基于轻量级注意力机制的水下图像色彩复原方法
本发明涉及水下图像增强领域,具体为一种基于轻量级注意力机制的水下图像色彩复原方法。
背景技术:
1、水下图像增强技术是目前水下图像处理技术的重要研究方向之一,能以较低的拍摄成本提高水下计算机视觉任务的完成效率,被广泛应用于海洋资源开发、利用、保护与管控等领域。目前,基于深度学习的水下图像增强算法为海洋渔业、海洋生态研究、海洋地形绘制等领域提供着越来越多的帮助。海洋环境复杂多变,水分子对自然光中红光的吸收、水体浓度不同对光的折射和水中悬浮颗粒对光的散射等物理现象,都会影响水下光摄影的成像效果。而海洋生物种类繁多,且多为小体积生物,对水下机器人的目标捕捉和识别的精度要求较高,虽然相机拍摄的光学图像细节丰富,但图像信息在水体产生的弱化作用影响下,仍无法达到要求,海洋地形的绘制同样需要较高精度,以确保其准确性。基于深度学习的图像增强算法可以更轻易的达到提取水下图像的深层信息的目的,进而使得算法在改善水下图像的清晰度方面更加的有利,同时也能调整水下图像的色调,提高水下机器人在海洋生物的识别、定位和跟踪任务的成功率,为海洋渔业发展、海洋生物研究提供技术支持。
2、就解决在水下摄影中存在的图像细节模糊、色彩失真等问题的处理方法而言,一般可以分为依托于水下成像模型的水下图像复原方法和与模型无关的水下图像增强方法两类。水下图像增强算法是采用数学方法对图像进行处理以使图像变得清晰而水下图像复原算法则是根据物理模型将图像还原为“陆上”图像。
3、基于深度学习的算法主要是基于端对端的图像增强原理,将成对的退化水下和清晰水下图像组成数据集,然后利用不同的深度学习框架搭建模型。li c等人基于卷积操作原理设计出一种名为uwcnn的算法(li c,anwar s,porikli f.underwater scene priorinspired deep underwater image and video enhancement[j].pattern recognition,2020,98:107038.)。该算法虽然能实现对退化的图像进行颜色订正的功能,输出的图像同样表现为模糊和平滑,但图像中的细节却不甚明晰,对局部色彩的校正也表现不佳。liu x等人基于条件生成对抗原理设计出一种名为mlfcgan的算法(liu x,gao z,chen bm.mlfcgan:multilevel feature fusion-based conditional gan for underwaterimage color correction[j].ieee geoscience and remote sensing letters,2019,17(9):1488-1492.)。该算法有着较好的局部色彩校正和全局色调处理的能力,但网络构成较复杂,模型所占内存较大,运行速度慢,且细节模糊。uplavikar p m等人基于领域对抗学习原理设计出一种名为uie-dal的算法(uplavikar p m,wu z,wang z.all-in-oneunderwater image enhancement using domain-adversarial learning[c]//cvprworkshops.2019:1-8.)。该算法生成的水下图像细节展现较佳但局部,尤其是分界处的色彩校正容易存在失真的现象。
技术实现思路
1、为了克服上述现有技术的不足,本发明提供了一种基于轻量级注意力机制的水下图像色彩复原方法,以解决传统增强算法在处理中存在的色彩失衡问题。
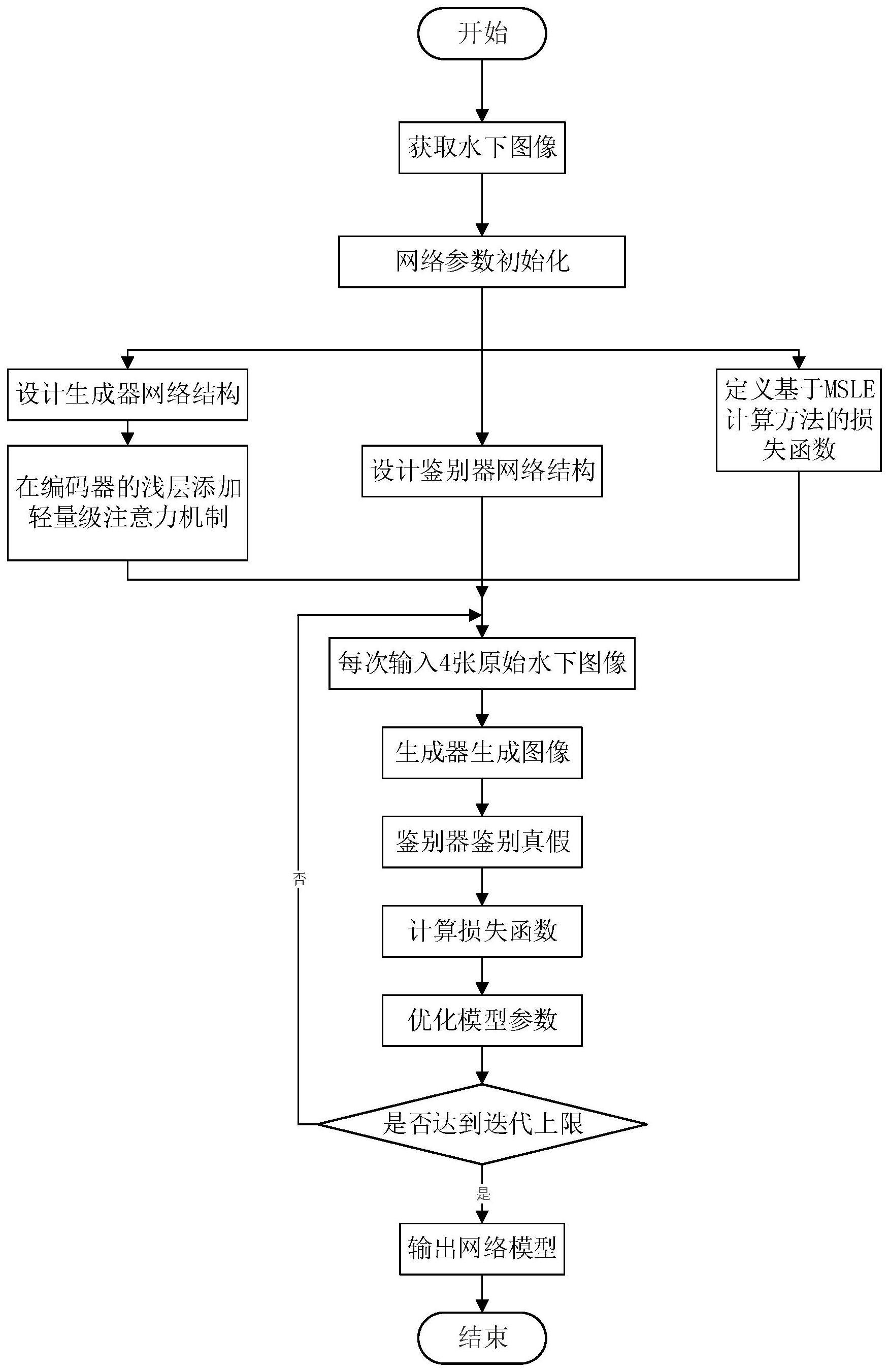
2、实现本发明目的的技术方案为:一种基于轻量级注意力机制的水下图像色彩复原方法,包括以下步骤:
3、步骤1、获取水下图像数据集,所述水下图像数据集由水下原始图像和对应的正常光图像组成;
4、步骤2、构建生成对抗网络模型,所述生成对抗网络模型包括生成器和鉴别器,所述生成器的网络结构为一种改进的u型语义分割模型,鉴别器的网络结构采用全卷积对抗网络结构;
5、步骤3、确定一个用以更新网络参数的基于均方对数误差计算方法的损失函数;
6、步骤4、使用水下图像数据集对设计好的网络结构进行训练,通过循环迭代不断优化网络,直至输出网络模型;
7、步骤5、将采集的水下原始图像输入训练好的生成对抗网络模型,获得清晰图像。
8、优选地,所述生成器包括输入层、隐藏层、输出层,所述输入层用于输入水下原始图像,所述隐藏层用于对输入图像进行卷积计算及反卷积计算,所述输出层用于输出结果;
9、隐藏层采用由4对编码层和译码层构成的编码器-译码器结构;
10、每一编码层的输出按照跳跃相连处理方法输入到镜像译码层。
11、优选地,所述生成器隐藏层的具体结构为:
12、编码层1:输入一张通道数为3的256*256的特征图,进行一次卷积和一次池化输出一张通道数为32的128*128的特征图;
13、编码层2:输入编码层1输出的特征图,进行两次卷积和一次池化,输出一张通道数为64的64*64的特征图;
14、编码层3:输入编码层2输出的特征图,进行两次卷积和一次池化,输出一张通道数为128的32*32的特征图;
15、编码层4:输入编码层3输出的特征图,进行一次卷积,输出一张通道数为256的32*32的特征图;
16、译码层1:输入编码层4输出的特征图,进行一次上采样,输出一张通道数为256的64*64的特征图;
17、译码层2:输入译码层1输出的特征图,将此特征图与编码层3输出的特征图进行拼接,拼接后进行一次卷积和上采样,输出一张通道数为256的128*128的特征图;
18、译码层3:输入译码层2输出的特征图,将此特征图与编码层2输出的特征图进行拼接,拼接后进行一次卷积和上采样,输出一张通道数为128的256*256的特征图;
19、译码层4:输入译码层3输出的特征图,在编码层1输出的特征图中加入轻量级注意力机制并将此特征图与上一层输出的特征图进行拼接,拼接后进行三次卷积,输出一张通道数为3的256*256的特征图。
20、优选地,所述鉴别器包括输入层、隐藏层、输出层,所述输入层用于输入总计大小为256*256*6的两张图片,所述隐藏层用于对输入图像进行卷积计算,所述输出层用于输出结果。
21、优选地,所述鉴别器隐藏层由5个卷积滤波器组成,具体为:
22、卷积层1:将总计大小为256*256*6的两张图片作为特征图输入,进行一次卷积输出一张通道数为32的128*128的特征图;
23、卷积层2:输入卷积层1输出的特征图,进行一次卷积,输出一张通道数为64的64*64的特征图;
24、卷积层3:输入卷积层2输出的特征图,进行一次卷积,输出一张通道数为128的32*32的特征图;
25、卷积层4:输入卷积层3输出的特征图,进行一次卷积,输出一张通道数为256的16*16的特征图;
26、卷积层5:输入卷积层4输出的特征图,进行一次卷积,输出16*16*1的信息分布矩阵。
27、优选地,步骤3中的损失函数为:
28、
29、式中,lcgan为鉴别网络patch gan计算的鉴别器损失,λ1和λc为超参数缩放因子,l1为提升图像的全局相似性的增加式,lcon为增强生成图像与目标图像间的构成内容相似性的增加式,g为与生成网络等价的映射,d为与鉴别网络等价的映射。
30、优选地,鉴别网络patch gan计算的鉴别器损失具体为:
31、lcgan(g,d)=ex,y[logd(y)]+ex,y[log(1-d(x,g(x,z)))]
32、其中,x和y分别代表需要增强的水下图像信息和增强后的水下信息,z代表输入的随机噪声,ex,y(*)表示在x、y作为自变量时分布函数的期望值。其中ex,y[log(1-d(x,g(x,z)))]为生成器损失函数,记为lg。
33、优选地,提升图像的全局相似性的增加式具体为:
34、l1(g)=ex,y,z[||y-g(x,z)||1]
35、式中,ex,y,z表示在x、y、z作为自变量时分布函数的期望值。
36、优选地,增强生成图像与目标图像间的构成内容相似性的增加式具体为:
37、lcon(g)=ex,y,z[||θ(y)-θ(g(x,z))||2]
38、其中,θ(·)代表公开的预训练vgg-19网络模型中的block5_conv2层拟合的特征提取映射函数,用于提取水下图像的图像内容特征信息。
39、优选地,步骤4中训练网络结构的具体步骤为:
40、将步骤1中的训练数据集输入生成对抗网络模型;
41、对指导训练过程的超参数进行定义;
42、生成器根据水下原始图像和随机噪声输出生成图;
43、鉴别器根据生成图和水下原始图像输出信息分布矩阵,利用均方对数误差计算方法计算矩阵与零矩阵的差值;
44、同时鉴别器根据对应的正常光图像和水下原始图像输出信息分布矩阵,利用均方对数误差计算方法计算矩阵与元素全为1的矩阵的差值;
45、将得到的两个差值取平均数即为鉴别器损失函数值,并通过采用adam优化器最小化鉴别器损失函数值来更新鉴别器的参数;
46、冻结鉴别器参数,将生成器生成图片与对应水下原始图像输入鉴别器获得鉴别器输出信息分布矩阵,利用均方对数误差计算方法计算该矩阵与零矩阵的差值,获得鉴别器损失lcgan;同时利用均方对数误差算方法计算生成器生成图片与对应水下原始图像的差值;
47、将差值带入公式计算得到全局相似性增加式l1和内容相似性增加式lcon;将lcgan、l1、lcon三者加权相加共同获得生成器损失函数值,并通过采用adam优化器最小化生成器损失函数值来更新生成器的参数;
48、通过循环执行上述过程不断更新生成器和鉴别器的参数以更新模型,直至循环结束;
49、在记录下的生成器损失函数值中选择对应最小损失函数值的模型作为最终模型。
50、本发明与现有技术相比,其显著优点为:(1)本发明设计网络结构,构建一种完全卷积的cgan模型,并在编码器-译码器的浅层加入轻量级注意力机制,更好地还原彩色,增加对比度;(2)本发明基于msle计算方法设计loss函数,提高其对水下图像深度学习特征的提取性能,减少水下图像细节损失。
51、下面结合说明书附图对本发明做进一步描述。
- 还没有人留言评论。精彩留言会获得点赞!