一种基于强化学习的策略梯度改进粒子群的PG-W-PSO方法
本发明属于投资组合优化领域,具体涉及一种基于强化学习的策略梯度改进粒子群的pg-w-pso方法。
背景技术:
1、pso是一种进化计算技术,作为一种生物启发式算法,中心思想概括为通过群体中个体之间的协作和信息共享来寻找最优解。其基本原理解释为:粒子群pso算法用一种无质量的粒子模拟鸟群中的鸟,其属性速度和位置分别表示位置移动的快慢和位置移动的方向,每个粒子寻找最优解,产生个体极值,将最优的个体极值作为种群的全局最优解,所有粒子根据个体极值和全局最优解不断调整自身速度和位置。
2、策略梯度算法属于强化学习的范畴,而强化学习现今也在众多领域被广泛应用。强化学习是机器学习的方法论之一,由三个部分组成:演员、环境和、以及奖励函数。其主要思想是构建与环境进行动态交互的智能体,从而实现优化控制策略达到最大化累积回报。其中强化学习可分为模型学习、值函数学习、以及策略学习。模型学习是指进行对环境的想象和模拟,将学习任务转化成规划任务。值函数学习直接学习值函数,记录什么时候做什么事对后面产生多少影响。策略学习是直接与环境进行交互学习策略,形成一套行为指南,具体就是通过和环境的交互,在学习的过程中,不断改变做出各个动作的概率,其中表示为反馈好的动作提高相应概率,反馈差的动作降低概率。对于这三种学习方法,也存在其自身的一些应用局限,比如值函数学习无法处理连续动作,无法解决随机策略问题。
3、近年来对于启发式算法的研究有了很大的发展,在有效求解复杂优化函数的问题上应用广泛,并且也已有效运用到投资组合优化问题中。其中粒子群算法应用广泛,因其简单易于实现以及参数易于调节等优点,出现了大量的相关研究,但粒子群算法也存在着一些不足,比如容易过早陷入局部最优、过早收敛等问题,因此,对如何改进粒子群算法、提升其性能并能成功应用于投资组合优化领域展示了其重要性。
技术实现思路
1、为解决pso算法寻优过程中人工配置参数不容易确定合适的参数的问题,本发明的目的在于提供一种基于强化学习的策略梯度改进粒子群的pg-w-pso方法。
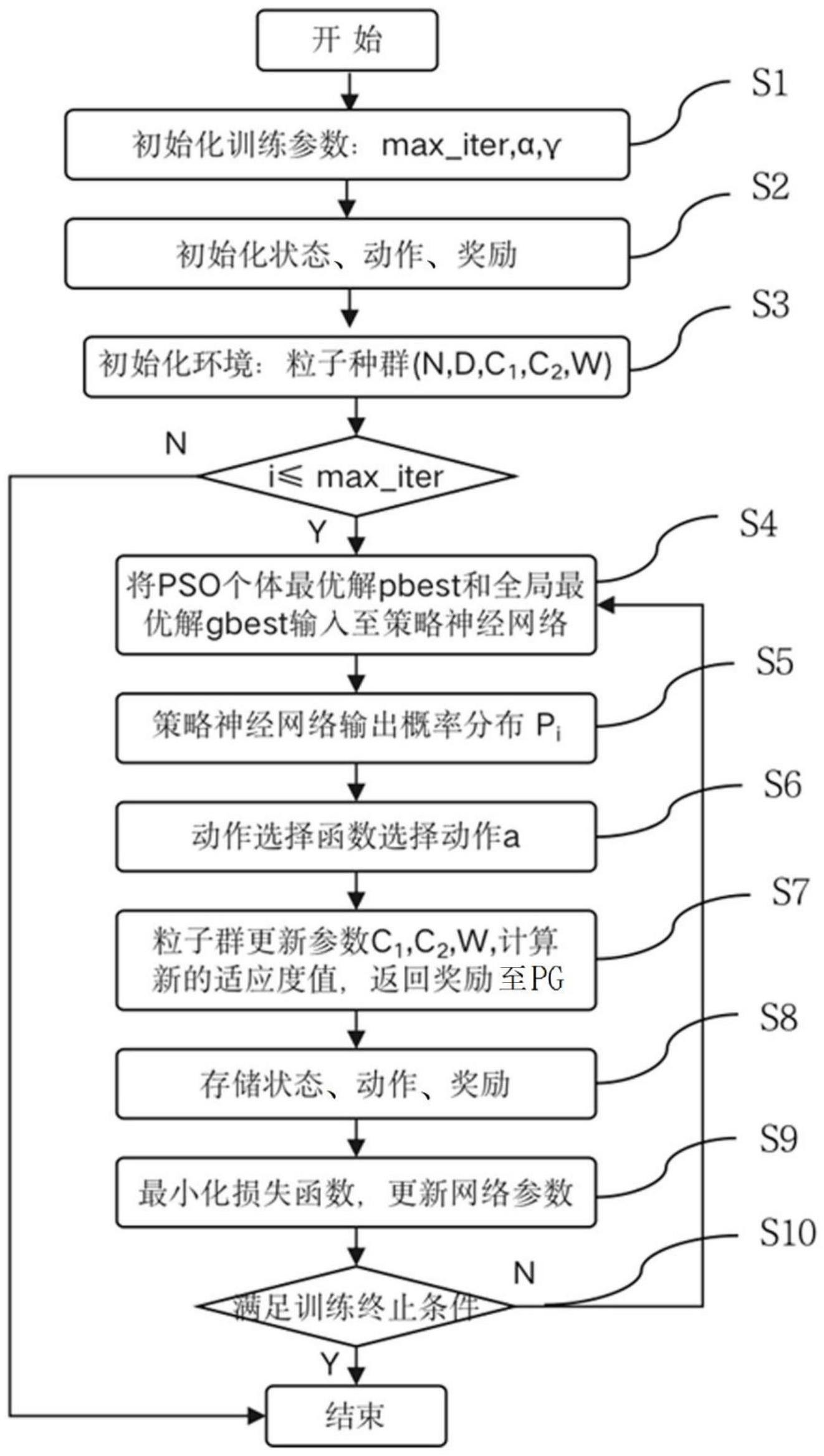
2、本发明提供了一种基于强化学习的策略梯度改进粒子群的pg-w-pso方法,具有这样的特征,包括以下步骤:s1、初始化训练参数,包括最大迭代次数max_iter、学习率α、折扣因子γ;s2、初始化状态、动作、奖励;s3、初始化环境,包括粒子种群的规模n、粒子维数d、惯性权重w、学习因子c1和c2;s4、将pso计算个体最优值pbest和全局最优值gbest作为输入状态输入策略神经网络;s5、策略神经网络根据输入状态输出动作概率分布pi;s6、动作选择函数根据pi确定对应的动作a并传递给pso;s7、pso根据参数更新规则更新参数迭代优化,并计算新的适应度值和返回奖励到pg;s8、存储新的状态、动作、奖励;s9、pg计算累积折扣奖励、最小化损失函数l(θ),并更新网络参数θ;s10、不满足终止迭代条件,则返回步骤s4,满足终止迭代条件则结束,得到最优解。
3、在本发明提供的基于强化学习的策略梯度改进粒子群的pg-w-pso方法中,还可以具有这样的特征:s4中,输入/输出状态设置为:
4、
5、其中,d1和d2分别表示pso在一次迭代更新中的个体最优解和全局最优解,n表示粒子种群规模大小,xpbest表示第i个粒子的历史个体最优值,xgbest表示整个粒子群的历史全局最优值,xi表示第i个粒子的位置向量。
6、在本发明提供的基于强化学习的策略梯度改进粒子群的pg-w-pso方法中,还可以具有这样的特征:所述策略神经网络包括输入层、隐藏层、以及输出层,所述输入层用于接受输入状态作为输入,所述隐藏层用于使用tanh函数对输入进行处理,所述输出层用于使用softmax函数输出动作概率分布pi。
7、在本发明提供的基于强化学习的策略梯度改进粒子群的pg-w-pso方法中,还可以具有这样的特征:s6中,动作选择表示方法为:当pi=p0时,a=0,当pi=p1时,a=1,当pi=p2时,a=2,当pi=p3时,a=3,当pi=p4时,a=4,当pi=p5时,a=5;所述动作选择函数设置为选取动作概率分布pi中概率最高的动作a。
8、在本发明提供的基于强化学习的策略梯度改进粒子群的pg-w-pso方法中,还可以具有这样的特征:s7中,参数更新规则根据pg反馈的动作a引入psow的参数更新方式来实现pso算法的参数自适应调整,
9、粒子速度更新公式为:
10、vi,j(t+1)=ωtvi,j(t)+c1,tr1[pi,j-xi,j(t)]+c2,tr2[pg,j-xi,j(t)]
11、粒子位置更新公式为:
12、xi,j(t+1)=xi,j(t)+vi,j(t+1)
13、其中,t表示当前算法的迭代次数,vi,j表示第i个粒子第j维度下的粒子速度,wt表示第t次迭代的惯性因子,xi,j是第i个粒子第j维度下的当前位置,r1、r2是介于(0,1)之间的随机数,c1、c2表示学习因子,pi,j表示第i个粒子第j维度的个体最优值,pg,j表示全部粒子第j维度的全局最优值。其中粒子速度更新公式中第一项表示粒子上一次迭代的速度,第二项表示粒子的个体学习部分,粒子向自身寻找到的最优解方向进行寻优,第三项表示粒子的群体学习部分,粒子根据群体中最优的粒子的运动经验调整自身,
14、c1更新规则为:
15、当a=0时,c1_min+(c1_max-c1_min)×(i/max_iter)
16、当a=1时,c1_max-(c1_max-c1_min)×(i/max_iter)
17、c2更新规则为:
18、当a=2时,c2_min-(c2_max-c2_min)×(i/max_iter)
19、当a=3时,c2_max-(c2_max-c2_min)×(i/max_iter)
20、w更新规则为:
21、当a=4时,ω_min+(ω_max-ω_min)×(i/max_iter)
22、当a=5时,ω_max-(ω_max-ω_min)×(i/max_iter)
23、其中,a表示动作,c1_min表示c1学习因子的最小下限,c2_min表示c2学习因子的最小下限,c1_max表示c1学习因子的最大上限,c2_max表示c2学习因子的最大上限,i表示当前迭代次数,max_iter表示最大迭代次数。
24、在本发明提供的基于强化学习的策略梯度改进粒子群的pg-w-pso方法中,还可以具有这样的特征:s7中,奖励机制为:
25、
26、发明的作用与效果
27、根据本发明所涉及的基于强化学习的策略梯度改进粒子群的pg-w-pso方法,该方法结合强化学习策略梯度算法,通过策略迭代来自适应地改进pso算法,从而实现参数的动态调整能力。pso根据不断迭代寻找全局最优解,通过与策略梯度算法进行交互,在引入线性递减惯性权重规则下不断更新速度和位置并进行不断优化,当优化过程接近最优时停止更新,得到最优解。将策略梯度引入粒子群算法中可以提高算法的优化精度,通过自适应地动态调整参数能提升算法性能,可以达到更好的优化效果。
- 还没有人留言评论。精彩留言会获得点赞!