对话生成模型的训练方法、装置、存储介质及计算机设备与流程
本发明涉及人工智能及智慧医疗,尤其是涉及一种对话生成模型的训练方法、装置、存储介质及计算机设备。
背景技术:
1、随着神经网络模型技术的发展,transformer(编码解码模型)类预训练模型越来越受到各方的关注,其使得部署一个对话生成模型来应对多个不同的对话场景成为可能。特别是在医疗交互领域,对话生成模型可以接收来自不同医疗场景的对话信息,生成适用于不同医疗场景的回复信息。
2、当前,对话生成模型进行训练的方式多为随机的选取各场景的历史对话数据作为训练数据集中每个批次层面上的训练数据,但基于该种方式对模型进行训练的过程会因训练批次层面上的训练数据过于分散,导致对话生成模型收敛速度较慢。此外,将多个场景下的训练数据按照场景顺序对神经网络模型进行训练,会造成模型学习新知识后,几乎彻底遗忘掉之前学习的内容,导致在对模型的训练过程中会出现灾难性遗忘的情况,进而导致模型训练的效率大幅降低。
技术实现思路
1、有鉴于此,本申请提供了一种对话生成模型的训练方法、装置、存储介质及计算机设备,主要目的在于解决模型训练效率偏低的技术问题。
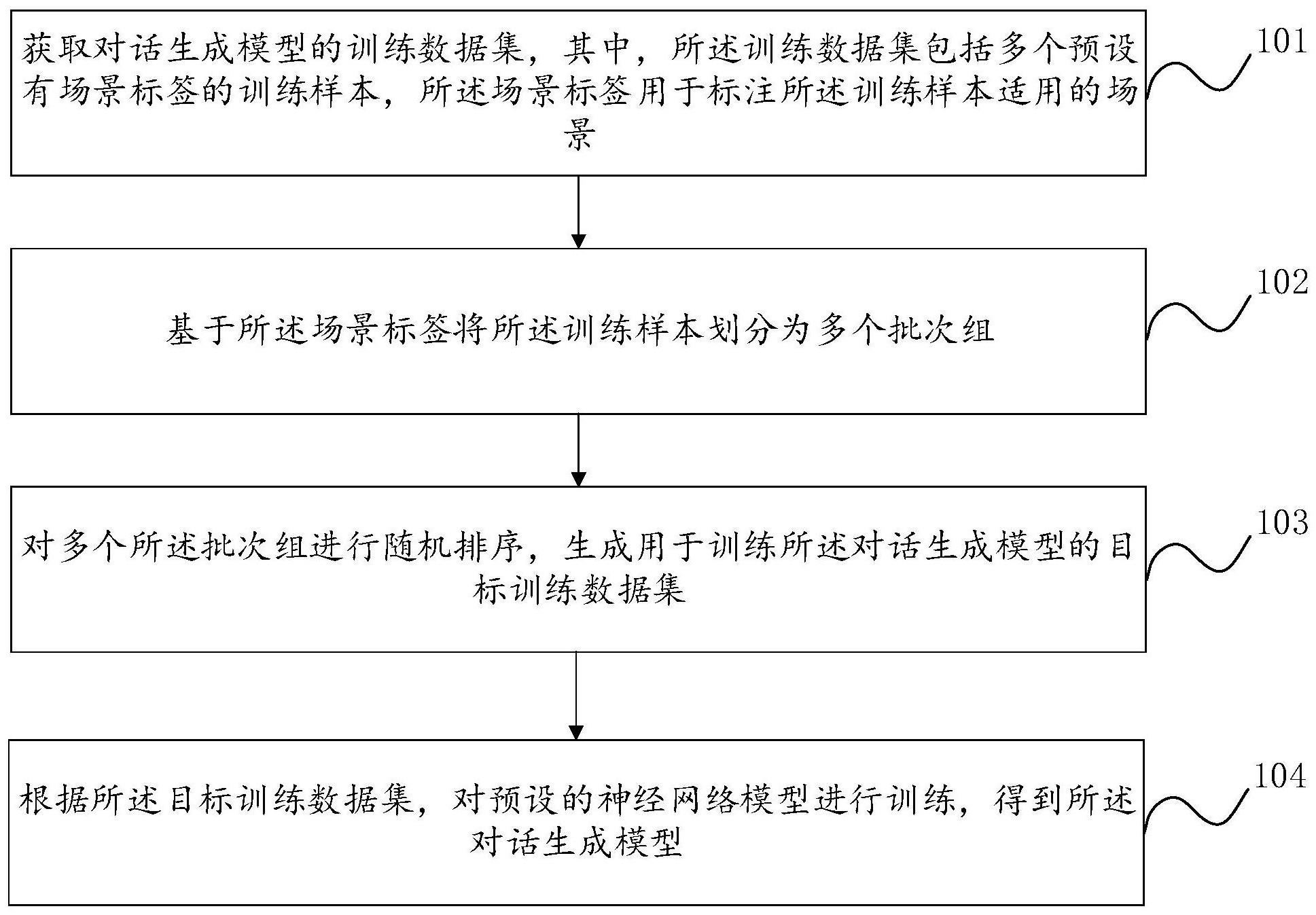
2、根据本发明的第一个方面,提供了一种对话生成模型的训练方法,该方法包括:
3、获取对话生成模型的训练数据集,其中,所述训练数据集包括多个预设有场景标签的训练样本,所述场景标签用于标注所述训练样本适用的场景;
4、基于所述场景标签将所述训练样本划分为多个批次组,其中,每个所述批次组包含属于同一场景的预设数量的训练样本;
5、对多个所述批次组进行随机排序,生成用于训练所述对话生成模型的目标训练数据集;
6、根据所述目标训练数据集,对预设的神经网络模型进行训练,得到所述对话生成模型。
7、根据本发明的第二个方面,提供了一种对话生成模型的训练装置,该装置包括:
8、数据获取模块,同于获取对话生成模型的训练数据集,其中,所述训练数据集包括多个预设有场景标签的训练样本,所述场景标签用于标注所述训练样本适用的场景;
9、样本分组模块,用于基于所述场景标签将所述训练样本划分为多个批次组,其中,每个所述批次组包含属于同一场景的预设数量的训练样本;
10、数据生成模块,用于对多个所述批次组进行随机排序,生成用于训练所述对话生成模型的目标训练数据集;
11、模型训练模块,用于根据所述目标训练数据集,对预设的神经网络模型进行训练,得到所述对话生成模型。
12、根据本发明的第三个方面,提供了一种存储介质,其上存储有计算机程序,所述程序被处理器执行时实现上述对话生成模型的训练方法。
13、根据本发明的第四个方面,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述对话生成模型的训练方法。
14、本发明提供的一种对话生成模型的训练方法、装置、存储介质及计算机设备,能够对训练数据集中适用于不用场景的训练样本点进行分类,将适用于同一场景的训练样本在训练批次层面中进行分场景汇聚,使模型能够在适用于同一场景的训练样本下实现快速的收敛,加快模型的训练速度。同时,对批次组进行随机排序得到目标训练数据集,使基于目标训练数据集对对话生成模型进行训练时,不会出现因为训练数据集中某个场景的训练数据离训练数据集的末端太远,而导致的灾难性遗忘的情况发生,进而有效提高了对对话生成模型的训练效果,提升了对话生成模型的性能。
15、上述说明仅是本申请技术方案的概述,为了能够更清楚了解本申请的技术手段,而可依照说明书的内容予以实施,并且为了让本申请的上述和其它目的、特征和优点能够更明显易懂,以下特举本申请的具体实施方式。
技术特征:
1.一种对话生成模型的训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述基于所述场景标签将所述训练样本划分为多个批次组,包括:
3.根据权利要求2所述的方法,其特征在于,所述对多个所述批次组进行随机排序,生成用于训练所述对话生成模型的目标训练数据集,包括:
4.根据权利要求2所述的方法,其特征在于,所述将所述场景组内的多个所述训练样本划分为多个批次组,包括:
5.根据权利要求1-4任一项所述的方法,其特征在于,所述根据所述目标训练数据集,对预设的神经网络模型进行训练,得到所述对话生成模型之前,所述方法还包括:
6.根据权利要求1-4任一项所述的方法,其特征在于,所述根据所述目标训练数据集,对预设的神经网络模型进行训练,得到所述对话生成模型之前,所述方法还包括:
7.根据权利要求1-4任一项所述的方法,其特征在于,所述根据所述目标训练数据集,对预设的神经网络模型进行训练,得到所述对话生成模型之前,所述方法还包括:
8.一种对话生成模型的训练装置,其特征在于,所述装置包括:
9.一种存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至7中任一项所述的方法的步骤。
10.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至7中任一项所述的方法的步骤。
技术总结
本发明公开了一种对话生成模型的训练方法、装置、存储介质及计算机设备,涉及人工智能及智慧医疗技术领域。其中方法包括:获取对话生成模型的训练数据集,其中,训练数据集包括多个预设有场景标签的训练样本,场景标签用于标注训练样本适用的场景;基于场景标签将训练样本划分为多个批次组,其中,每个批次组包含属于同一场景的预设数量的训练样本;对多个批次组进行随机排序,生成用于训练对话生成模型的目标训练数据集;根据目标训练数据集,对预设的神经网络模型进行训练,得到对话生成模型。上述方法能够从历史的对话样本中,生成按照适用场景随机排序的批次组,并基于该训练数据集对对话生成模型进行训练,提升模型的性能。
技术研发人员:刘佳瑞,王世朋,姚海申,孙行智
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!