一种智慧林业信息传输涉密脱敏系统的制作方法
本技术涉及数据脱敏,尤其涉及一种智慧林业信息传输涉密脱敏系统。
背景技术:
1、目前,防止数据泄露的方法大致可以分为三大类:安全审计类,安全控制类和文件加密类。其中,敏感数据的识别技术对于数据防泄露的安全控制起到很好的辅助作用。如果可以智能化识别传输的文档信息中哪些是敏感数据并加以保护,那么可以很大程度简化人工设置标识或者是访问控制规则的复杂度并且有效防止敏感数据的泄露。
2、目前对敏感数据的识别主要是对文本、web、图像、视频等文件格式的识别,主要广泛应用的是基于文本的数据防泄露,但是在以往的文本识别算法研究中,文本预处理过程较为复杂,也缺乏灵活的阙值确定机制。
技术实现思路
1、本技术提出了一种一种智慧林业信息传输涉密脱敏系统,具备智能确定阙值,且阙值更精确的优点,用以解决文本预处理过程较为复杂,也缺乏灵活的阙值确定机制问题。
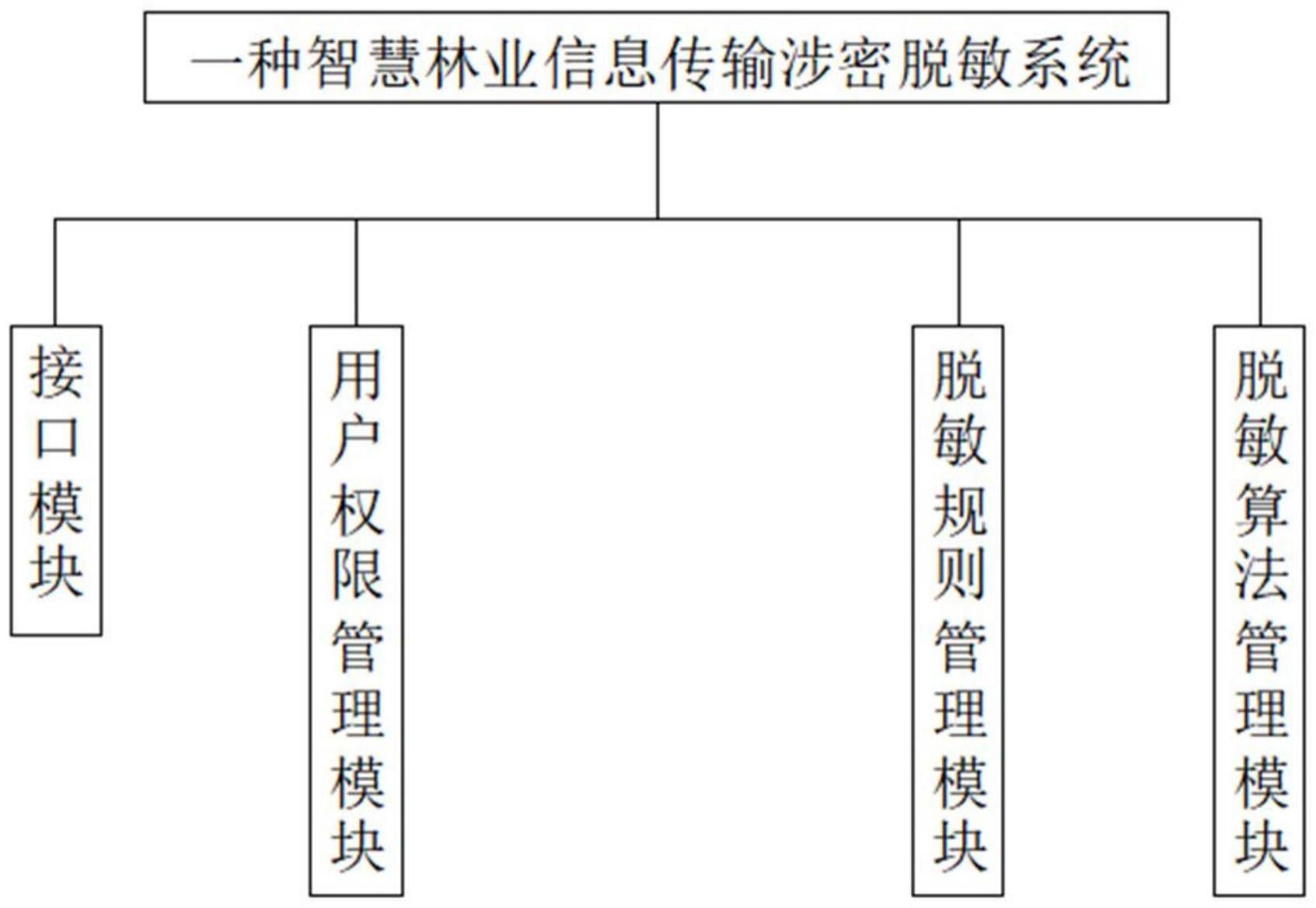
2、为达到上述目的,本技术采用如下技术方案:一种智慧林业信息传输涉密脱敏系统,包括:接口模块、用户权限管理模块、脱敏规则管理模块和脱敏算法管理模块,
3、所述接口模块用于连接其他业务系统或者管理系统;
4、所述用户权限管理模块对用户在脱敏系统的查阅权限进行限定;
5、所述脱敏规则管理模块用于根据脱敏数据使用环境选择脱敏规则;
6、所述脱敏算法管理模块用于管理多种脱敏算法。
7、进一步,所述脱敏算法包括基于文本内容的敏感数据识别算法,其对敏感数据的识别过程如下:
8、步骤一、敏感数据文本库进行预处理和特征提取之后,通过tfidf算法进行向量空间权值计算,形成数据特征向量;
9、步骤二、已知分类的文本库进行预处理和特征提取之后,通过tfidf算法计算向量空间权值形成数据特征向量,与敏感数据形成的特征向量进行余弦计算,并统计学习,根据阙值确定方法;
10、步骤三、将待判断的未知分类的文档进行预处理和特征提取,通过tfidf算法计算向量空间权值形成数据特征向量后,与敏感数据的特征向量进行余弦计算,将得到的余弦值与阙值进行比较,判断是否是敏感数据。
11、进一步,所述文本分类包括以下步骤:
12、步骤一、建立数据集,包含训练集和测试集;
13、步骤二、建立文本表示模型并进行文本特征选择;
14、步骤三、在训练集上进行机器学习,建立分类器;
15、训练集包含敏感文本库和已知分类文本库,所述敏感文本库为包含敏感数据文档的词库,所述分类文本库包括敏感数据和非敏感数据词库。
16、进一步,所述预处理过程为:
17、将中文的文本划分为单个的词组并标注词性、词长、词频;
18、文档集合t_pre={t1,t2,...,ti}通过ictclas分词接口,将文本文件进行分词,并在分词的同时统计词长和对词性进行标记;
19、文本文件ti分词后表示为:
20、ti=((ai1,li1,pi1),(ai2,li2,pi2),...,(ain,lin,pin))
21、其中,ti表示文本i,ain表示划分出来的词组,lin表示词组长度,pin表示划分出来的词组的词性。
22、进一步,所述特征提取过程如下:
23、词性选择:文本文件ti经过词性选择后,表示为:
24、
25、其中,表示提取名词之后的文本,(ain,lin’)∈ti且ain为名词;
26、词频统计:统计关键字出现的频率,形成分词三元组,包含词组,词组在本文本中出现的频率和词性;
27、将增加一个词频项,表示为:
28、
29、其中,表示统计词频之后的文本,fin’表示ain’的词频;
30、词长选择:计算每个关键字的长度并删除单个字的关键词,表示为:
31、
32、其中,表示统计频率之后的文本表示,ain”为长度大于一个字的关键词;
33、词频选择:剔除统计后的文本分词三元组中只出现过一次的词组,得到:
34、
35、其中,表示统计频率之后的文本,fim>1。
36、进一步,所述特征向量计算过程如下:
37、经过预处理和特征选择之后的敏感数据文档库表示为:
38、t={td1,td2,...,tdn,}
39、其中,文本tdi的特征向量表示为表示统计频率之后的文本,fim>1;
40、根据得到的关键字,经过tfidf算法计算,将敏感数据用向量表示,得到敏感数据的特征向量v;
41、tfidf算法公式为:dij=tij*log(n/nj),其中,tij表示词组aij在文本ti中出现的次数,等于中的fim,n表示文档总数,nj表示文档库中包含词组aij的文档个数;由敏感数据组成的特征向量表示为:
42、v=((a11,d11),(a12,d12),...,(a1m,d1m),...,(an1,dn1),(an2,dn2),...,(amn,dmn))
43、简记为:v=(d11,d12,...,d1m,...,dn1,dn2,...,dmn);
44、根据敏感数据特征向量v计算对应关键词aij在已知分类的文档库中的权值,得到特征向量如下:
45、v’
46、=((a11,d’11),(a12,d’12),...,(a1m,d’1m),...,(an1,d’n1),(an2,d’n2),...,(amn,dmn))
47、简记为:v’=(d’11,d’12,...,d’1m,...,d’m1,d’n2,...,d’mn);
48、同样,得到未知分类文档的特征向量v”,
49、v”=(d”11,d”12,...,d”1m,...,d”n1,d”n2,...,d”mn)
50、其中,v’中的amn与敏感数据特征向量v中的amn相等。
51、进一步,所述余弦值计算公式为:
52、
53、其中,v1和v2是两个文档的特征向量,v1·v2为标准向量点积,定义为分母中的范数||v1||定义为
54、进一步,所述确定阙值的方法如下:
55、收集安全文件和敏感文件的词库,通过处理与敏感集进行余弦计算,得到值;
56、通过确定相同间隔的阙值,进行是否敏感数据的判断,找到错误率最低的那个阙值作为后面进行未知文档判断的阙值;
57、误判率如下所示:
58、其中,a表示被正确识别为安全文档的文档数,b表示被错误的识别为敏感文档的文档数,c表示被错误识别为安全文档的文档数,d表示被正确势必额为敏感文档的文档数。
59、1、本技术提供的一种智慧林业信息传输涉密脱敏系统,通过一种以磁性、词频、词长为参数的简便有效的文本特征提取方法,并通过智能自学习的方式确定阙值,判断文档是否属于敏感属于的方法,与传统人工确认阙值的方法相比具有更高的实用性、准确性和灵活性,实现了对数据的脱敏保密处理。
60、2、本技术提供的一种智慧林业信息传输涉密脱敏系统,通过在预处理之后的分词结果进行提取,降低向量空间的维度,使特征更具有代表性,计算也更加简便有效,避免在文本学习和识别过程中,将所有磁性的分词都作为关键词导致的计算量增大的问题,且也避免了冗余信息,提高了特征向量的精确性以及计算的速度。
- 还没有人留言评论。精彩留言会获得点赞!