基于对比学习和词粒度权重的视觉语言翻译方法和系统
本发明涉及时序对齐的视觉语言翻译领域,尤其涉及一种基于对比学习和词粒度权重的视觉语言翻译方法和系统。
背景技术:
1、时序对齐的视觉语言翻译旨在将表达者展现出的视觉内容翻译为自然语言文本,是计算机视觉和自然语言处理之间的一个跨学科领域。具体地,该领域包括唇语翻译、指语翻译等重要的人工智能任务,通过自动视觉语言翻译器帮助听力障碍者与正常人进行交流。在唇语翻译中,说话内容是根据说话者的嘴唇运动进行翻译的;在指语翻译中,文本序列是根据指语者的细粒度手部姿势进行翻译的。其中,唇语和指语翻译的共同点是,其视觉内容和翻译出的自然语言文本是时序对齐的。
2、现有的技术主要是利用自回归方法或者连接时序分类方法去生成字词序列。然而,由于不同表达者在特定的容易导致歧义的字词上有着多种多样的表现习惯,以至于这些方法在真实场景中表现不佳。此外,在数据资源有限或标注成本昂贵的情况下,上述表达者间的差异性会更加明显。理想情况下,一个可应用的时序对齐的视觉语言翻译系统应该拥有优秀的泛化能力,并且在未见过的表达者上给出较高的翻译准确率。
3、当下,领域泛化任务已经取得突破进展,其目的是用有限数据的源域训练一个可以直接泛化到未见目标域的模型。现有的技术主要分为表征学习、数据操作、学习策略三类方法。由于时序对齐的视觉语言翻译任务对模型在说话者间的泛化能力的需求,若能利用领域泛化任务中的方法,同时结合视觉语言翻译任务的特点,则可有效提升翻译的准确程度。
技术实现思路
1、本发明的目的在于增强时序对齐的视觉语言翻译系统在域外表达者上的泛化能力,以同时克服字词间的固有歧义并保持类间语义关系,和提升模型的域独立性。本发明提供一种基于对比学习和词粒度权重的视觉语言翻译方法和系统,以将唇语、指语视频翻译为自然语言文本。
2、本发明所采用的具体技术方案是:
3、第一方面,本发明提出了一种基于对比学习和词粒度权重的视觉语言翻译方法,包括如下步骤:
4、1)提取源域的唇语或指语视频嵌入特征,并获取自然语言文本嵌入特征;
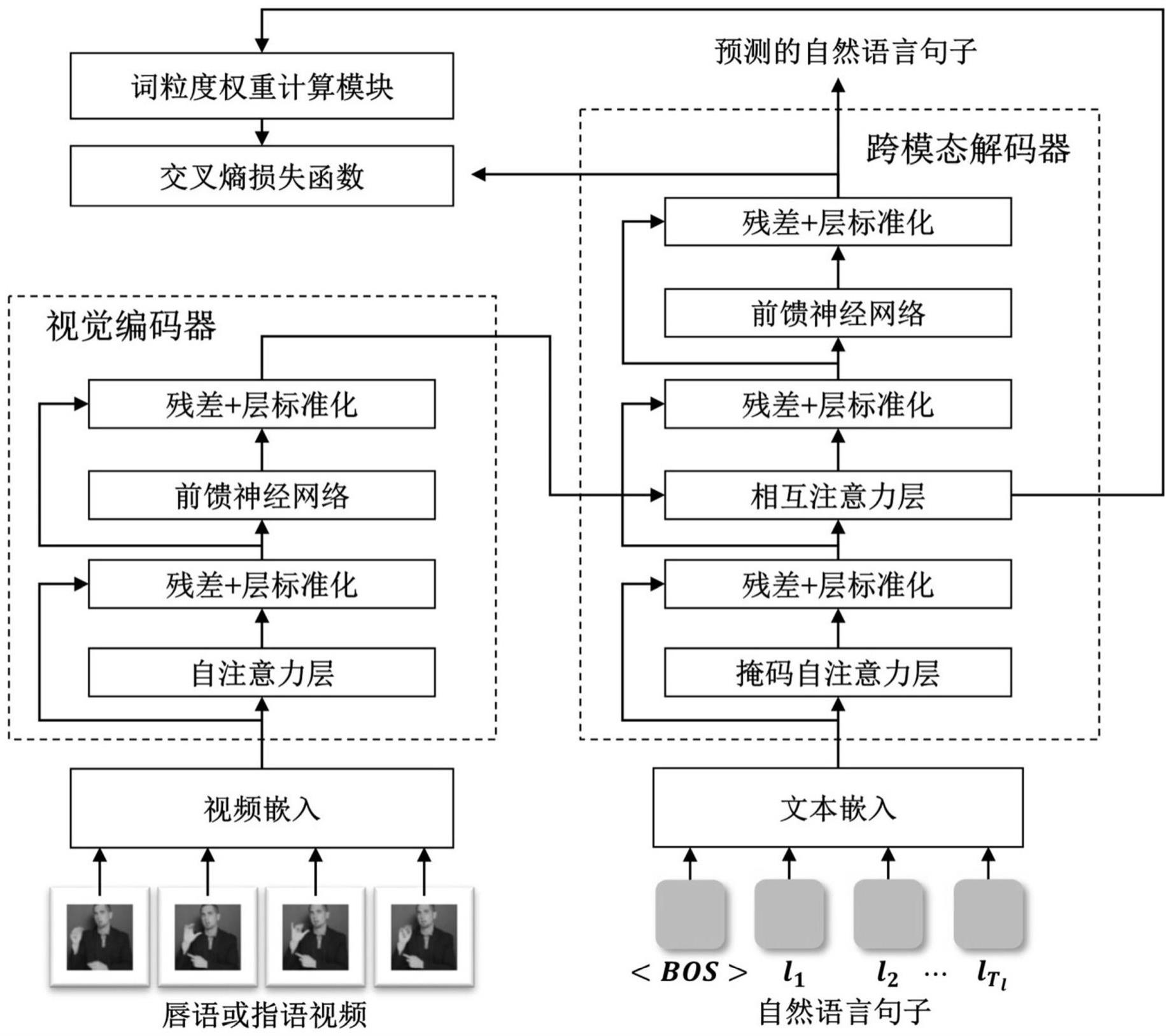
5、2)通过基于多头注意力机制的视觉编码器对唇语或指语视频嵌入特征进行编码,得到编码后的视觉特征;
6、3)对于编码后的视觉特征,在跨模态解码器中通过多头注意力机制与自然语言文本嵌入特征进行交互,解码生成字词概率分布,并获取基于任务的交叉熵损失函数项,对视觉编码器和跨模态解码器进行初步训练;
7、4)根据初步训练的视觉编码器和跨模态解码器得到的解码的注意力向量,计算字词的词粒度多样性权重,并以此更新步骤3)中的交叉熵损失函数项,得到带词粒度多样性权重作用的交叉熵损失项;
8、5)将源域随机划分为元训练集合和元测试集合,在元训练阶段,利用带词粒度多样性权重作用的交叉熵损失项更新视觉编码器和跨模态解码器参数;在元测试阶段,利用元测试阶段更新后的跨模态解码器中计算的注意力向量获取全局和局部的对比学习损失函数项,并结合带词粒度多样性权重作用的交叉熵损失项,重新更新视觉编码器和跨模态解码器参数,得到训练好的视觉编码器和跨模态解码器;
9、6)获取目标域中待翻译的唇语或指语视频嵌入特征,利用训练好的视觉编码器和跨模态解码器完成对未见过的表达者的视觉语言翻译任务。
10、进一步的,源域的唇语或指语视频与对应的自然语言文本是时序对齐的。
11、进一步的,所述的视觉编码器为多层结构,每一层由自注意力层、前馈神经网络、残差连接、层标准化操作堆叠而成,用于对唇语或指语视频嵌入特征进行编码,生成编码后的视频特征矩阵。
12、进一步的,所述的跨模态解码器为多层结构,每一层由自注意力层、相互注意力层、前馈神经网络、残差连接、层标准化操作堆叠而成,用于根据自然语言文本嵌入特征和编码后的视频特征矩阵,预测下一时间步的字词。
13、进一步的,所述的步骤4)包括:
14、4.1)将源域数据的嵌入特征输入到步骤3)初步训练得到的视觉编码器和跨模态解码器,将跨模态解码器最后一层的相互注意力层sa(et′,f′,f′)的计算结果记为其中,tt是时间步t之前字词的数量,表示第k个表达者的注意力向量;
15、通过如下公式计算得到第k个表达者在词c上的个性化表达效果:
16、
17、其中,表示当第r个字词为c时,是字词标签为c的样本的数量,表示第k个表达者在词c上的表达向量;
18、4.2)根据不同表达者在同一个词上的表达向量,计算获取其方差,计算公式如下:
19、
20、其中,k为源域中的表达者数量,σ(·)代表非线性激活函数,vc表示词c的多样性权重向量,完整的词粒度多样性权重矩阵由每个词的权重拼接得到,表示为tc表示词表的长度;
21、4.3)根据步骤4.2)所得的词粒度多样性权重矩阵,更新交叉熵损失函数项,计算公式如下:
22、
23、其中,*代表词粒度上的向量间的按位乘操作,是带词粒度多样性权重作用的交叉熵损失函数。
24、进一步的,所述的步骤5)包括:
25、5.1)将包含k个域的源域数据在每轮训练时随机划分为元训练集和元测试集ntr表示元训练集的数据量,di表示元训练集中的第i个数据,nte表示元测试集的数据量,dj表示元测试集中的第j个数据;
26、5.2)在元训练阶段,计算带词粒度多样性权重作用的交叉熵损失项,更新参数:
27、
28、其中,θ表示视觉编码器和跨模态解码器的全部可训练参数,α表示元训练阶段的学习率,θ′表示更新后的参数,表示梯度;
29、5.3)在元测试阶段,将元测试集中的数据对经过模型参数更新为θ′的模型,利用解码器中计算的注意力向量,计算全局和局部的对比学习的损失函数项;
30、5.4)结合步骤5.3)中的全局和局部的对比学习的损失函数项、以及步骤5.2)中的带词粒度多样性权重作用的交叉熵损失项,得到总损失,根据总损失更新参数:
31、
32、其中,β表示学习率,θ表示视觉编码器和跨模态解码器的全部可训练参数,表示总损失。
33、进一步的,全局的对比学习的损失函数项的计算包括:
34、对于一个特定的表达者k,利用步骤4.1)所得的在具体词上的表达向量计算该词的概率分布,然后获取全局的对比学习的损失函数项,计算公式如下:
35、
36、
37、其中,softmax(·)表示激活函数,tc表示时间步t之前解码的字词数量,τ代表温度系数,表示表达者k的视频句子对在词c上的概率分布,no是元训练集中域di和元测试集中域dj组成的(di,dj)对的数量,表示第o对域组中的域di在词c上的概率分布,表示全局的对比学习的损失函数项,h(·|·)表示相对熵。
38、进一步的,局部的对比学习的损失函数项的计算包括:
39、将源域的全部数据经过步骤4.1)所得的词粒度注意力向量进行两两组合,得到若干样本对(xb,yb),构成集合a,局部的对比学习的损失函数项的计算公式如下:
40、
41、其中,ρ(·)表示一个距离函数,(xb,yb)表示集合a中第b个样本对,nb是样本对的数量,y=1–[xl=yl],表示当xl=yl时,[xl=yl]=1,y=0;,否则[xl=yl]=0,y=1;xl和yl是样本对中xb和yb各自的标签,ξ代表控制两个样本间距离的幅度的系数,表示局部的对比学习的损失函数项。
42、第二方面,本发明提出了一种基于对比学习和词粒度权重的视觉语言翻译系统,包括:
43、唇语或指语视频预处理模块,其用于提取源域的唇语或指语视频嵌入特征;
44、自然语言文本预处理模块,其用于获取自然语言文本嵌入特征;
45、视觉编码器模块,其用于对唇语或指语视频嵌入特征进行编码,得到编码后的视觉特征;
46、跨模态解码器模块,其用于对于编码后的视觉特征,通过多头注意力机制与自然语言文本嵌入特征进行交互,解码生成字词概率分布;在实际翻译阶段,根据编码后的视觉嵌入特征向量自回归地生成目标自然语言文本;
47、预训练模块,其用于基于任务的交叉熵损失函数项,对视觉编码器和跨模态解码器进行初步训练;
48、词粒度权重计算模块,其用于根据初步训练的视觉编码器和跨模态解码器得到的解码的注意力向量,计算字词的词粒度多样性权重;
49、对比限制的元学习训练模块,其用于源域随机划分为元训练集合和元测试集合,在元训练阶段,利用带词粒度多样性权重作用的交叉熵损失项更新视觉编码器和跨模态解码器参数;在元测试阶段,利用元测试阶段更新后的跨模态解码器中计算的注意力向量获取全局和局部的对比学习损失函数项,并结合带词粒度多样性权重作用的交叉熵损失项,重新更新视觉编码器和跨模态解码器参数,得到训练好的视觉编码器和跨模态解码器;
50、翻译模块,其用于获取目标域中待翻译的唇语或指语视频嵌入特征,利用训练好的视觉编码器和跨模态解码器完成对未见过的表达者的视觉语言翻译任务。
51、与现有技术相比,本发明具备的有益效果是:
52、本发明为一种基于对比学习和词粒度权重的视觉语言翻译方法,在实现时,本发明使用了词粒度权重引导的多样性注意力机制和对比限制的元学习训练策略。
53、(1)通过提出的词粒度多样性权重和对比限制的元学习训练框架,本发明提升了时序对齐的视觉翻译系统在域外表达者上的泛化能力,明确模型在序列预测时的泛化学习方向,从而克服字词间的固有歧义和适应表达者的个性化表现习惯差异,实现高效的视觉语言翻译。
54、(2)针对在识别上较困难的具有固有歧义的字词,本发明提出了词粒度权重计算模块,利用解码器交互后的注意力向量,计算词粒度多样性权重来反映字词的学习难度,进而通过该难度系数引导模型关注难度更大的字词。
55、(3)在对比限制的元学习训练阶段,通过使用表达者在特定字词上的个性化特征向量计算的全局对比损失函数,保持类间语义关系,同时通过局部对比损失函数,提升表达者间的独立性,增强模型在未见表达者上的泛化能力,从而实现高效的时序对齐的视觉语言翻译。
56、综上所述,通过使用词粒度多样性权重和两个相互补充的对比限制的元学习训练策略,本发明可以在唇语和指语翻译中,在保持词的类间关系的同时消除词固有的歧义,并且提升模型的泛化能力,在未见表达者上也有高准确率的翻译表现,实现高效的时序对齐的视觉语言翻译。
- 还没有人留言评论。精彩留言会获得点赞!