一种基于轻量级模型的实时图像去雾方法
本发明涉及图像去雾,特别涉及一种基于轻量级模型的实时图像去雾方法。
背景技术:
1、目标检测、分割、维修、压缩等多种计算机视觉工作取得了越来越精密的结果。但是,在有雾的天气下,如果照片输入中存在噪音、失真或损坏,则这些算法的性能可能会受到限制。这是由于水蒸气、沙子、灰尘、烟雾等小粒子悬浮在空气中时,摄像机吸收的光线产生衰减和散射,从而降低照片质量。因此,图像去雾是一项重要的底层视觉任务,其作为下游高层视觉任务的预处理,可以提高算法的精度,降低应用风险。
2、当前国际上,图像去雾主流的方法主要分为两类:第一类方法是基于先验知识进行去雾。最早使用的去雾方法是基于暗通道先验的方法(he,2010)。该方法假定所有受到雾影响的图像像素均在至少一个颜色通道内强度趋于零,该通道即为暗通道。但是,在天空像素中该先验条件很可能不满足,该区域颜色较亮,无法判断其是否受到雾气影响。此外,暗通道先验法具有较大的计算量。此外,基于半物理引导滤波的方法通过粗略估计雾的厚度图来恢复图像的纹理信息。一般来说,这些方法都受制于经验假设或者统计规律,这在一定程度上限制了应用场景。
3、第二类方法是基于神经网络的深度学习方法。基于深度学习的方法很多采用对称的编码器和解码器结构,其中最常见的网络结构是u-net。编码器用于提取图像多层级或多尺度的特征,解码器用于图像的高分辨率恢复,例如wavelet-u-net(yang,2019),msbdn(dong,2020)等。其次,多路网络也得到了广泛的应用。它们一般在多个并行的网络分支提取同一特征的不同层次信息,比如不同的颜色空间,例如review-net(mehra,2020),u-color(li,2021)等。因此,使用残差机制和注意力机制对特征进行整合和加权是大多数基于深度学习的方法必不可少的环节。但是,由于很多方法采用了模块堆叠的策略,它们不能很好地兼顾方法的准确率和实时性,同时还容易在训练集上发生过拟合。
4、综合上述分析可知,目前基于先验假设和统计分析的方法准确度较低,适用场景有限。基于深度学习的大多数图像去雾方法在复杂度和效率方面仍然存在较大不足,在有雾的天气条件下作为目标检测、分割等下游任务的预处理所需的处理时间过长,虽然能在一定程度上减轻雾霾对图像质量的影响,但在加入去雾预处理的步骤后系统不能对输入图像进行实时响应。
5、因此,目前的大多数图像去雾方法无法满足实际应用和部署的需求。如何有效地提取有雾图像的特征并利用其恢复无雾图像,并尽可能提高系统的响应速度是需要解决的主要问题。
技术实现思路
1、本发明的目的在于提供一种基于轻量级模型的实时图像去雾方法,解决了大多数图像去雾方法无法满足实际应用和部署的需求问题。
2、为实现上述目的,本发明采取的技术方案为:
3、本发明提供一种基于轻量级模型的实时图像去雾方法,包括以下步骤:
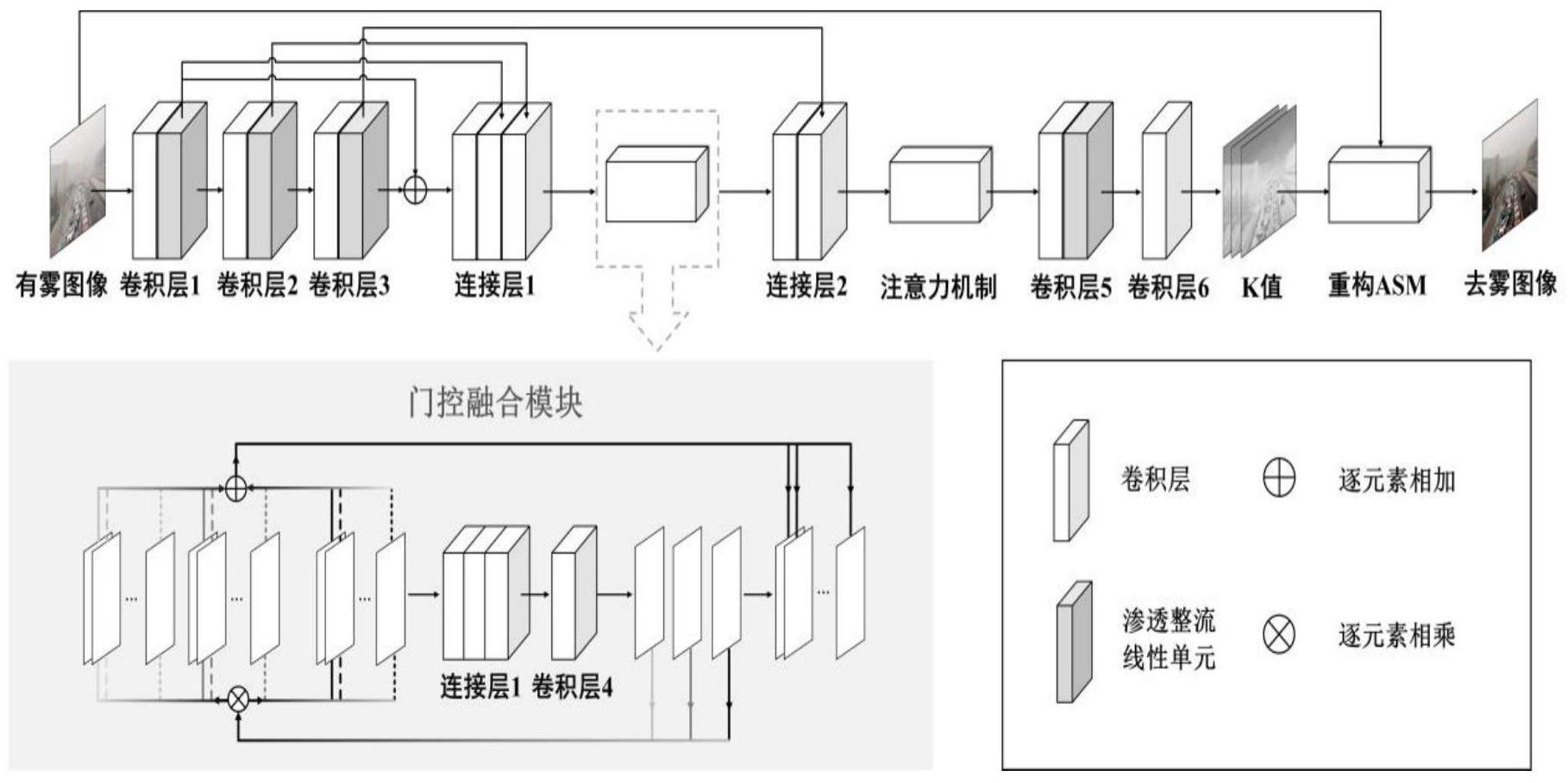
4、步骤a:获取待处理的原始带雾图像,采用卷积核大小递增的卷积操作序列,获取所述原始带雾图像的多层级特征;其中卷积核尺寸较小的卷积操作用于提取图像的低层级特征,卷积核尺寸较大的卷积操作用于提取图像的高层级特征;
5、步骤b:通过第一连接层将步骤a中的所述多层级特征进行合并;
6、步骤c:利用门控融合模块对步骤b中合并后的多层级特征进行特征交互,将不同层级的特征进行互补和融合;
7、步骤d:通过第二连接层将步骤a中的所述高层级特征与步骤c的输出再次进行连接和合并;
8、步骤e:采用注意力机制,对步骤d中所合并后的特征对于输出去雾参考的影响程度进行权衡;
9、步骤f:高分辨率重建,将步骤e中加权后的特征再次进行一系列的卷积操作,得到图像rgb三个通道的k值;
10、步骤g:将所述原始图像代入包含步骤f中所计算的k值的改进大气散射模型,得到与所述原始带雾图像相对应的去雾参考图像。
11、进一步地,所述步骤a中的卷积操作序列包括:卷积层1、卷积层2和卷积层3,卷积核大小分别为3×3,5×5和7×7;经过三个连续的卷积层后,将卷积层1和卷积层3之间进行像素级别的残差连接。
12、进一步地,所述步骤b中的第一连接层分别为卷积层1和卷积层3的残差加和、卷积层1以及卷积层2的输出。
13、进一步地,所述步骤c包括:
14、将所述第一连接层的三层信息作为门控融合模块的输入,所对应的特征图集合分别记为f1、f2和f3,第i层第j张特征图记为fi,j;
15、将三个集合的所有特征图经过卷积层4,得到三张特征图分别记为c1、c2和c3;
16、将所述三张特征图分别与f1、f2和f3像素级相乘,再将每一层对应位置的特征图进行像素级相加,则输出特征图中的第i层特征。
17、进一步地,所述步骤e包括:
18、采用由通道注意力模块和像素注意力模块组成的注意力机制;
19、其中,所述通道注意力模块对步骤d中所合并后的特征图使用全局平均池化,则第c张特征图的评价池化值mc,该特征图上的第s行、第t列元素值记为则mc用如下公式表示:
20、
21、其中,h、w分别为图片的高和宽;
22、再利用两个连续的卷积层和激活层进行变换,得到一个一维的权重向量,将该向量的第c个元素乘以第c张特征图,用如下公式表示:
23、
24、式中,和分别为两个卷积层,δ(·)和σ(·)分别为relu和sigmoid激活函数;为通道级别的一维权重向量,为像素级别的相乘,该一维权重向量与每个通道分别相乘,所得到的特征图集合为
25、所述像素注意力模块将通道注意力的输出特征图在像素尺度上进行变换,输出值为推导公式如下:
26、
27、其中,和分别为两个卷积运算,σ(·)为sigmoid激活函数。
28、进一步地,所述步骤f中高分辨率重建采用l2损失函数。
29、进一步地,所述步骤g中的改进大气散射模型的公式如下:
30、j(θ)=k(θ)×i(θ)-k(θ)+b
31、式中,k(θ)表示联合全球大气光a和透射图t后的合并变量k,用如下公式表示:
32、
33、式中,a为常数,表示全球大气光;t为每个元素范围在(0,1]的透射图;θ为h×w图像的像素坐标;i和j分别为有雾的输入图像和无雾参考输出的图像;b为默认常数,在实验中设置为1。
34、与现有技术相比,本发明具有如下有益效果:
35、(1)该方法采用改进大气散射模型联合估计大气光和透射图,能够保证修复图像的真实性,并提高图像的实时去雾效率。此外,该方法主要由卷积层和连接层组成,具有简洁的架构;无需占用载体的过多资源;
36、(2)该方法通过门控融合模块和注意力机制进行特征交互,能够有效进行多层级特征的提取、融合和加权,避免了复杂的结构设计和模块堆叠,很大程度上降低了参数量;进一步提高图像的实时去雾效率;
37、(3)该方法由于较低的参数量不易在训练集上产生过拟合,能较好地应对多种实际场景,能够克服常见的人工伪影、色泽不均等问题;能够在有雾的行车、视频监控、遥感等场景下提高目标检测的性能。
- 还没有人留言评论。精彩留言会获得点赞!