一种集装箱堆场预倒箱方法
本发明涉及集装箱堆场控制,尤其是涉及一种集装箱堆场预倒箱方法。
背景技术:
1、随着水路运输的快速发展,港口的集装箱吞吐量飞速上升,导致堆场堆放的集装箱越来越多,而集装箱堆场在有效衔接岸边操作、水平运输、进出闸口等操作方面具有中心枢纽的地位和作用,当堆场的翻箱率居高不下时,必然会对其他设备的运作以及港口效率产生影响。
2、受到堆场计划和码头不可控制随机因素影响等原因,堆场常会发生倒箱,预倒箱是将堆放错误的堆场进行复原,使得后续的内外集卡和船舶不再需要等待直接进行调取。集装箱堆场是一个很大的空间,进出港口中转和堆存大量的集装箱,集装箱堆场根据集装箱的不同属性分为若干个箱区,每个箱区包括多个贝位,每个贝位包含多个栈,每一个栈可以堆放多层集装箱。如图1显示在该箱区中有3个贝位,4个栈,3层高。在集装箱码头作业中,集装箱通常堆码一定的层数,如果当前所要取的集装箱被其他的集装箱压住,从而形成了阻碍箱、需要龙门吊进行操作,预倒箱作业是当码头的工作量较低时、在船舶到港之前,对箱区重新进行堆放,以减少压箱现象。这一预倒箱的过程将减少船舶到港后的等待时间,减少龙门吊和集卡的能源消耗。图2是一集装箱堆场箱区的俯视图,体现了集卡、龙门吊和集装箱之间的相互关系。一个集装箱场站由若干个贝(bay)组成,对于每个给定的集装箱贝位的初始布局来说,单贝位集装箱预倒箱作业可以描述成对单贝位内的集装箱进行重新排列,使其最终布局符合所有先取走的集装箱在后取走集装箱的上面的标准,初始布局和最终布局如图3所示,图3a为初始布局,图3b为最终布局,集装箱的数字代表集装箱提取的优先级批次。
3、现有技术中,对于集装箱预倒箱问题的求解,主要在精确算法和启发式算法两方面进行了广泛的研究。国外学者主要通过搜索集装箱位置以实现倒箱量优化。首先,kim等提出一种集装箱堆场的估计预期倒箱量的方法,指出平均倒箱量的关键因素,利用分支定界法和启发式规则针对不同的堆栈给出不同估计预期倒箱量。lee等提出以最小化倒箱量为目标的预倒箱问题的数学模型,并设计一种简单启发式方法求解。随后改进模型来预估编组集装箱的箱位,并设计了由三个子程序组成新启发式算法。huang等针对预倒箱问题分为不需要按特征分类和需要按特征分类的两种类型,并针对两种问题分别开发了启发式算法进行求解。
4、国内学者则主要通过压箱数量减少为优化通过启发式算法求解,部分通过精确算法。李浩渊等提出了预倒箱作业过程的数学规划模型,并设计了一种二元编码方式的多阶段遗传算法对该模型进行求解。金鹏等通过制定可等价替换抽象约束的箱位选取规则以最大程度保证装船系统的流畅性为约束条件,建立装船时贝内翻箱问题的优化模型。乐美龙等建立基于网络模型的集装箱翻箱模型对预倒箱问题进行优化。郑斯斯等通过对多种翻箱规则下的优先级进行排序建立了倒箱路径优化模型,并采用启发式算法求解。边展等开发了由邻域搜索算法与整数规划算法组成的两阶段混合算法对预倒箱问题进行优化。游鑫梦等考虑集装箱堆存作业与提取作业的关联性建立两阶段规划模型并运用遗传算法和启发式算法进行求解。
5、然而上述方案在实际应用中,由于求解时间较长、求解出预倒箱序列过长,导致存在堆场起重机移动频繁、内外集卡长时间等候和能源消耗等问题,使得预倒箱移动步数过多、集装箱堆场作业效率较低。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种集装箱堆场预倒箱方法,能够快速完成求解过程,得到最短的预倒箱序列,从而有效减少预倒箱移动步数、提高集装箱码头堆场作业效率。
2、本发明的目的可以通过以下技术方案来实现:一种集装箱堆场预倒箱方法,包括以下步骤:
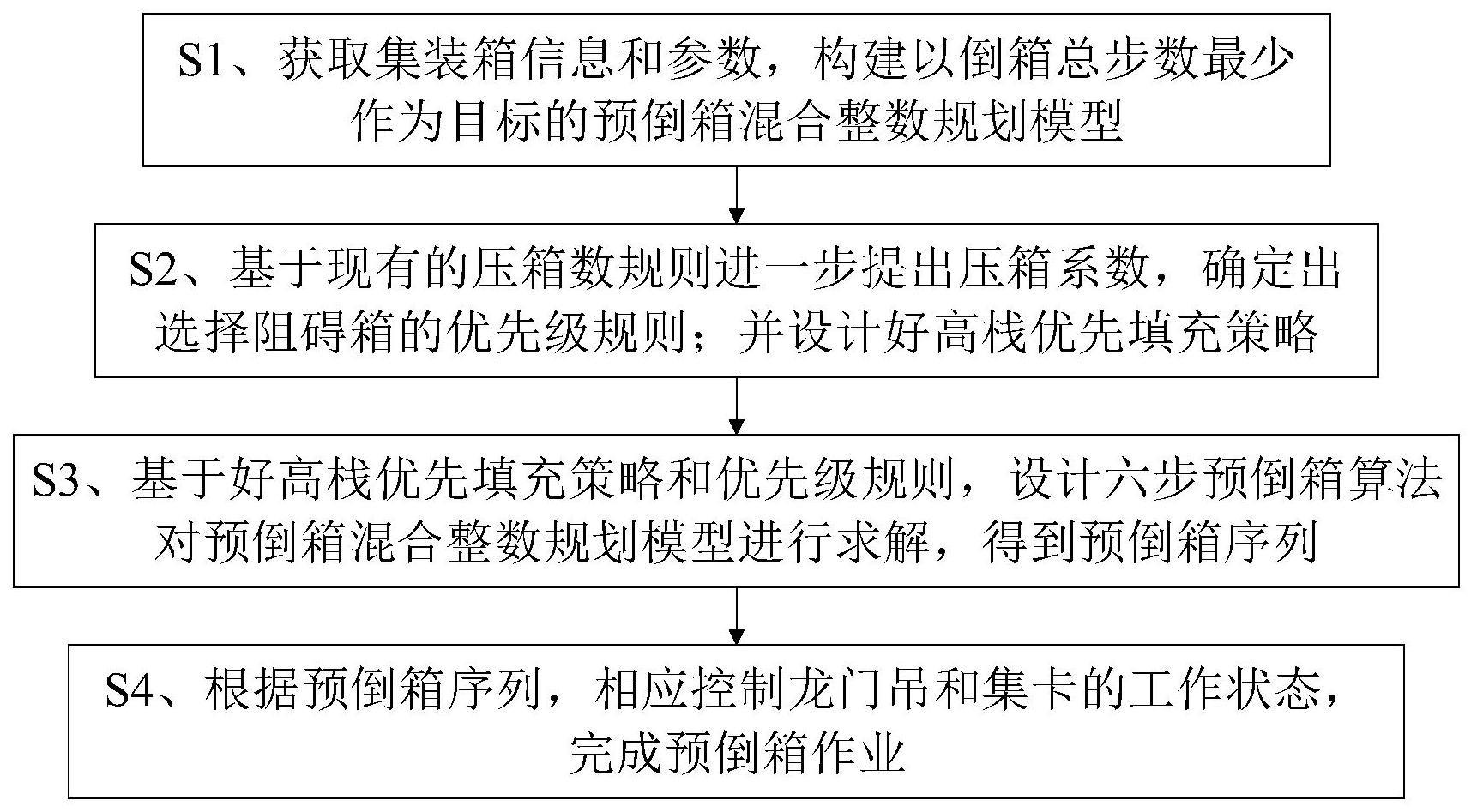
3、s1、获取集装箱信息和参数,构建以倒箱总步数最少作为目标的预倒箱混合整数规划模型;
4、s2、基于现有的压箱数规则进一步提出压箱系数,确定出选择阻碍箱的优先级规则;并设计好高栈优先填充策略;
5、s3、基于好高栈优先填充策略和优先级规则,设计六步预倒箱算法对预倒箱混合整数规划模型进行求解,得到预倒箱序列;
6、s4、根据预倒箱序列,相应控制龙门吊和集卡的工作状态,完成预倒箱作业。
7、进一步地,所述步骤s1中集装箱信息和参数包括但不限于装箱堆场基本指标,集装箱的贝、层、高的位置信息,每个集装箱的提取顺序信息;
8、所述步骤s1中构建预倒箱混合整数规划模型的具体过程为:
9、s11、确定模型基本假设:假设集装箱除优先级批次不同外都是相同的,即不考虑集装箱的箱号码和种类识别码等具体信息;另一方面,根据集装箱码头实际作业场景,设定集装箱预倒箱作业的理论前提;
10、s12、基于集装箱信息和参数,结合模型基本假设,以最少倒箱步数作为目标函数,建立预倒箱混合整数规划模型。
11、进一步地,所述步骤s11中集装箱预倒箱作业的理论前提包括:
12、(1)倒箱作业开始之前,所有集装箱的优先级批次均已知;
13、(2)不同优先级批次的集装箱分配到各贝位各栈的概率相同;
14、(3)在箱区布局中只有一台龙门吊进行作业且一次只能提取一个集装箱;
15、(4)单贝位内堆存的集装箱均为20英尺的标准箱;
16、(5)考虑龙门吊作业的安全性和使用周期,预倒箱作业限制在同一贝内进行;
17、(6)在进行单贝位预倒箱作业时不考虑进入新优先级批次的集装箱;
18、(7)提取集装箱和堆放集装箱的操作只发生在顶层箱位上,即集装箱不能悬空操作;
19、(8)考虑操作的安全性,当达到堆栈的限高不允许继续堆放集装箱。
20、进一步地,所述步骤s12中预倒箱混合整数规划模型包括目标函数和约束条件,所述约束条件包括第一约束~第七约束;
21、所述目标函数具体为:
22、minl
23、所述第一约束具体为:
24、
25、所述第二约束具体为:
26、
27、
28、l=1,2,…,l
29、所述第三约束具体为:
30、
31、x(l)∈{1,2,…,s},(l)∈{1,2,…,s}
32、所述第四约束具体为:
33、
34、所述第五约束具体为:
35、
36、所述第六约束具体为:
37、tx(l)(l)≥0,=1,2,…,
38、所述第七约束具体为:
39、ty(l)(l)≤h,=1,2,…,
40、其中,s为单贝位最大堆栈数,h为单贝位堆栈最高层数,g为集装箱的提箱批次优先级,ts(0初始堆存状态下第s栈的集装箱高度,ts(l)为第l次倒箱后第s栈的集装箱高度,为初始堆存状态下第s栈的自下往上第h层的集装箱的提箱批次优先级,为l次倒箱后第s栈自底向上第h层的集装箱位为空位,x(l)为决策变量,表示第l次倒箱的捐赠栈,y(l)为决策变量,表示第l次倒箱的接受栈,为0-1决策变量,表示若第l步倒箱优先级为的集装箱存在于捐赠栈x(l),则其值为1,否则为0,为0-1决策变量,表示若第l步倒箱优先级为的集装箱存在于接受栈y(l),则其值为1,否则为0;
41、l为总倒箱步数,第一约束表示最终布局状态下,该贝位中任意集装箱优先级批次都不会比这个上面集装箱的优先级批次小;第二约束表示每次翻箱作业只移动一个箱子,且只从捐赠栈到接受栈;第三约束表示对于已经移动走的集装箱,该箱位为空,对应优先级批次为0;捐赠栈移动走的集装箱优先级批次等于接受栈接收的集装箱优先级批次;其他集装箱优先级批次保持不变;第四约束表示在堆存集装箱过程中不能出现悬空操作;第五约束表示倒箱的过程中捐赠栈高度减一,接受栈高度加一,其他栈高度保持不变;第六约束表示捐赠栈的高度不会小于0;第七约束表示接受栈的高度不会超过限高层h。
42、进一步地,所述步骤s2中压箱系数具体包括:
43、集装箱的压箱系数定义为ksh(l):第l次倒箱后,压箱数和集装箱栈可堆放箱位数的乘积,其计算公式为:
44、ksh(l)=psh(l)×nsh(l)
45、psh(l)=|ts-h|+1
46、其中,nsh(l)为压箱数,是指第l次倒箱后,一个堆栈s中,第h层的集装箱批次优先级大于下面的集装箱批次优先级的个数和;
47、psh(l)为集装箱栈可堆放箱位数,是指第l次倒箱后,一个堆栈s中,第h层的集装箱移走后堆栈s可堆放的空箱位;
48、之后定义在第l次倒箱后,一个栈s压箱系数为该栈所有集装箱的压箱系数之和,记为ks(l):
49、
50、再定义在第l次倒箱后,一个贝位的压箱系数为该贝位所有堆栈的压箱系数之和,记为k(l):
51、
52、由此利用上述压箱系数描述出当前栈或贝的压箱程度和空箱位多少。
53、进一步地,所述步骤s2中好高栈优先填充策略具体是针对不同单贝位预倒箱的分类,采取先填充好高栈、再填充好低栈、之后填充空栈、最后清空低栈并循环至坏栈为0的策略。
54、进一步地,所述步骤s3中六步预倒箱算法的具体过程为:
55、第一步、标记
56、第一步是对贝位的每一堆栈进行标记,以便能够识别每一堆栈的条件,设w表示堆栈排列不正确的堆栈集合,wd表示堆栈排列不正确的坏低栈的集合;r表示堆栈排列正确的堆栈集合,rd表示堆栈排列正确的好低栈的集合,rc表示堆栈排列正确的好高栈的集合,rm表示堆栈排列正确的达到限高h的好满栈的集合,e表示堆栈箱位为空的堆栈集合;
57、第二步、填充好高栈
58、这一步是对好高栈rc进行填充,以便减少压箱数和预留出更多的空箱位,即摆放正确的栈rc上所有空位,通过选择除了rm栈的其他栈的最顶层集装箱相同批次优先级或批次优先级更高的集装箱填充,直到达到限高,形成新的rm栈;
59、第三步、填充好低栈
60、这一步是对好低栈rd进行填充,以便减少压箱数和预留出更多的空箱位,即摆放正确的栈rd上所有空位,通过选择除了rm栈的其他栈的最顶层集装箱相同批次优先级或批次优先级更高的集装箱填充,直到形成新的rc栈;
61、第四步、填充空栈
62、这一步是对空栈e进行填充,以便减少压箱数和预留出更多的空箱位,即空栈e上所有空位,通过选择除了rm栈的其他栈的最顶层集装箱相同批次优先级或批次优先级更高的集装箱填充,直到形成新的rd栈;
63、第五步、清空低栈
64、这一步是对无法堆叠成rc堆栈的一个清空过程,在wd集合和rd集合中选择最低的堆栈,并选择与其他堆栈顶部集装箱批次优先级最接近的栈,如果出现超过一个的相同优先级时,移动到和更大那个栈,移动一步结束后对所有的堆栈进行重新标记,回到第一步,观察低栈清空的过程,如果在清空低栈的过程中出现好低栈rd则将重复第三步,如果没有出现则继续清空低栈,直至出现空栈e,然后进行重新标记,重复第四步;
65、第六步、终止求解
66、从第一步开始对所有堆栈进行标记,然后在每一次移动后重新标记,根据第二步、第三步对所有的好栈进行填充完毕,然后进行第四步填充空栈,接着在第五步清空低栈的过程中重新变成好低栈或者空栈则重复第二、三、四步,当w集合为0时,则求解终止,得到预倒箱序列,即得到一个正确摆放的最终贝位。
67、进一步地,所述第二步中填充好高栈的具体过程为:
68、(1)如果集合rc不为空,则取rc中高度最大的堆栈满足条件为好高栈的高度,β为一个在(0,1)之间可调整的系数;
69、(2)检查除了rm的所有集合,并选择堆栈顶部集装箱批次优先级,将顶部集装箱按照批次优先级从大到小的顺序移动到rc,每次移动一个集装箱时回到第一步对所有的堆栈重新标记,重复这个选择—移动过程,直到堆栈rc的高度达到h成为新的rm,当在除了rm的所有集合出现超过一个的相同优先级时,对于w集合选择堆栈压箱系数ks(l)最大的那个栈,对于rd集合移动最小的那个栈。
70、进一步地,所述第三步中填充好低栈的具体过程为:
71、(1)如果集合rd不为空,则取rd中高度最大的堆栈满足条件0为好低栈的高度;
72、(2)检查w的集合,并选择堆栈顶部集装箱批次优先级,将顶部集装箱按照批次优先级从大到小的顺序移动到rd,每次移动一个集装箱时回到第一步对所有的堆栈重新标记,重复这个选择—移动过程,观察堆栈rd的高度能否超过βh,如果能则继续移动直到堆栈rd的高度大于βh成为新的rc,然后重复第二步;如果不能则继续移动直到没有集装箱可以从w移动到rd,然后回到第一步对所有堆栈进行重新标记。
73、进一步地,所述第四步中填充空栈的具体过程为:
74、(1)如果集合e不为空,则取距离捐赠栈x(l)最近的空栈,满足条件he=0,he为空栈的高度;
75、(2)检查除rm栈的所有集合,并选择堆栈顶部集装箱批次优先级,将顶部集装箱按照批次优先级从大到小的顺序移动到e,每次移动一个集装箱时回到第一步对所有的堆栈重新标记,重复这个选择—移动过程,直到堆栈e的高度达到0he≤βh成为新的rd栈,然后重复第三步,当在除了rm的所有集合出现超过一个的相同优先级时,对于w集合选择堆栈压箱系数ks(l)最大的那个栈,对于rd集合移动hrd最小的那个栈,然后对所有堆栈进行重新标记。
76、与现有技术相比,本发明具有以下优点:
77、一、本发明建立以总倒箱步数最少为目标的预倒箱混合整数规划模型,并基于现有的压箱数规则提出压箱系数,利用提出的压箱系数来设计新的优先级规则,并设计好高栈优先填充策略,由此设计出一种鲁棒性更优的六步预倒箱算法,用于对预倒箱混合整数规划模型进行求解,针对预倒箱这类np难问题,能够快速进行求解,并且确保求解出最短的预倒箱序列,从而有效减少预倒箱移动步数、有效提高集装箱码头堆场作业效率。
78、二、本发明基于预倒箱作业约束和作业规则,通过模型基本假设、定义相关决策变量,以最少倒箱步数作为目标函数,由此建立出一种非线性混合整数规划模型,确保了预倒箱模型的准确性,有利于后续求解结果的可靠性。
79、三、本发明提出压箱系数的定义,利用压箱系数描述当前栈或贝的压箱程度和空箱位多少,进而利用集装箱的压箱系数来设计优先级判定规则,能够很好地完善选择阻碍箱的规则。
80、四、本发明通过对栈的好坏和高低进行定义,提出一种好高栈优先填充策略,并由此设计六步预倒箱算法,能够全面考虑到不同的单贝位预倒箱问题,并进行针对性地进行处理,从而在确保减少堆错箱的同时减少倒箱步骤。
- 还没有人留言评论。精彩留言会获得点赞!