异构数据的聚类整合方法、装置、设备及存储介质与流程
本发明涉及异构重组领域,尤其涉及一种异构数据的聚类整合方法、装置、设备及存储介质。
背景技术:
1、报表是一种数据统计方法,利用图形表格来更直观的显示各类数据。随着现代企业管理技术的发展与应用,企业需要更加高效的报表来处理大量的数据和展示数据处理结果。传统的报表工具通常作为信息管理系统的子功能,针对企业某部门的特定项目需求进行定制开发。这种定制化的报表一旦需要的数据或者格式发生改变,则需要进行重新开发,该方式很大程度上降低了企业工作效率。而且需要投入专门的人力和财力来维护开发好的报表系统,增大了企业的运营成本。而自定义报表技术对于报表格式的更改无需修改程序或重新编译,可以根据用户的需求快捷灵活的绘制报表,实现报表的高效管理。
2、目前,各行业、企业各部门的应用系统经过多年的使用,积累了丰富的数据,这些数据在企业的经营与决策都是必不可少的重要依据。然而这些丰富的数据资源由于建设时期不同、开发部门不同、使用设备不同、技术发展阶段不同和能力水平的不同等,数据存储管理极为分散,造成了过量的数据冗余和数据不一致性,使得数据资源难于查询访问,企业管理层无法获得有效的决策数据支持。因此为了提高信息资源的利用程度,需要将不同数据信息库中的数据集成到一个平台上集中管理和使用,同时利用自定义报表系统快速生成各类相关的数据报表供企业决策。
3、在这个过程中,需要解决的问题是不同数据信息库中的异构数据整合问题。这类数据异构问题通常是由于数据的多源性导致的,由于这些数据保存于不同的信息系统,其标注标准及标注人员的水平均存在差异。因此,针对当前异构数据导致数据无法通用管理的问题,需要一种新的技术。
技术实现思路
1、本发明的主要目的在于解决当前异构数据导致数据无法通用管理的技术问题。
2、本发明第一方面提供了一种异构数据的聚类整合方法,所述异构数据的聚类整合方法包括:
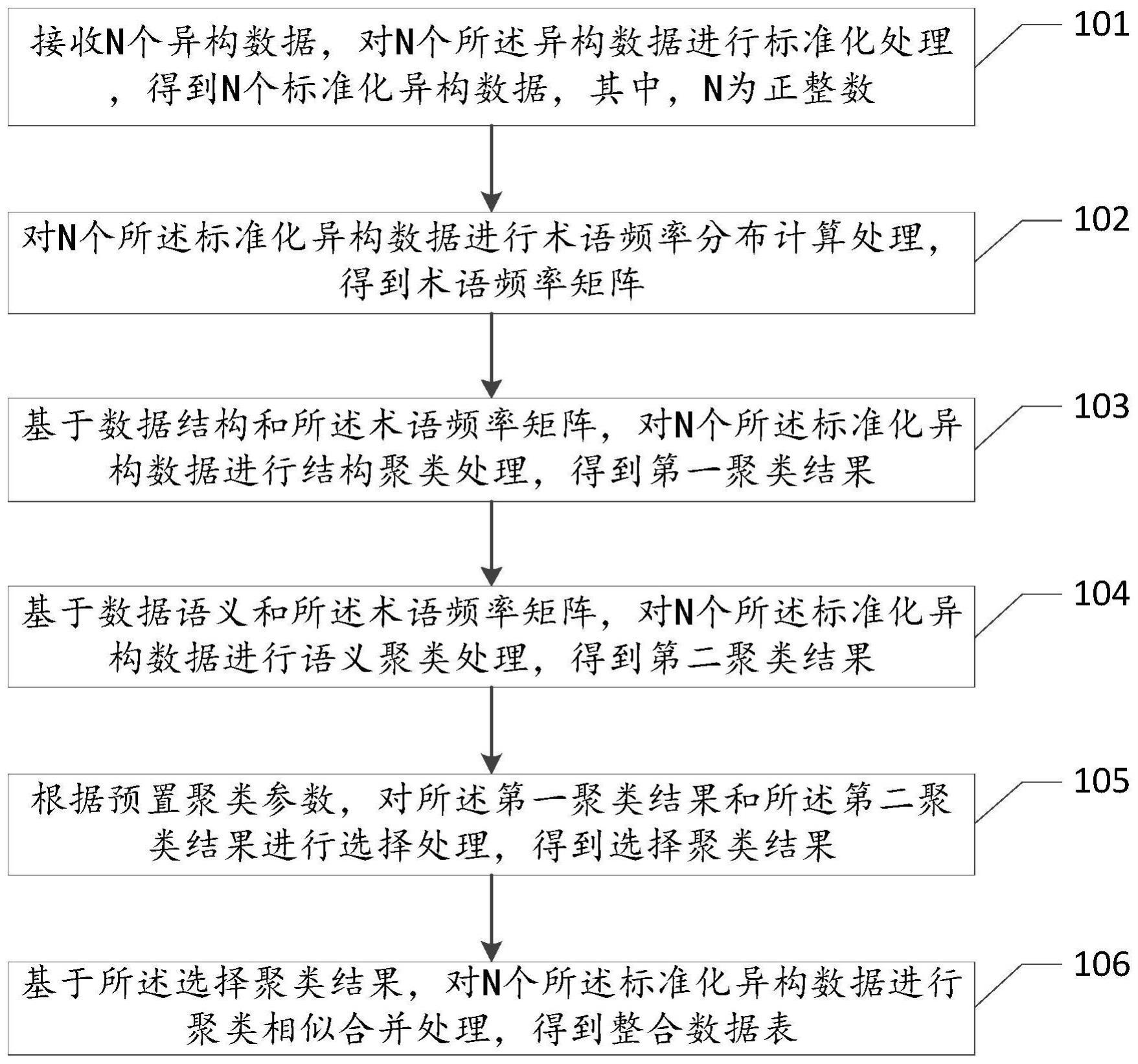
3、接收n个异构数据,对n个所述异构数据进行标准化处理,得到n个标准化异构数据,其中,n为正整数;
4、对n个所述标准化异构数据进行术语频率分布计算处理,得到术语频率矩阵;
5、基于数据结构和所述术语频率矩阵,对n个所述标准化异构数据进行结构聚类处理,得到第一聚类结果;
6、基于数据语义和所述术语频率矩阵,对n个所述标准化异构数据进行语义聚类处理,得到第二聚类结果;
7、根据预置聚类参数,对所述第一聚类结果和所述第二聚类结果进行选择处理,得到选择聚类结果;
8、基于所述选择聚类结果,对n个所述标准化异构数据进行聚类相似合并处理,得到整合数据表。
9、可选的,在本发明第一方面的第一种实现方式中,,所述基于数据语义和所述术语频率矩阵,对n个所述标准化异构数据进行语义聚类处理,得到第二聚类结果包括:
10、基于n个所述标准化异构数据与所述术语频率矩阵的映射关系,将所述术语频率矩阵拆分为n个术语频率向量,得到n个所述标准化异构数据对应的n个术语频率向量;
11、基于预置映射网络,将所述n个术语频率向量进行节点映射处理,得到m个输出节点,其中,m为正整数;
12、基于预置距离公式,计算出节点距离dij,其中,所述距离公式包括:
13、
14、为第i个术语频率向量在t时刻的值,wij为第i个术语频率向量至第j个输出节点的权重向量,dij为第i个术语频率向量至的第j个输出节点的节点距离;
15、根据预置竞赛学习算法,对所述节点距离dij进行自适应权重修改处理,得到第二聚类结果。
16、可选的,在本发明第一方面的第二种实现方式中,所述基于数据结构和所述术语频率矩阵,对n个所述标准化异构数据进行结构聚类处理,得到第一聚类结果包括:
17、根据预置莱文斯坦距离算法,对所述术语频率矩阵计算处理,得到所述术语频率矩阵对应的莱文斯坦距离矩阵;
18、基于预置k-means算法,对所述莱文斯坦距离矩阵进行聚类迭代处理,得到第一聚类结果。
19、可选的,在本发明第一方面的第三种实现方式中,所述根据预置聚类参数,对所述第一聚类结果和所述第二聚类结果进行选择处理,得到选择聚类结果包括:
20、基于预置衡量公式,计算出聚类参数,其中,所述衡量公式包括:
21、q=a*max1(n)+(1-a)max2(n)
22、其中,a为预设权重系数,max1(n)为第一聚类结果的最大值,max2(n)为第二聚类结果的最大值,q为聚类参数;
23、根据预置选择规则和所述聚类参数,对所述第一聚类结果和所述第二聚类结果进行选择处理,得到选择聚类结果。
24、可选的,在本发明第一方面的第四种实现方式中,所述基于所述选择聚类结果,对所述标准化异构数据进行聚类相似合并处理,得到整合数据表包括:
25、基于所述选择聚类结果,对n个所述标准化异构数据进行相似度筛选处理,得到2个相似的标准化异构数据和n-2个剩余的标准化异构数据;
26、将2个相似的标准化异构数据进行组合处理,得到初步整合异构数据;
27、对初步整合异构数据进行空值删除处理,得到去空整合异构数据;
28、基于所述选择聚类结果,对所述去空整合异构数据进行相似度行列合并处理,得到合并的标准化异构数据;
29、将所述合并的标准化异构数据确定为整合数据表。
30、可选的,在本发明第一方面的第五种实现方式中,所述将所述合并的标准化异构数据确定为整合数据表包括:
31、将所有剩余的标准化异构数据存在与合并的标准化异构数据进行相似度筛选处理,得到筛选结果;
32、判断所述筛选结果是否为空;
33、若不为空,则将2个相似的标准化异构数据进行组合处理,得到初步整合异构数据,进行循环处理;
34、若为空,则将合并的标准化异构数据确定为整合数据表。
35、可选的,在本发明第一方面的第六种实现方式中,所述接收n个异构数据,对n个所述异构数据进行标准化处理,得到n个标准化异构数据包括:
36、接收n个异构数据;
37、删除n个所述异构数据中空值大于删除阈值的列,得到n个第一清除异构数据;
38、基于预置字符表,删除n个所述第一清除异构数据中的特定字符,得到n个第二清除异构数据;
39、根据预置词根映射表,对n个所述第二清除异构数据进行词根映射处理,生成n个标准化异构数据。
40、本发明第二方面提供了一种异构数据的聚类整合装置,所述异构数据的聚类整合装置包括:
41、标准化模块,用于接收n个异构数据,对n个所述异构数据进行标准化处理,得到n个标准化异构数据,其中,n为正整数;
42、分布计算模块,用于对n个所述标准化异构数据进行术语频率分布计算处理,得到术语频率矩阵;
43、结构聚类模块,用于基于数据结构和所述术语频率矩阵,对n个所述标准化异构数据进行结构聚类处理,得到第一聚类结果;
44、语义聚类模块,用于基于数据语义和所述术语频率矩阵,对n个所述标准化异构数据进行语义聚类处理,得到第二聚类结果;
45、选择模块,用于根据预置聚类参数,对所述第一聚类结果和所述第二聚类结果进行选择处理,得到选择聚类结果;
46、相似合并模块,用于基于所述选择聚类结果,对n个所述标准化异构数据进行聚类相似合并处理,得到整合数据表。
47、本发明第三方面提供了一种异构数据的聚类整合设备,包括:存储器和至少一个处理器,所述存储器中存储有指令,所述存储器和所述至少一个处理器通过线路互连;所述至少一个处理器调用所述存储器中的所述指令,以使得所述异构数据的聚类整合设备执行上述的异构数据的聚类整合方法。
48、本发明的第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行上述的异构数据的聚类整合方法。
49、在本发明实施例中,通过利用信息检索技术、聚类方法和训练的神经网络,将源中存在的语法/语义相似的实体合并。该方法属于一种多源异构数据整合方法,并且能够在数据整合过程中不需要人员参与,提高了自定义报表系统的效率,解决了当前异构数据导致数据无法通用管理的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!