专有名词纠错方法、装置、设备及计算机可读介质与流程
本发明涉及自然语言处理,尤其涉及一种专有名词纠错方法、装置、设备及介质。
背景技术:
1、受限于目前的语音识别技术水平、用户自身的方言背景、以及输入法本身的识别技术水平,初始传入搜索引擎的query往往存在着同近音和近形字错误,例如,某些地方的方言背景的用户容易分不清”l”和“n”的发音,导致相应的近音字错误。另一方面,当用户需要检索某个专业领域的信息时,由于专有名词存在较多生僻字,普通用户在输入过程中容易输入更为熟悉和简单的同音近形字代替;同时,由于专有名词的字词组合方式较为罕见,用户难以完全记住,往往输入语序错误、或者具有多字缺字的错误query。
2、在现实应用中,专业领域信息的检索相较于通用领域的信息检索往往具有更低的容错度,在涉及法律、医疗等专业领域,错误的专业名词输入导致的错误检索结果轻则引发用户和平台之间的纠纷,重则会延误用户的求助和医疗救治。因此,亟需一种专有名词纠错方法,能够在用户输入错误时及时纠正,返回用户真正想要且准确的结果。
技术实现思路
1、本发明提供一种专有名词纠错方法、装置、设备及介质,其主要目的在于提升对专有名词纠错的准确率。
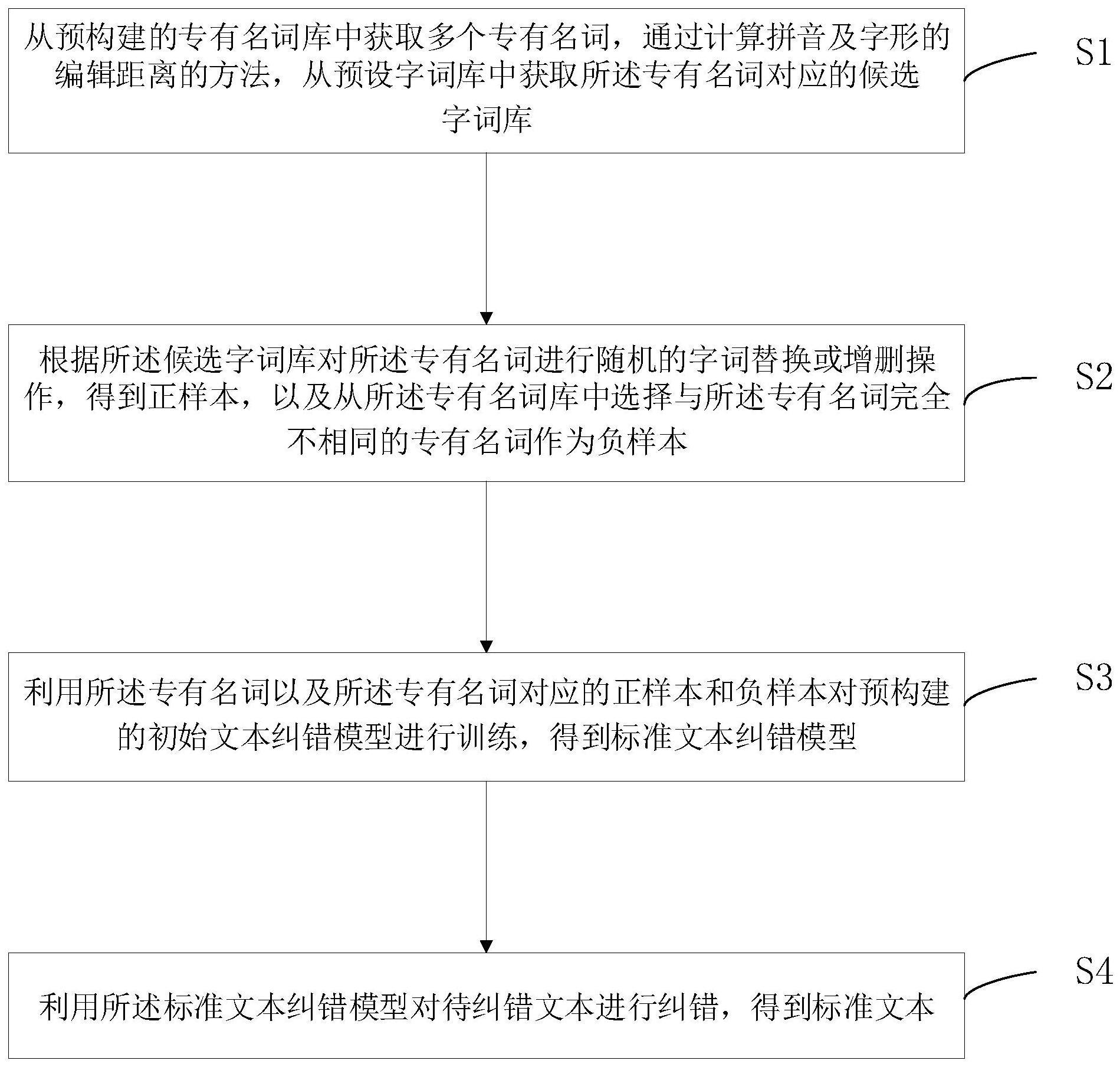
2、为实现上述目的,本发明提供的一种专有名词纠错方法,包括:
3、从预构建的专有名词库中获取多个专有名词,通过计算拼音及字形的编辑距离的方法,从预设字词库中获取所述专有名词对应的候选字词库;
4、根据所述候选字词库对所述专有名词进行随机的字词替换或增删操作,得到正样本,以及从所述专有名词库中选择与所述专有名词完全不相同的专有名词作为负样本;
5、利用所述专有名词以及所述专有名词对应的正样本和负样本对预构建的初始文本纠错模型进行训练,得到标准文本纠错模型;
6、利用所述标准文本纠错模型对待纠错文本进行纠错,得到标准文本。
7、可选地,所述利用所述专有名词以及所述专有名词对应的正样本和负样本对预构建的初始文本纠错模型进行训练,得到标准文本纠错模型,包括:
8、计算各个所述专有名词文本和对应正样本之间的第一欧式距离,以及计算各个所述专有名词文本和对应负样本之间的第二欧式距离;
9、从多个所述专有名词中选取其中一个专有名词,根据选取的所述专有名词的第一欧式距离以及所述第二欧式距离,利用所述初始文本纠错模型中的损失函数公式计算损失函数值;
10、判断所述损失函数值是否大于预设的损失函数阈值;
11、当所述损失函数值大于预设的损失函数阈值时,利用前反馈神经网络最小化所述损失函数值,并将所述初始文本纠错模型的参数进行网络逆向更新,得到更新文本纠错模型,并返回上述从多个所述专有名词中选取一个专有名词的步骤;
12、当所述损失函数值小于或者等于预设的损失函数阈值时,将所述更新文本纠错模型作为所述标准文本纠错模型。
13、可选地,所述利用所述标准文本纠错模型对待纠错文本进行纠错,得到标准文本之前,所述方法还包括:
14、接收待纠错文本,并将所述待纠错文本拼音化,得到待纠错拼音文本;
15、将所述待纠错拼音文本通过预设的输入法进行转换,得到拼音转换文本;
16、比对所述拼音转换文本和所述待纠错文本的相同字符的数目;
17、当所述拼音转换文本和所述待纠错文本的相同字符的数目小于预设数目时,执行利用所述标准文本纠错模型对待纠错文本进行纠错的步骤。
18、可选地,所述方法还包括:
19、当所述拼音转换文本和所述待纠错文本的相同字符的数目大于或者等于预设数目时,计算所述待纠错文本的向量均值;
20、根据所述向量均值从所述专有名词库中获取所述待纠错文本的标准文本。
21、可选地,所述根据所述候选字词库对所述专有名词进行随机的字词替换或增删操作,得到正样本,包括:
22、从所述候选字词库中随机选择一个或者多个字词,利用选择的所述字词替换所述专有名词中对应的字词,得到替换专有名词;
23、随机删除所述专有名词中的一个或者多个字词,得到缺失专有名词;
24、汇总所述替换专有名词以及所述缺失专有名词,得到所述专有名词的正样本。
25、可选地,所述通过计算拼音及字形的编辑距离的方法,从预设字词库中获取所述专有名词对应的候选字词库,包括:
26、计算所述专有名词中每个字词与所述预设字词库中每个字词的字形编辑距离,从预设字词库中选择所述选择所述字形编辑距离小于预设第一编辑距离阈值的字词,得到字形近似词;
27、获取所述专有名词的拼音表示,得到名词拼音,计算所述名词拼音与所述预设字词库中每个字词的拼音之间的字音编辑距离,并从预设字词库中选择所述字音编辑距离小于预设第二编辑距离阈值的字词,得到拼音近似字词;
28、集合所述拼音近似字词和所述字形近似词,得到所述候选字词库。
29、可选地,所述损失函数公式为:
30、l=max(d(anchor,positive)-d(anchor,negative)+margin,0)
31、其中,l为损失函数值,d(anchor,positive)为所述专有名词文本和所述正样本的欧式距离,d(anchor,negative)为所述专有名词文本和所述负样本的欧式距离,margin为预设距离参考值。
32、为了解决上述问题,本发明还提供一种专有名词纠错装置,所述装置包括:
33、名词获取模块,用于从预构建的专有名词库中获取多个专有名词,通过计算拼音及字形的编辑距离的方法,从预设字词库中获取所述专有名词对应的候选字词库;
34、样本构建模块,用于根据所述候选字词库对所述专有名词进行随机的字词替换或增删操作,得到正样本,以及从所述专有名词库中选择与所述专有名词完全不相同的专有名词作为负样本;
35、模型训练模块,用于利用所述专有名词以及所述专有名词对应的正样本和负样本对预构建的初始文本纠错模型进行训练,得到标准文本纠错模型;
36、文本纠错模块,用于利用所述标准文本纠错模型对待纠错文本进行纠错,得到标准文本。
37、为了解决上述问题,本发明还提供一种电子设备,所述电子设备包括:
38、至少一个处理器;以及,
39、与所述至少一个处理器通信连接的存储器;其中,
40、所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器能够执行如上所述的专有名词纠错方法。
41、为了解决上述问题,本发明还提供一种计算机可读存储介质,包括存储数据区和存储程序区,存储数据区存储创建的数据,存储程序区存储有计算机程序;其中,所述计算机程序被处理器执行时实现如上所述的专有名词纠错方法。
42、本发明实施例中通过计算拼音及字形的编辑距离的方法,从预设字词库中获取专有名词对应的候选字词库,再根据候选字词库和专有名词库构建正样本和负样本,实现训练样本的获取,然后利用专有名词以及专有名词对应的正样本和负样本对预构建的初始文本纠错模型进行训练,得到标准文本纠错模型,最后利用标准文本纠错模型对待纠错文本进行纠错,得到标准文本。因此,本发明通过构建正样本和负样本训练初始文本纠错模型,能够为用户纠正同音、近形等多种文本输入错误,有效涵盖了用户在进行医疗诊断过程中专有名词搜索时出现的各种错误可能,以实现对输入错误的专有名词进行准确纠错的目的。
- 还没有人留言评论。精彩留言会获得点赞!