基于混合表征学习的低剂量CT图像去噪方法
本发明属于医学图像去噪,涉及一种基于混合表征学习的低剂量ct图像去噪方法。
背景技术:
1、现代医疗诊断的手段发展迅速,其中最重要的工具之一是计算机断层扫描(ct),它是一种可靠且无创的医学图像成像方式,有助于发现人体的病理异常,头颈部、心血管、胸部、腹部及盆部等疾病。除了诊断方面以外,ct在指导各种临床治疗方面也大有用处,如放射治疗和手术等。但反复的ct扫描过程中的x射线辐射可能对人体产生一定的危害,可能导致免疫功能下降、代谢异常、生殖器损伤,增加白血病、癌症、遗传疾病的风险。所以近几年越来越多的检查采用的低剂量ct(ldct)的方法来进行。它主要是在保证ct图像质量能满足诊断需求的基础上,减少ct扫描中的x射线剂量。但这样会导致诸如噪声增加、边缘、角落和尖锐特征对比度降低以及图像过度平滑等问题。
2、近年来,关于ldct的去噪问题开始了广泛的研究。这些方法可大致分类三类:1.基于滤波器的方法:在同一个图像中具有很多相似的图像块,可以通过非局部相似块堆叠的方式去除噪声,如基于非局部自相似的图像去噪(nlm)算法、基于块匹配的3d滤波(bm3d)算法、小波变换等。2.基于模型的方法:如:lnltv算法。它是一种局部和非局部全变分复合正则化图像去噪模型,同时利用了图像局部结构和非局部相似性,将全变分(totalvariation,tv)模型和nltv(nonlocal total variation)模型结合起来以减轻它们的缺点,并充分利用这两种模型的优点来对图像进行去噪处理。3.基于学习的方法:深度网络的方法的出现,比基于滤波、基于模型和传统的基于学习的方法获得了更有前景的去噪结果,现已成为主流方法。此方法侧重于学习有噪声图像到干净图像的潜在映射,由于cnn强大的特征学习能力和特征映射能力,基于cnn的ldct图像去噪网络取得了很好的效果,但仍然存在去噪图像过度平滑而导致关键细节丢失从而影响病灶部位的正确分析的风险。vit(vision transformer)通过全局自注意捕获数据中的长期依赖关系,成为了计算机视觉领域的又一大突破。
3、基于此,越来越多的transformer结构在图像领域出现,并取得了不错的效果,在医学图像去噪领域也是如此。最近也有许多研究在尝试用cnn与transformer融合,也取得了一定的效果。但两者的前后结合可能会存在参数权值共享所导致的部分信息不准确的情况。
4、因此,单纯的卷积神经网络在局部特征提取方面具有优势,而存在全局建模能力弱的问题。基于窗口的自注意力机制通过复杂的空间变换和长距离特征依赖性,构成了全局表示。但其可能忽略了局部特征细节。从而可能导致ct图像过度的平滑,细节纹理信息较少的情况,从而影响诊断。
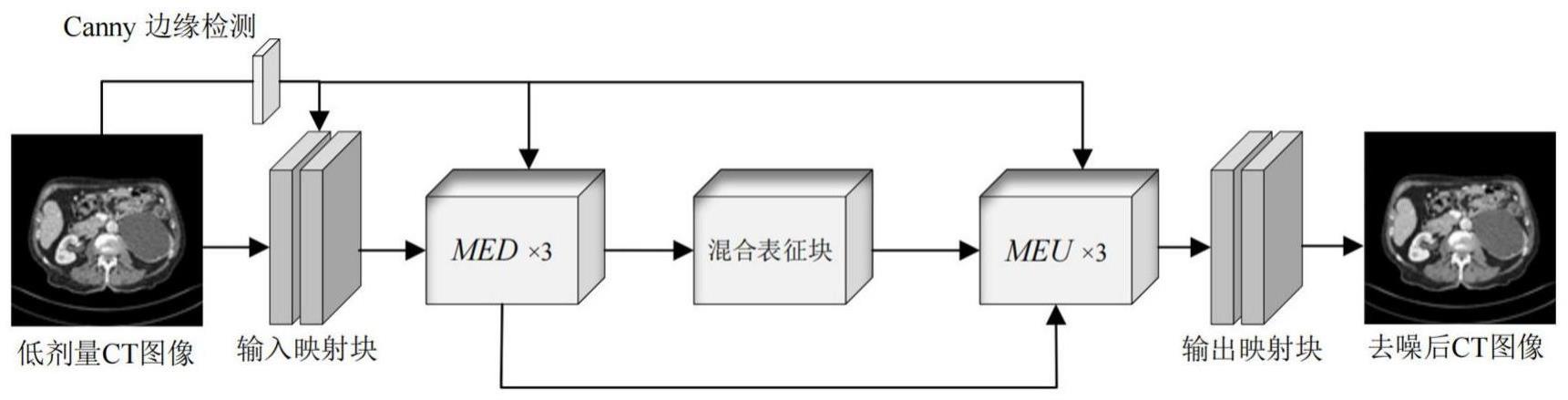
技术实现思路
1、本发明目的在于提供一种基于混合表征学习的低剂量ct图像去噪方法;将ct图像先进行边缘强化处理,再利用深度卷积与局部窗口自注意进行交互,从而获取窗口内与窗内之间的ct图像信息,结合均方误差与基于resnet的多尺度感知函数最终输出噪声图像与低剂量ct图进行残差处理,在保证去噪图像的去噪效果的同时还能保留有更多的细节纹理信息,提高低剂量ct图像的去噪效果。
2、使用编码器和解码器对称式结构,在每个编码器和解码器阶段,分别加入混合表征块mixed block,将卷积映射信息传递给自注意力模块,实现窗口内部和窗口间的信息交互,同时与canny算子处理的图像增强信息进行拼接,最大程度的在不破坏原有部位局部信息的前提下更好的实现降噪功能。同时,通过跳跃连接,对每个输出解码块与其对应位置的输入编码块在通道上进行融合,通过底层信息与高层信息的融合,从而保留住更多的纹理细节。其次,还可以防止出现网络梯度消失的问题,提升训练速度。
3、本发明具体步骤如下:
4、步骤一、构建低剂量ct数据集:
5、挑选一定数量的患者,并选取其不同部位上的低剂量ct图像和其对应的正常剂量ct图像,插入泊松噪声直到接近全剂量下25%的噪声水平,组成ct图像数据集(x,y)。其中x为低剂量ct图像,而y为x对应的正常剂量ct图像。
6、步骤二、构建去噪网络模型:
7、基于混合表征块mixed block学习构建对称式编码-解码网络模型,该网络模型包括预处理块(pre-processing)、输入映射块(input projection)、输入编码块(med)、中间层混合表征块(mixed block)、输出解码块(meu)和输出映射块(output projection)。
8、在图像预处理阶段,输入图像经过canny算子滤波生成边缘特征增强的图像,该图像作为辅助信息流入后续网络块,以凸显图像边缘特征,增加模型的感受野。
9、考虑到直接将低剂量ct图像输入神经网络模型处理后会出现图像过度平滑、部分细节特征丢失等情况,设计了基于canny算子的图像预处理层,以强化图像边缘特征。具体地,经过canny算子滤波后的图像会直接拼接至输入映射块,编码块和解码块,作为辅助特征来实现图像去噪。
10、输入映射块包括多层感知机mlp,通过两层神经元将输入映射到固定维度,便于后续进行表征运算。
11、输入编码块包括输入混合表征块、边缘增强特征层、可分离卷积和下采样层;首先将输入映射块的输出作为查询集query、键key和值value输入至混合表征块进行表征学习,并将canny算子处理后的边缘增强特征图与表征结果进行级联后,通过一个可分离卷积,最后将其输入下采样层来实现输入模块的编码,其中下采样卷积核为3×3,步幅为2,填充为1。
12、中间层混合表征块包括窗口自注意力(wsa)和深度卷积(dwconv),窗口自注意力能够减少对于窗口外部的依赖,在高效计算的同时捕捉特征空间窗口内部的相关性。深度卷积则在不改变卷积通道数的前提下,对每个通道进行单独卷积操作以挖掘通道信息。
13、设计中间层混合表征块,通过通道层和空间层的双向交互,不仅解决了窗口自注意力机制存在感受野有限,同时也消除了深度卷积权值共享带来的不足,实现了窗口内部和窗口间的纹理信息交互和信息增益,有效增墙了ct图像的全局建模能力。在实际配置中,注意力模块窗口尺寸为7×7,深度卷积的卷积核大小为3×3。
14、输出解码块meu包括上采样层、边缘增强特征层、可分离卷积和输出混合表征块;首先经过卷积核为4×4,步幅为2的上采样操作。因为在反卷积过程中,如果卷积核大小不能被步长整除时,反卷积可能会出现棋盘效应。然后同样的拼接上由canny算子处理过的边缘特征图像,通过一个可分离卷积,最后加上一个混合表征块mixed block来学习更多纹理的特征知识。
15、输入混合表征块、中间层混合表征块和输出混合表征块结构相同;在输入编码块与输出解码块之间采用跳跃连接,在对称式结构中,每个输出解码块与其对应位置的输入编码块在通道上进行融合,通过底层信息与高层信息的融合,从而保留住更多的纹理细节。其次,还可以防止出现网络梯度消失的问题。
16、输出映射块(output projection)包括一层mlp,将输出映射到1×h×w,还原原始图像大小。
17、步骤三、数据增强:
18、医学图像本身存在样本数据复杂,标注稀疏等问题。为进一步增加训练样本,本发明使用图像增强策略,对收集的数据集以不同的概率进行了水平-垂直翻转、随机裁剪等多种增强操作,构造更多数量的图像。
19、步骤四、模型优化:
20、采用两个损失函数来优化模型,以进一步提升模型的性能。
21、首先,使用均方误差mse来将误差收敛到最小值,损失函数l1表达式为:
22、
23、l1是用于评估模型去噪后的图像与真实图像之间的像素级相似度,以及模型是否能够准确还原原始图像;
24、其中r(xi)表示低剂量噪声图像xi经过残差学习映射出的纯噪声图像;yi表示其对应的正常剂量的ct图像。
25、其次,基于resnet的多尺度感知函数用于实现低剂量图片与噪声图片的残差功能,该损失函数l2表达式为:
26、l2损失函数主要用于评估模型预测的图像与真实图像之间的结构相似性;
27、其中α是采用经典特征提取网络resnet50作为特征提取器,是resnet50在imagenet数据集上在删除汇聚层后被冻结的权值,r(xi)表示低剂量噪声图像xi经过残差学习映射出的纯噪声图像。yi表示低剂量噪声图像xi对应的正常剂量的ct图像。
28、损失函数l=λ1l1+λ2l2,其中λ1,λ2为可调超参数。
29、通过不断调整学习率和可调超参数进行模型的优化,得到最优参数,输出最优模型。
30、步骤五、任意选取一张低剂量ct图像放入去噪模型中,输出最终结果,即可得到去噪后的低剂量ct图像。
31、本发明采用以上技术方案与现有技术相比,创新和优点在于:
32、将深度卷积与窗口自注意力机制应用于ct图像的表征学习,能很大程度上实现ct图像的纹理信息交互和信息增益,与通过canny算子来强化的边缘信息图像进行一个拼接,这样形成的一个混合特征图使得生成的去噪图像能更好得保留原有的整体结构和局部纹理细节。
33、将原始低剂量去噪图像先经过canny算子处理后生成边缘特征图像,每进行一次下采样或上采样,经过一个med和meu模块都会与边缘特征图像进行融合,用于强化ct图像的细节,防止出现过度的平滑,进而避免损失关键的细节特征。同时,通过对应med和meu块的跳跃连接,能实现使得网络在每一级的上采样过程中,将编码器对应位置的特征图在通道上进行融合。通过底层特征与高层特征的融合,网络能够保留更多高层特征图蕴含的纹理细节信息,从而提升特征表征能力。同时,跳跃连接可以缓解梯度消失的问题,加速网络的训练,从而提升网络的性能。
34、采用常用的均方误差与基于resnet的多尺度感知损失函数来进行模型优化,通过常用的均方误差将其收敛速度更快,同时使用多尺度感知损失函数使得去噪学习的函数与恒等映射相近,使用残差映射更容易被优化。通过残差学习的方式,隐式地去除隐藏层中潜在的干净的图像,将噪声信息更好的被识别出来,以达到更好的去噪效果。相比于直接输出干净图像,避免了出现过拟合问题,使得去噪效果有较大的提升。
35、模型尽可能的降低了参数量,在同等参数复杂性下,能达到更好的去噪效果。
36、本发明可将低剂量ct图像中的噪声和伪影进行去除,同时还能保留原有图像的整体结构和局部纹理细节以及解决边缘模糊问题,防止图像过度平滑而丢失部分局部信息,便于辅助临床诊断。
- 还没有人留言评论。精彩留言会获得点赞!