文字识别方法、装置、存储介质及电子设备与流程
本公开涉及计算机,具体涉及一种文字识别方法、装置、存储介质及电子设备。
背景技术:
1、当前各行业的信息化进程不断加快,文字识别技术在工作和学习的过程中发挥着越来越重要的作用,在文字识别技术的帮助下,可以大幅度提升工作和学习的效率,减轻负担。例如在教育场景中,书籍、试卷和幻灯片等常见的教学素材中往往包含大量的文字,诸如试卷题目归档、书籍转可编辑格式等常见的教学任务中均采用文字识别技术来提高效率。
2、然而,在很多场景下,文字的表现形式多种多样,并且常规的通过对文字进行拍照取样并进行识别的方法,均受限于拍照角度和教学素材本身的特性,使得拍照时易产生图像的畸变或者文字形态的扭曲,从而导致文字识别的准确率降低。
技术实现思路
1、为克服相关技术中存在的问题,本公开提供一种文字识别方法、装置、存储介质及电子设备。
2、根据本公开实施例的第一方面,提供一种文字识别方法,包括:
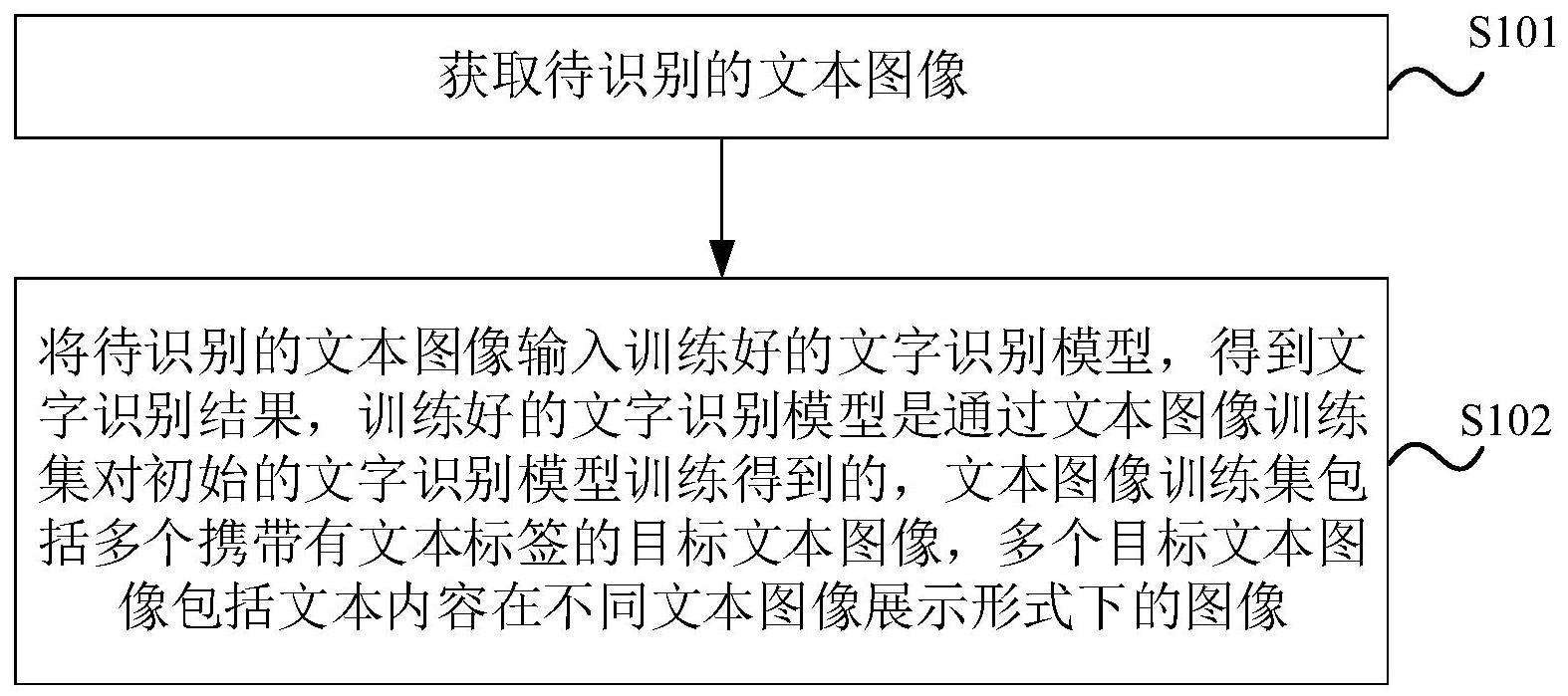
3、获取待识别的文本图像;
4、将所述待识别的文本图像输入训练好的文字识别模型,得到文字识别结果,所述训练好的文字识别模型是通过文本图像训练集对初始的文字识别模型训练得到的,所述文本图像训练集包括多个携带有文本标签的目标文本图像,多个所述目标文本图像包括文本内容在不同文本图像展示形式下的图像。
5、可选地,所述文本图像训练集通过以下步骤获得:
6、获取携带有文本标签的初始文本图像;
7、随机调整所述初始文本图像中的文字的颜色,得到第一文本图像;
8、融合所述第一文本图像以及预设类型的背景图像,获得第二文本图像;
9、对所述第二文本图像进行图像增强处理,得到第三文本图像,所述图像增强处理包括图像对比度调节、图像亮度调节和文字扭曲度调节中的至少一种;
10、将所述第二文本图像以及所述第三文本图像作为所述目标文本图像,获得所述文本图像训练集。
11、可选地,所述预设类型的背景图像包括扫描背景、纸张背景、高斯噪声背景以及混合背景,所述混合背景是基于所述纸张背景以及所述高斯噪声背景得到的;
12、所述训练好的文字识别模型通过以下步骤得到:
13、基于属于所述扫描背景的第二文本图像,对所述初始的文字识别模型进行训练,获得第一模型;
14、基于属于所述扫描背景的第二文本图像以及所述第三文本图像,对所述第一模型进行训练,获得第二模型;
15、基于属于所述纸张背景的第二文本图像以及属于所述高斯噪声背景的第二文本图像,对所述第二模型进行训练,获得第三模型;
16、基于属于所述纸张背景的第二文本图像、属于所述高斯噪声背景的第二文本图像以及属于所述混合背景的第二文本图像,对所述第三模型进行训练,获得第四模型;
17、基于属于所述扫描背景的第二文本图像、属于所述纸张背景的第二文本图像、属于所述高斯噪声背景的第二文本图像、属于所述混合背景的第二文本图像以及所述第三文本图像,对所述第四模型进行训练,获得所述训练好的文字识别模型。
18、可选地,所述文字识别模型包括特征提取网络、语义分割网络和序列识别网络,所述将所述待识别的文本图像输入训练好的文字识别模型,得到文字识别结果,包括:
19、将所述待识别的文本图像输入所述特征提取网络,得到视觉特征向量;
20、将所述视觉特征向量输入所述语义分割网络,得到语义分割向量,所述语义分割网络用于对所述视觉特征向量进行像素级别的语义分割处理;
21、将所述视觉特征向量和所述语义分割向量输入所述序列识别网络,得到所述文字识别结果。
22、可选地,所述特征提取网络包括依次连接的第一卷积组件、第二卷积组件以及最大池化层;
23、所述第一卷积组件包括依次连接的第一卷积子单元和第二卷积子单元,所述第一卷积子单元用于对所述待识别的文本图像进行下采样,得到第一特征向量,所述第二卷积子单元用于对所述第一特征向量进行卷积操作,得到第二特征向量;
24、所述第二卷积组件包括第三卷积子单元和第四卷积子单元,所述第三卷积子单元用于对所述第二特征向量进行下采样,得到第三特征向量,并增加所述第三特征向量的通道数,所述第四卷积子单元对所述第三特征向量进行残差映射处理,得到第四特征向量。
25、所述最大池化层用于对所述第四特征向量进行降维处理,得到所述视觉特征向量。
26、可选地,所述语义分割网络包括编码器、解码器以及卷积核,包括:
27、所述编码器对所述第二特征向量进行下采样,得到第二视觉特征向量;
28、所述解码器用于根据所述第二特征向量、所述第三特征向量以及所述第四特征向量,对所述第二视觉特征向量进行上采样,得到第三视觉特征向量;
29、所述卷积核用于对所述第三视觉特征向量进行像素级别的语义分割处理,得到所述语义分割向量。
30、可选地,所述将所述视觉特征向量和所述语义分割向量输入所述序列识别网络,得到所述文字识别结果,包括:
31、对所述语义分割向量进行下采样,得到下采样后的语义分割向量;
32、对所述下采样后的语义分割向量进行维度拓展,得到目标语义分割向量,所述目标语义分割向量与所述视觉特征向量的维度一致;
33、将所述目标语义分割向量与所述视觉特征向量进行特征融合,得到融合特征向量;
34、根据所述融合特征向量得到所述文字识别结果。
35、根据本公开实施例的第二方面,提供一种文字识别装置,包括:
36、获取模块,用于获取待识别的文本图像;
37、文字识别模块,用于将所述待识别的文本图像输入训练好的文字识别模型,得到文字识别结果,所述训练好的文字识别模型是通过文本图像训练集对初始的文字识别模型训练得到的,所述文本图像训练集包括多个携带有文本标签的目标文本图像,多个所述目标文本图像包括文本内容在不同文本图像展示形式下的图像。
38、根据本公开实施例的第三方面,提供一种非临时性计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现第一方面任一项所述方法的步骤。
39、根据本公开实施例的第四方面,提供一种电子设备,包括:
40、存储器,其上存储有计算机程序;
41、处理器,用于执行所述存储器中的所述计算机程序,以实现第一方面任一项所述方法的步骤。
42、通过上述技术方案,基于多个目标文本图像包括文本内容在不同文本图像展示形式下的图像的文本图像训练集,进行模型训练得到文字识别模型,然后将待识别的文本图像输入训练好的文字识别模型,则可以得到文字识别结果。如此,由于进行模型训练的文本图像训练集中包括不同的文字展示形式,提高了文字识别模型的文字识别效果,进而提高了文字识别结果的准确度。
43、本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
技术特征:
1.一种文字识别方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述文本图像训练集通过以下步骤获得:
3.根据权利要求2所述的方法,其特征在于,所述预设类型的背景图像包括扫描背景、纸张背景、高斯噪声背景以及混合背景,所述混合背景是基于所述纸张背景以及所述高斯噪声背景得到的;
4.根据权利要求1-3任一项所述的方法,其特征在于,所述文字识别模型包括特征提取网络、语义分割网络和序列识别网络,所述将所述待识别的文本图像输入训练好的文字识别模型,得到文字识别结果,包括:
5.根据权利要求4所述的方法,其特征在于,所述特征提取网络包括依次连接的第一卷积组件、第二卷积组件以及最大池化层;
6.根据权利要求5所述的方法,其特征在于,所述语义分割网络包括编码器、解码器以及卷积核,包括:
7.根据权利要求4所述的方法,其特征在于,所述将所述视觉特征向量和所述语义分割向量输入所述序列识别网络,得到所述文字识别结果,包括:
8.一种文字识别装置,其特征在于,包括:
9.一种非临时性计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现权利要求1-7中任一项所述方法的步骤。
10.一种电子设备,其特征在于,包括:
技术总结
本公开涉及计算机技术领域,具体涉及一种文字识别方法、装置、存储介质及电子设备。该方法包括:获取待识别的文本图像;将所述待识别的文本图像输入训练好的文字识别模型,得到文字识别结果,所述训练好的文字识别模型是通过文本图像训练集对初始的文字识别模型训练得到的,所述文本图像训练集包括多个携带有文本标签的目标文本图像,多个所述目标文本图像包括文本内容在不同文本图像展示形式下的图像。由于进行模型训练的文本图像训练集中包括不同的文字展示形式,提高了文字识别模型的文字识别效果,进而提高了文字识别结果的准确度。
技术研发人员:王彦君
受保护的技术使用者:北京鼎事兴教育咨询有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!