一种鲁棒的增量行为识别模型建立方法及装置
本发明涉及计算机视觉技术,尤其涉及一种鲁棒的增量行为识别模型建立方法及装置。
背景技术:
1、行为识别是计算机视觉的一个重要的应用,广泛应用于人机交互、自动驾驶、智能监控以及医疗保健等领域。在医疗监护领域,通过该技术可实现对患者的实时监控,确保患者能够得到及时治疗和帮助。
2、现有人体行为识别的工作大多围绕固定类别开展研究。然而,在实际应用场景中,新的视频类别不断出现。例如,在抖音等视频平台上每天有数百万的短视频由用户上传,它们中的一部分视频属于新的类别或者拥有新的标签,所以行为识别的模型需要去适应新类。但现有的行为识别模型面对增量类别时,常常会出现“灾难性遗忘”,即在新的数据集上训练模型,会遗忘掉在旧数据上学到的知识。
3、增量学习(也称持续学习)可以模仿人类具有能够不断地处理现实世界中连续的信息流,在吸收新知识的同时保留甚至整合、优化旧知识的能力。增量学习目前主要的研究内容是图像分类,但在视频行为识别领域没有充分探索。视频数据相比较图像多一个时间维度,它的样本量更大,计算复杂度更高。所以,将行为识别跟增量学习结合起来可以极大提高该技术在生产生活中的实用性,具有十分广阔的应用前景。
技术实现思路
1、发明目的:本发明针对现有技术存在的问题,提供一种基于视频学习的鲁棒的增量行为识别模型建立方法及装置。
2、技术方案:本发明所述的鲁棒的增量行为识别模型建立方法包括:
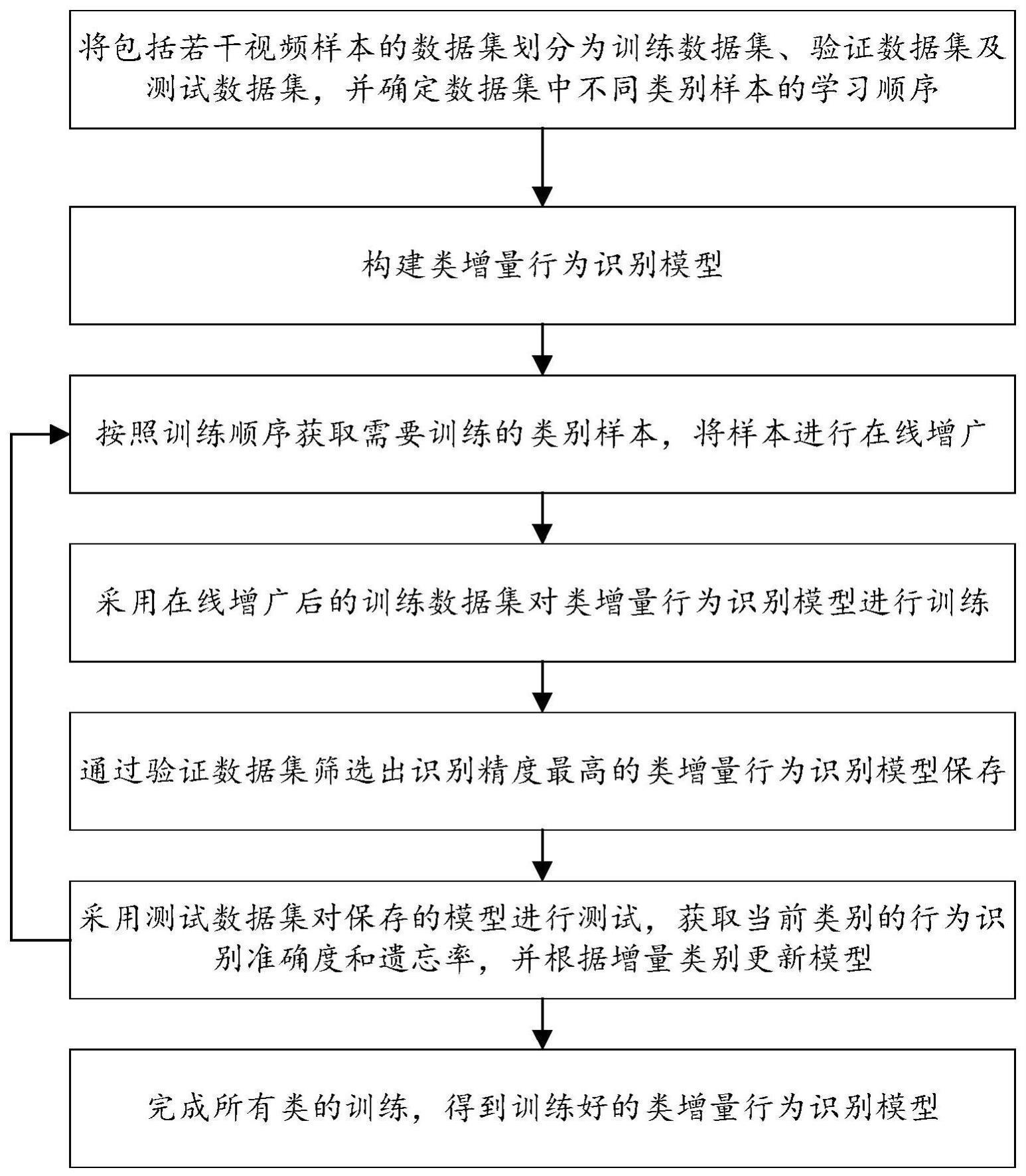
3、步骤s1:将包括若干视频样本的数据集划分为训练数据集、验证数据集及测试数据集,并确定数据集中不同类别样本的训练顺序;
4、步骤s2:构建类增量行为识别模型;
5、步骤s3:按照训练顺序获取需要训练的类别样本,将样本进行在线增广;
6、步骤s4:采用在线增广后的训练数据集对类增量行为识别模型进行训练,训练时,如果训练的样本属于旧类,则根据对应标签生成正相关的软标签进行自纠正损失计算,如果训练的样本属于新类,则从属于旧类的样本中选择若干代表性样本,并从代表性样本中选取若干关键帧,将这些关键帧与属于新类的样本构成新类训练数据集样本进行训练;所述旧类为之前已经识别到的类别,所述新类为还未识别到的类别;
7、步骤s5:通过验证数据集筛选出识别精度最高的类增量行为识别模型保存;
8、步骤s6:采用测试数据集对保存的模型进行测试,获取当前类别的行为识别准确度和遗忘率,并根据增量类别更新模型;
9、步骤s7:返回执行步骤s3,直至完成所有类的训练,得到训练好的类增量行为识别模型。
10、进一步的,所述步骤s1中,所述确定数据集中不同类别样本的学习顺序,具体如下:从数据集中选择任一已确定类别的一类视频样本作为基类,进行第一个训练,剩余类别的视频样本作为增量类,进行后续训练。
11、进一步的,所述步骤s2中,所述类增量行为识别模型包括特征提取器和分类器,其中,所述特征提取器用于从输入的样本中提取特征,具体为预训练网络,所述分类器用于将特征提取提取的特征进行分类。
12、进一步的,所述步骤s3中,在线增广的方法具体如下:
13、步骤s3-1:如果当前阶段为基类训练阶段,则将该样本的视频帧沿时间维度进行相同的裁剪,裁剪空间分辨率大小为h×w,其中h和w分别为空间分辨率的高和宽;如果当前阶段属于增量类训练阶段,则对将该样本的视频帧沿时间维度进行相同的裁剪,裁剪空间分辨率大小为(ah)×(aw),0<a≤1;其中,对基类的训练阶段为基类训练阶段,对增量类的训练阶段为增量训练阶段;
14、步骤s3-2:将样本的视频帧沿时间维度进行相同的随机水平翻转。
15、进一步的,所述步骤s4中,采用在线增广后的训练数据集对类增量行为识别模型进行训练的方法包括:
16、步骤s4-1:设置训练参数,如果当前阶段为基训练阶段,对类增量行为识别模型进行随机初始化,如果是增量训练阶段,则直接采用之前训练得到的网络参数进行初始化;
17、步骤s4-2:如果当前样本属于新类,则从属于旧类的样本中选择若干代表性样本,并从代表性样本中选取若干关键帧,将这些关键帧与属于新类的样本构成新类训练数据集样本;否则执行步骤s4-3;
18、步骤s4-3:将样本的视频平均分段后对每个片段随机采样,特征提取器对将采样的视频帧进行特征提取;
19、步骤s4-4:分类器对步骤s4-3所提取的特征进行分类;
20、步骤s4-5:利用交叉熵损失进行损失计算;
21、步骤s4-6:如果当前样本属于旧类,则根据对应标签生成正相关的软标签进行自纠正损失计算;否则直接执行步骤s4-7;
22、步骤s4-7:结合步骤s4-5和步骤s4-6所计算的损失,对网络参数进行优化。
23、进一步的,所述步骤s4-6中,根据对应标签生成正相关的软标签进行自纠正损失计算的方法包括:
24、采用下式根据对应标签生成正相关的软标签:
25、
26、式中,表示样本x的软标签,θt表示样本x的标签,α∈(0,1]是正则化因子,是与相同维度的校准输入,的取值范围在0到1之间,t表示当前迭代次数;
27、根据软标签进行自纠正损失计算:
28、
29、式中,表示自纠正损失,ot-1代表属于旧类的样本,o(x)表示旧类样本网络预测的输出,σ(·)表示sigmoid运算。
30、进一步的,所述步骤s4-2中,所述代表性样本通过利用herding算法选择。
31、进一步的,所述步骤s4-2中,所述关键帧的选取方法为:
32、对代表性样本按照下式计算每帧的差异性程度值cy(i),若cy(i)≥β,则将当前帧作为关键帧,β是给定的阈值:
33、
34、式中,cy(i)表示第i帧的差异性程度值,γ是一个超参数,0<γ≤1,j代表上一关键帧后下一帧的索引,f(·)为表征函数,v·表示第·帧,t表示当前帧所属视频总帧数。
35、进一步的,所述步骤s6中,根据增量任务类别更新模型的方法具体为:
36、利用上一训练阶段分类器的参数来更新下一增量训练阶段分类器中旧类分类头的权重和偏置,并根据后续增量的类别数增加分类器的维度。
37、本发明所述的鲁棒的增量行为识别模型建立装置,包括处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述方法。
38、有益效果:本发明与现有技术相比,其显著优点是:本发明基于视频进行增量行为识别,有效地避免知识复现时的蒸馏策略,降低计算量的同时增强网络的增量性能,在准确率、遗忘率和不同增量阶段平均准确率均取得了非常好的性能;软标签生成稳定而准确,可有效避免增量网络遭受教师网络不正确预测的干扰,进一步通过自纠正损失函数有效指导教师网络回顾旧知识。
技术特征:
1.一种鲁棒的增量行为识别模型建立方法,其特征在于包括:
2.根据权利要求1所述的鲁棒的增量行为识别模型建立方法,其特征在于:所述步骤s1中,所述确定数据集中不同类别样本的学习顺序,具体如下:
3.根据权利要求1所述的鲁棒的增量行为识别模型建立方法,其特征在于:所述步骤s2中,所述类增量行为识别模型包括特征提取器和分类器,其中,所述特征提取器用于从输入的样本中提取特征,具体为预训练网络,所述分类器用于将特征提取提取的特征进行分类。
4.根据权利要求1所述的鲁棒的增量行为识别模型建立方法,其特征在于:所述步骤s3中,在线增广的方法具体如下:
5.根据权利要求1所述的鲁棒的增量行为识别模型建立方法,其特征在于:所述步骤s4中,采用在线增广后的训练数据集对类增量行为识别模型进行训练的方法包括:
6.根据权利要求5所述的鲁棒的增量行为识别模型建立方法,其特征在于:所述步骤s4-6中,根据对应标签生成正相关的软标签进行自纠正损失计算的方法包括:
7.根据权利要求5所述的鲁棒的增量行为识别模型建立方法,其特征在于:所述步骤s4-2中,所述代表性样本通过利用herding算法选择。
8.根据权利要求5所述的鲁棒的增量行为识别模型建立方法,其特征在于:所述步骤s4-2中,所述关键帧的选取方法为:
9.根据权利要求1所述的鲁棒的增量行为识别模型建立方法,其特征在于:所述步骤s6中,根据增量任务类别更新模型的方法具体为:
10.一种鲁棒的增量行为识别模型建立装置,包括处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于:所述处理器执行所述程序时实现权利要求1-9中任意一项所述的方法。
技术总结
本发明公开了一种鲁棒的增量行为识别模型建立方法及装置,本发明首先构建类增量行为识别模型;将样本进行在线增广;然后采用在线增广后的训练数据集对类增量行为识别模型进行训练,训练时,如果训练的样本属于旧类,则根据对应标签生成正相关的软标签进行自纠正损失计算;之后通过验证数据集筛选出识别精度最高的类增量行为识别模型保存;最后采用测试数据集对保存的模型进行测试,获取当前类别的行为识别准确度和遗忘率,并根据增量类别更新模型;直至完成所有类的训练,得到训练好的类增量行为识别模型。本发明鲁棒性高、性能好。
技术研发人员:姜胜芹,方耀煜,刘青山
受保护的技术使用者:南京信息工程大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!