车辆轨迹点。
19、作为本发明进一步的描述,所述的simulator模块为交互环境模拟器,基于简化的单车模块对自车状态数据、环境数据信息进行更新,得到固定时间完整的轨迹点;
20、更新的微分方程为:
21、
22、其中,x(t),y(t),θ(t)分别表示车辆位置和朝向,v(t)表示车辆速度,表示前轮转角,a(t)表示加速度,lw表示车辆轴距,ω(t)表示前轮转角速率,jerk(t)表示加速度关于时间变化率。
23、作为本发明进一步的描述,所述的策略生成网络模型使用ppo连续行为空间强化学习算法,其包含一个策略网络和一个评估网络计算策略梯度,通过梯度下降算法训练更新网络参数,得到使得累积奖励最大的策略参数;
24、即:输入t时刻的环境数据信息,输出轨迹参数s和dkappa,其中s表示当前轨迹点累积长度,dkappa表示当前点处的曲率关于s的变化率。
25、作为本发明进一步的描述,所述的轨迹表征模型使用螺旋线模型,通过输入参数s和dkappa,进行输出满足车辆动力学的轨迹点,并将该轨迹点输入所述的simulator模块进行执行,更新自车状态数据及环境数据信息。
26、作为本发明进一步的描述,所述满足车辆动力学的轨迹点加快输出为通过基准螺旋线查表,并通过缩放的方式进行轨迹点的螺旋线计算,具体步骤包括:
27、步骤3.1:根据菲涅尔积分计算单位坐标系下的螺旋基准点,并保存到磁盘中,表示为:
28、p=[x,y,theta,kappa,dkappa];其中,x,y为轨迹点坐标,theta为车辆在该轨迹点处的朝向,kappa为该轨迹点处的曲率,dkappa为该轨迹点处曲率变化率;
29、步骤3.2:针对缩放后的螺旋线点查表,给定当前的start_point以及需要外推的ds;其中,start_point=[x,y,theta,s,kappa,dkappa];
30、步骤3.3:找到当前start_point对应下标的基准点,并根据kappa算出缩放因子,得到非基准点的位置,即得出固定时间下的螺旋线。
31、作为本发明的进一步描述,所述的奖励评估模块基于所述simulator模块的更新结构评估当前轨迹的优劣并计算cost值;
32、其中,奖励函数包括用于目标引导的costgoal、用于表示轨迹平滑程度的costsmooth、用于表示历史状态累积信息的costlegacy、用于惩罚与环境发生碰撞行为的costcollision、以及为了避免车辆不动的单步存活奖励与完成目标的奖励costrl;
33、上述cost由权重项参数加权组合得到最终cost,计算方式为:
34、cost=wgoal*costgoal+wsmooth*costsmooth+wlegacy*costlegacy+wcollision*costcollision+wrl*costrl
35、coskgoal=wpose*δpose+wheading*|δheading|
36、costsmooth=wkappa*||δkappa||2+wdkappa*||δkappa||2
37、
38、其中,wgoal,wsmooth,wlegacy,wcollision,wrl分别为costgoal,costsmooth,costlegacy,costcollision,costrl的权重;
39、δpose为t+1时刻车辆位姿(xt+1,yt+1)与目标位姿(xgoal,ygoal)的误差减去t时刻车辆位姿(xt,yt)与目标位姿(xcoal,ycoal)的误差;
40、δheading为t+1时刻车辆位姿(xt+1,yt+1)与目标位姿(xgoal,ygoal)的误差减去t时刻车辆位姿(xt,yt)与目标位姿(xcoal,ycoal)的误差;
41、δkappa表示轨迹点的曲率变化量,为t+1时刻曲率kappat+1减去kappat;
42、δdkappa表示轨迹点曲率变化率的变化量,为t+1时刻曲率dkappat+1减去dkappat;
43、wkappa和wdkappa分别表示轨迹点曲率和轨迹点曲率变化率项cost的权重。
44、dist为车辆t时刻到障碍物的最近距离,d为碰撞安全阈值。
45、作为本发明进一步的描述,步骤4中,所述的轨迹参数优化为奖励评估模型参数优化过程,优化方式为:基于专家驾驶轨迹数据和步骤3中策略生成网络模型的轨迹参数,通过max-margin损失函数训练奖励函数的权重参数,损失函数表示如下:
46、
47、其中,τh,i表示第i条专家驾驶轨迹数据,τ为步骤3策略算法生成的轨迹数据,f函数为关于轨迹cost的线性函数,w为奖励函数中的权重参数,n为训练轨迹的总条数。
48、相对于现有技术,本发明的技术效果为:
49、本发明提供了一种基于自适应学习技术的狭窄场景轨迹生成方法,使用同一套策略生成网络模型,可以适用于不同的场景,且训练完成后只需要保存一套网络参数,整个算法更简洁易于维护;同时,该算法仅仅需要通过网络来学习两个轨迹表征参数,大大的降低了网络模型的参数量和训练难度,并增强了轨迹生成算法的可解释性与可靠性,保证了生成轨迹满足车辆运动学约束;另外,在策略生成网络模型训练过程中,引入了专家驾驶数据训练奖励函数权重,不仅极大的降低了奖励函数调参的难度,同时随着训练数据的丰富,算法生成的轨迹特性将吸取专家驾驶的驾驶经验,同时也不失去对新场景的泛化能力,使得生成的轨迹更加拟人化、智能化。
- 还没有人留言评论。精彩留言会获得点赞!