一种用于多个完形填空型机器阅读理解任务的方法
本发明属于自然语言处理,具体涉及一种用于多个完形填空型机器阅读理解任务的方法。
背景技术:
1、机器阅读理解(machinereadingcomprehension,mrc)是人工智能中的一个重要应用领域,旨在模拟人类的阅读过程,让机器通过阅读给定文章、问题,理解这些文本的含义,推断文章和问题之间的关系,最终给出问题的答案。完形填空型机器阅读理解是机器阅读理解的一种,它会给出一篇文章以及从这篇文章中抽取的若干个词语或者句子,需要模型将候选词语或者句子精准的填入到原文章当中,使之成为一篇完整的文章。完形填空型机器阅读理解需要机器系统能够根据上下文的逻辑关系判断空缺部分的内容,进一步提升了机器阅读理解的难度。
2、现有的训练机器阅读理解模型的方法主要是,构造一个初始模型,利用单一数据集来对初始模型进行训练,得到一个可以对给定文章、问题做出回答的模型。现有的大部分模型都在考虑如何通过加强单模型网络来学习文章,选项之间的逻辑关系,进而提高模型的性能。对如何同时利用多个数据集合训练来提高模型的泛化性能缺乏思考。
3、因此,如何同时利用多个数据集合进行训练来提高模型性能成为亟待解决的技术问题。
技术实现思路
1、为了解决背景技术中存在的问题,本发明提供一种用于多个完形填空型机器阅读理解任务的方法,包括:
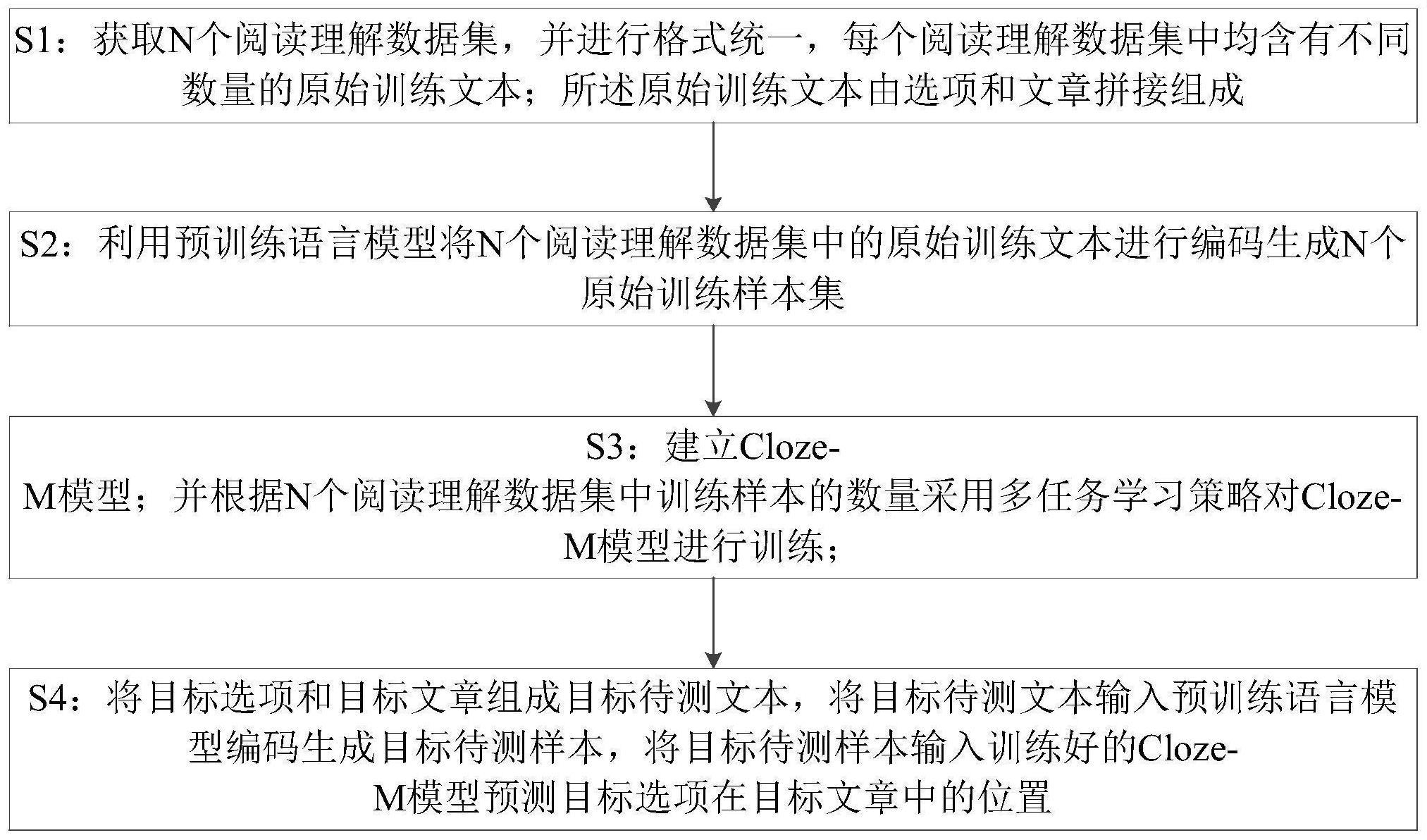
2、s1:获取n个阅读理解数据集,并进行格式统一,每个阅读理解数据集中均含有不同数量的原始训练文本;所述原始训练文本由选项和文章拼接组成;
3、s2:利用预训练语言模型将n个阅读理解数据集中的原始训练文本进行编码生成n个原始训练样本集;
4、s3:建立cloze-m模型;并根据n个阅读理解数据集中训练样本的数量采用多任务学习策略对cloze-m模型进行训练;其中,所述cloze-m模型包括:依次连接的输入层、编码层和输出层;
5、s4:将目标选项和目标文章组成目标待测文本,将目标待测文本输入预训练语言模型编码生成目标待测样本,将目标待测样本输入训练好的cloze-m模型预测目标选项在目标文章中的位置。
6、进一步地,所述预训练语言模型包括roberta-large或macbert-large模型。
7、进一步地,利用预训练语言模型对原始训练文本进行编码包括:将文章中的空白“[blank1]”转化为“[unsed1]”,并进行相应的编码和特征转化得到训练样本;所述训练样本包括:input_ids、input_mask、segment_ids;input_ids表示原始训练文本的输入文本转化为对应的词向量序列;input_mask表示原始训练文本中的有效词所在的位置为1,无效词所在的位置为0组成的位置序列;segment_ids表示原始训练文本中不同句子所在的token位置为1,同一句子中的token位置为0组成的位置序列。
8、进一步地,所述cloze-m模型的编码层由m个transformer编码器堆叠在一起形成深度结构;每个transformer编码器包括:依次堆叠的多头自注意力机制和全连接前馈网络;所述cloze-m模型的输出层为全连接层,用于将编码层输出的特征向量线性转化为一维向量,作为cloze-m模型的输出结果。
9、进一步地,所述根据n个阅读理解数据集中训练样本的数量采用多任务学习策略对cloze-m模型进行训练包括:
10、将n个阅读理解数据集按训练样本的数量进行排序,比较相邻两个阅读理解数据集训练样本的数量差是否大于设定阈值;若存在任意两个阅读理解数据集训练样本的数量差大于设定阈值,则采用策略1对cloze-m模型进行训练;反之采用策略2对cloze-m模型进行训练;其中,策略1表示为根据n个阅读理解数据集按训练样本的数量生成每个阅读理解数据集的抽样概率,在cloze-m模型进行训练时,根据阅读理解数据集的抽样概率在阅读理解数据集中采样n个训练样本作为一个批次输入cloze-m模型进行训练;策略2表示为随机从n个阅读理解数据集中选取一个数据集,并从该数据集中采样n个训练样本作为一个批次输入cloze-m模型进行训练。
11、进一步地,所述对cloze-m模型进行训练包括:将采样的n个训练样本组成一个原始特征向量组输入cloze-m模型,依次经过m个transformer编码器进行特征提取输出第一中间特征矩阵;将第一中间特征矩阵输入全连接输出层进行先行转换输出选项在文章中的位置;根据cloze-m模型的输出结果和原始训练文本的标签信息计算cloze-m模型的交叉熵损失,利用adam优化器对cloze-m模型的参数进行更新。
12、进一步地,cloze-m模型的损失函数包括:
13、loss=cross_entropy(prob,label)
14、其中,loss表示cloze-m模型的损失函数,所述cross_entropy表示交叉熵,prob表示选项的位置信息,label表示选项的标签信息。
15、本发明至少具有以下有益效果
16、本发明利用多任务学习来解决完形填空型阅读理解任务,具有以下几个优点:
17、1.通过策略选择不同的任务进行同时训练,利用多个任务之间的相关性关系,通过共享模型的权重,可以减少重复训练,提高数据效率。
18、2.可以提高模型的泛化能力,即模型能够适应不同的任务和数据集,同时也能有效地避免过拟合和欠拟合的问题。
19、3.通过多任务学习,模型可以通过跨任务学习,获取其他任务中的有用信息,并转移这些知识到当前任务中,对提升模型的性能有很大帮助。
20、说明书附图
21、图1为本发明的方法流程示意图。
技术特征:
1.一种用于多个完形填空型机器阅读理解任务的方法,其特征在于,包括:
2.根据权利要求1所述的一种用于多个完形填空型机器阅读理解任务的方法,其特征在于,所述预训练语言模型包括roberta-large或macbert-large模型。
3.根据权利要求2所述的一种用于多个完形填空型机器阅读理解任务的方法,其特征在于,利用预训练语言模型对原始训练文本进行编码包括:
4.根据权利要求1所述的一种用于多个完形填空型机器阅读理解任务的方法,其特征在于,所述cloze-m模型的编码层由m个transformer编码器堆叠在一起形成深度结构;每个transformer编码器包括:依次堆叠的多头自注意力机制和全连接前馈网络;
5.根据权利要求4所述的一种用于多个完形填空型机器阅读理解任务的方法,其特征在于,所述根据n个阅读理解数据集中训练样本的数量采用多任务学习策略对cloze-m模型进行训练包括:
6.根据权利要求5所述的一种用于多个完形填空型机器阅读理解任务的方法,其特征在于,所述对cloze-m模型进行训练包括:将采样的n个训练样本组成一个原始特征向量组输入cloze-m模型,依次经过m个transformer编码器进行特征提取输出第一中间特征矩阵;将第一中间特征矩阵输入全连接输出层进行先行转换输出选项在文章中的位置;根据cloze-m模型的输出结果和原始训练文本的标签信息计算cloze-m模型的交叉熵损失,利用adam优化器对cloze-m模型的参数进行更新。
7.根据权利要求6所述的一种用于多个完形填空型机器阅读理解任务的方法,其特征在于,cloze-m模型的损失函数包括:
技术总结
本发明涉及一种用于多个完形填空型机器阅读理解任务的方法,包括:获取N个阅读理解数据集,每个阅读理解数据集中均含有不同数量的原始训练文本;所述原始训练文本由选项和文章拼接组成;利用预训练语言模型将N个阅读理解数据集中的原始训练文本进行编码生成N个原始训练样本集,建立Cloze‑M模型;并根据N个阅读理解数据集中训练样本的数量采用多任务学习策略对Cloze‑M模型进行训练;将目标选项和目标文章组成目标待测文本,将目标待测文本输入预训练语言模型编码生成目标待测样本,将目标待测样本输入训练好的Cloze‑M模型预测目标选项在目标文章中的位置,提高系统解决完形填空型机器阅读理解任务的性能。
技术研发人员:孙开伟,纪志阳,段雨辰
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!