一种面向联邦学习的群体众筹博弈的持续激励方法
本发明涉及一种面向联邦学习的群体众筹博弈的持续激励方法,属于无线通信。
背景技术:
1、近年来,随着物联网技术的快速发展,相关的智慧服务被广泛应用到智慧城市、森林检测、智慧海洋等场景中。据估计,到2030年全球物联网设备数量将超过100万亿。因此,物联网服务场景中海量数据的收集将面临巨大挑战。在此背景下,作为一种新兴的数据感知的范式,群体众筹技术应运而生。群体众筹通过用户间的协同合作,利用用户所携带设备提供的数据感知、计算及无线通信能力,完成大规模的数据感知服务,诸如环境监测、交通密度评估、城市规划、位置导航和医疗保健等。相比于传统数据感知技术,依赖昂贵的专用传感基础设施,群体众筹具备高敏捷性、高灵活性和低成本等优势。
2、一个典型的群体众筹的系统主要包括一个部署在云端的平台和一群移动用户,平台通过招募移动用户收集感知数据,通过用户的智能终端设备,完成大规模数据感知的众筹任务。然而,在执行众筹任务期间,用户需要上传将其感知数据(例如,每日轨迹、实时位置和周围环境),此类机制可能导致严重的数据安全风险,如隐私泄露、数据窃听和用户个人数据滥用。同时,随着边缘网络中物联网数据的爆炸式增长,将通过群体众筹收集的数据上传到远程服务器所耗费的网络资源和产生的通信延迟,不利于实际应用部署。因此,有必要进一步研究和改进相关技术,以弥补群体众筹技术中的不足。
3、联邦学习(federated learning,fl)作为一种新兴的分布式学习框架,可以用于构建智能和增强隐私的群体众筹应用。一方面,随着人工智能技术在智能终端设备中的应用得到了巨大的发展,智能终端设备可以通过专门的硬件架构和计算引擎,解决各种机器学习问题。根据gartner预测,到2022年,80%的智能手机将具备部署人工智能应用的能力,这为群体众筹系统中联邦学习的应用提供了基础条件。另一方面,据研究机构估计,超过90%的数据将在用户本地存储和处理(例如,在网络边缘层),这群体众筹系统中联邦学习的应用提供了广阔潜力。
4、通常情况下,联邦学习的用户在计算能力、数据资源等方面具有异构性,例如用户设备在硬件资源、网络连接及电源状态是各不相同的,同时由于用户的信誉特征,对收集的感知数据质量产生不同的影响。如何全面衡量用户对联邦学习的贡献,并选择高质量用户参与是一个十分关键的方向。如果选择参与联邦学习的用户如果没有足够的训练数据和计算能力,联邦学习的训练性能(例如,模型精度、训练速度)将大幅度恶化。同时,在选择用户参与前,对群体众筹平台来说用户质量是未知的。因此,设计合理的用户质量评估和学习策略至关重要。基于群体众筹的联邦学习系统中,用户具有独立性,只有用户自身才能决定何时、何地以及如何参与联邦学习。同时,在群体众筹系统中,联邦学习会消耗用户的大量资源,例如计算能力、通信带宽和私有数据等,将导致计算资源消耗、网络带宽使用和用户设备电池寿命缩短,其中一些可能会在移动通信网络等场景中受到限制。然而,如果没有足够的奖励可以激励用户容忍这些成本付出,用户可能不愿意参与联邦学习并分享其模型更新。因此,需要设计合理的激励机制来激励更多拥有高质量数据和充足计算与通信资源的用户参与联邦学习。
技术实现思路
1、本发明所要解决的技术问题是提供一种面向联邦学习的群体众筹博弈的持续激励方法,基于群智众筹招募用户参与联邦学习训练过程,通过所设计的激励机制选择高质量用户参与,并设计合理的酬金分配策略,同时确定每个用户的声誉值,给予额外的奖励激励用户持续参与联邦学习训练。
2、本发明为了解决上述技术问题采用以下技术方案:一种面向联邦学习的群体众筹博弈的持续激励方法,根据任务请求者的关于模型训练的群体众筹任务,群智众筹平台首先通过强化学习算法选择用户参与联邦学习过程,并基于双层stackelberg博弈确定用户的最优定价策略,同时确定每个用户的声誉值,给予额外的奖励激励用户持续参与联邦学习训练。
3、一种面向联邦学习的群体众筹博弈的持续激励方法,该方法包括:
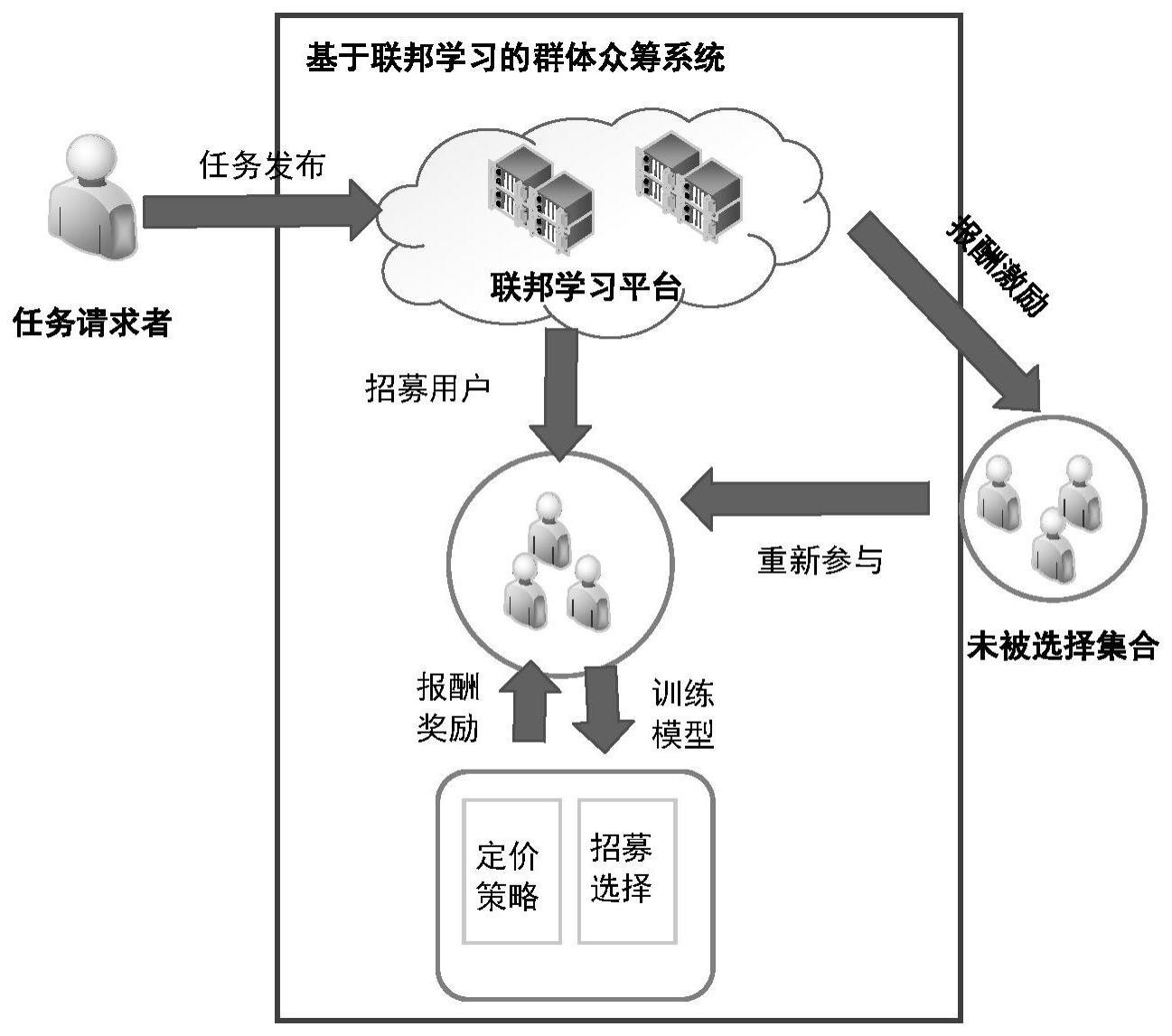
4、步骤1,任务请求者向联邦学习平台发布群体众筹任务;
5、步骤2,联邦学习平台招募用户参与联邦学习,在此过程中,联邦学习平台向任务请求者收取报酬,并向被招募的用户发放酬金,同时,在每个轮次中对上一轮次未被招募的用户给予额外的奖励;在每个轮次中,每个用户独立地决定是否参与群体众筹任务,并决定参与联邦学习的数据量。
6、进一步地,所述步骤1中群体众筹任务定义为其中,loc,b,k分别表示任务地点、任务预算和执行任务所需用户数,t表示最大轮次数,τmin表示每个轮次的最短截至期限。
7、进一步地,所述步骤2中联邦学习平台在t轮次中对用户i给予额外的奖励为:
8、
9、其中,ρ是用户单位声誉奖励,表示用户i在t轮次中的声誉值;表示用户i在t-1轮次中是否被招募,
10、进一步地,所述步骤2中联邦学习平台基于如下用户招募问题确定用户选择策略:
11、
12、
13、
14、其中,表示用户i在t轮次中用于模型训练的数据质量,t表示最大轮次数,δ表示用户i将被招募的所需轮次的最小值,k表示执行任务所需用户数,表示用户i在t轮次中是否被招募,
15、进一步地,所述步骤2中基于stackelberg博弈,确定用户的定价策略使得联邦学习平台效用最大化,确定用户参与联邦学习的数据量使得用户效用最大化。
16、进一步地,当用户的投资回报率低于设定阈值时,该用户退出该群体众筹任务,其中,用户的投资回报率的表达式为:
17、
18、其中,表示用户i在t轮次中的投资回报率,r(·)和c(·)分别表示用户i的累计报酬和成本,表示联邦学习平台在t轮次中对用户i给予额外的奖励,βi表示用户i的容忍系数。
19、进一步地,引入虚拟队列技术将用户招募问题扩展为:
20、
21、
22、
23、其中,vit表示用户i在t轮次中的虚拟队列长度,[·]+=max{·,0},vi1=0,表示用户i在t-1轮次中是否被招募,α≥0表示非负参数;
24、采用多臂赌博机模型中的ucb策略的思想,联邦学习平台为用户i维护一个二元组其中表示为用户i在t轮次中被联邦学习平台招募的次数,是用户i在t轮次中的平均数据质量,进而,将用户选择标准表示为:
25、
26、其中,ζ表示探索常数。
27、进一步地,用户效用函数表示如下:
28、
29、其中,表示联邦学习平台在t轮次中对用户i的定价,表示用户i在t轮次中参与联邦学习的数据量,表示在t轮次中不包含用户i的用户集合,表示正的归一化因子,qmax表示联邦学习平台预定义的最大训练数据集样本数,表示用户i在t轮次中参与联邦学习所获报酬,wij表示用户i是否被用户j所影响,表示用户j在t轮次中参与联邦学习的数据量,表示用户i的感知数据质量,κ2、κ3表示数据成本系数,κ4表示单位计算成本,eg表示全局迭代轮次,el表示用户局部迭代轮次,m表示模型的大小,κ5表示单位传输成本,pi表示用户i的传输功率,riup,t表示用户i在t轮次中的传输速率。
30、进一步地,联邦学习平台效用函数表示如下:
31、
32、其中,μ是一个可调参数,ε1和ε2均为系数。
33、进一步地,基于两阶段的stackelberg博弈的分配策略:
34、第一阶段,联邦学习平台确定定价策略以达到联邦学习平台效用最大化,其中,表示联邦学习平台在t轮次中对用户i的定价;
35、第二阶段,用户确定其训练策略以达到用户效用最大化,其中,表示用户i在t轮次中参与联邦学习的数据量;
36、首先,设置用户效用函数关于的一阶微分偏导数对所有用户,联立方程组,采用如下矩阵形式求解用户在t轮次中参与联邦学习的数据量的最优解
37、
38、其中,
39、然后,根据dt,*,利用逆向归纳法,融合到第一阶段的联邦学习平台最大效用博弈中,即联邦学习平台通过寻找最优定价策略最大化联邦学习平台效用,具体地为:
40、将dt,*带入联邦学习平台效用函数中,并令得到联邦学习平台效用函数的矩阵形式:
41、
42、设置关于pt的一阶微分偏导数求得最优定价策略
43、进一步地,用户i在t轮次中的声誉值的表达式如下:
44、
45、其中,分别代表用户i在t轮次中的积极行为和消极行为;
46、的更新机制如下:
47、
48、其中ρ1、ρ2分别表示用户积极行为和消极行为的单位更新强度,θ1、θ2分别表示用户积极行为和消极行为的放缩系数,σθ表示数据质量阈值;表示积极行为和消极行为的历史值,表示如下:
49、
50、
51、其中,分别代表用户i在ω轮次中的积极行为和消极行为,e-υ(t-x)表示时间衰减函数,ν表示时间衰减系数。
52、本发明所述一种面向室内定位联邦学习的群智众筹激励方法,采用以上技术方案与现有技术相比,具有以下技术效果:
53、本发明所设计一种面向室内定位联邦学习的群智众筹激励方法,应用联邦学习框架,基于群智众筹的思想招募用户参与,旨在有效激励联邦学习系统中的用户参与,同时提高用户间的公平性和解决可持续激励问题。首先针对用户感知数据质量,将用户选择问题建模为组合多臂赌博机问题,并引入虚拟队列技术,提高用户选择中的公平性。其次,将联邦学习的平台和用户交互建模为两阶段的stackelberg博弈,确定平台的最优定价策略和用户的最优训练策略。最后,对确保有足够的用户参与联邦学习训练过程,提出基于用户声誉的报酬激励策略。相对于现有方法具有明显提升。
- 还没有人留言评论。精彩留言会获得点赞!