一种湖仓一体架构的制作方法
本发明涉及数据仓库,更具体地说,涉及一种湖仓一体架构。
背景技术:
1、数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的。但是,数据仓库通常是t+1进行更新,时效性比较低。
技术实现思路
1、本发明的目的是提供一种湖仓一体架构,能够解决现有的数据仓库时效性比较低的问题。
2、为了实现上述目的,本发明提供如下技术方案:
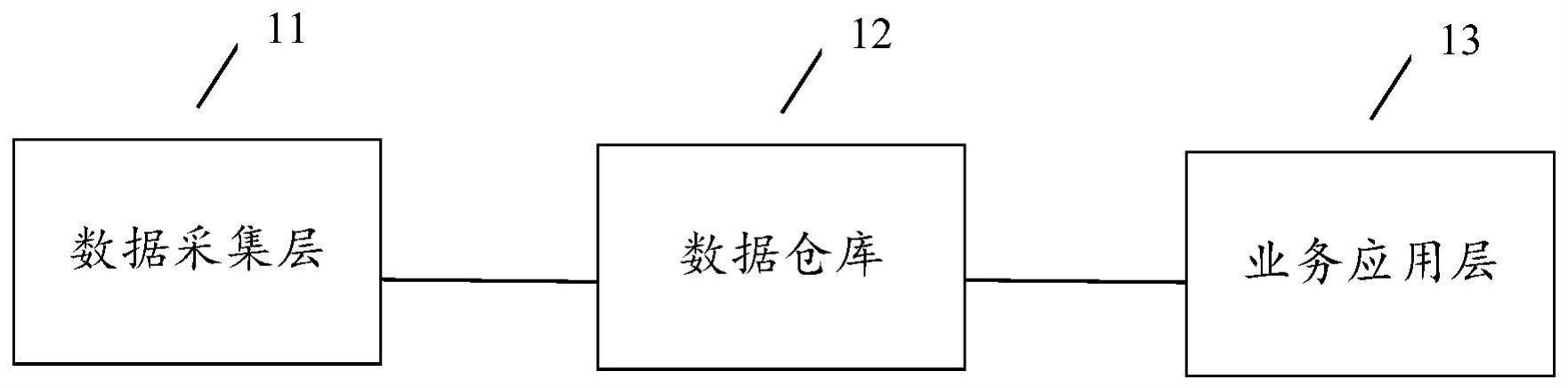
3、一种湖仓一体架构,包括数据采集层、数据仓库及业务应用层;其中:
4、所述数据采集层,用于:采集业务数据及日志数据,并将采集到的数据传输给所述数据仓库;
5、所述数据仓库基于数据湖实现,用于:对所述数据采集层传输的数据进行处理分析,并将处理分析所得的数据传输给所述业务应用层;
6、所述业务应用层,用于:将所述数据仓库传输的数据提供给外部的业务系统,供所述业务系统实现对相应数据的应用。
7、优选的,所述数据采集层包括日志采集模块及业务采集模块,其中:
8、所述日志采集模块用于:将应用软件日志的埋点数据作为日志数据上报给消息队列,并将所述消息队列中的日志数据写入到所述数据仓库中;
9、所述业务采集模块用于:将指定数据库中的业务数据同步到所述数据仓库中。
10、优选的,所述日志采集模块具体用于:将日志数据上报给kafka消息队列,并通过flink将所述kafka消息队列中的日志数据写入到所述数据仓库中。
11、优选的,所述业务采集模块具体用于:使用flink cdc同步binlog技术,将指定数据库中的业务数据同步到所述数据仓库中。
12、优选的,所述数据仓库包括基于数据湖实现的原始数据层、明细数据层、公共维度层、汇总数据层及数据应用层;其中:
13、所述原始数据层,用于:将所述数据采集层传输的数据传输给所述明细数据层,并将其中的相应业务数据传输给所述公共维度层;
14、所述公共维度层,用于:基于所述原始数据层传输的业务数据对本地的维表数据进行更新;
15、所述明细数据层,用于:对所述原始数据层传输的数据进行预设计算,并将计算所得数据写入所述汇总数据层;
16、所述汇总数据层,用于:将所述明细数据层写入的数据及所述公共维度层的维表数据进行关联,并将关联所得数据写入所述数据应用层;
17、所述数据应用层,用于:将所述汇总数据层写入的数据同步到所述业务应用层。
18、优选的,所述原始数据层还用于:在传输数据前,对所述数据采集层传输的数据进行预设的etl处理。
19、优选的,所述原始数据层具体用于:对于所述数据采集层传输的数据,将字段为空的数据、异常值的数据清洗过滤掉,将ip字段加工成地址信息,解析出相应json字段的值。
20、优选的,所述明细数据层具体用于:对所述原始数据层传输的数据进行聚合计算,并将计算所得数据写入所述汇总数据层。
21、优选的,所述数据仓库基于的数据湖的平台包括apache hudi及apache hadoop;其中,apache hadoop用于提供数据存储计算功能,所述apache hudi用于在所述apachehadoop上提供包括更新数据、删除数据及消费变化数据的数据管理能力。
22、优选的,所述业务应用层包括报表系统、实时大屏及用户画像系统,分别用于基于所述数据仓库传输的数据更新自身报表数据、进行实时展示及进行用户画像。
23、本发明提供的一种湖仓一体架构,包括数据采集层、数据仓库及业务应用层;其中:所述数据采集层,用于采集业务数据及日志数据,并将采集到的数据传输给所述数据仓库;所述数据仓库基于数据湖实现,用于对所述数据采集层传输的数据进行处理分析,并将处理分析所得的数据传输给所述业务应用层;所述业务应用层,用于将所述数据仓库传输的数据提供给外部的业务系统,供所述业务系统实现对相应数据的应用。本发明的数据仓库对数据采集层采集的数据进行分析处理后,传输给业务应用层实现相应的数据应用,且数据仓库是基于数据湖实现的;可见,本发明利用数据湖实现对数据仓库的补充,从而使得数据仓库能够支持分钟级别的数据分析处理,有效提高数据分析处理的时效性。
技术特征:
1.一种湖仓一体架构,其特征在于,包括数据采集层、数据仓库及业务应用层;其中:
2.根据权利要求1所述的架构,其特征在于,所述数据采集层包括日志采集模块及业务采集模块,其中:
3.根据权利要求2所述的架构,其特征在于,所述日志采集模块具体用于:将日志数据上报给kafka消息队列,并通过flink将所述kafka消息队列中的日志数据写入到所述数据仓库中。
4.根据权利要求3所述的架构,其特征在于,所述业务采集模块具体用于:使用flinkcdc同步binlog技术,将指定数据库中的业务数据同步到所述数据仓库中。
5.根据权利要求4所述的架构,其特征在于,所述数据仓库包括基于数据湖实现的原始数据层、明细数据层、公共维度层、汇总数据层及数据应用层;其中:
6.根据权利要求5所述的架构,其特征在于,所述原始数据层还用于:在传输数据前,对所述数据采集层传输的数据进行预设的etl处理。
7.根据权利要求6所述的架构,其特征在于,所述原始数据层具体用于:对于所述数据采集层传输的数据,将字段为空的数据、异常值的数据清洗过滤掉,将ip字段加工成地址信息,解析出相应json字段的值。
8.根据权利要求7所述的架构,其特征在于,所述明细数据层具体用于:对所述原始数据层传输的数据进行聚合计算,并将计算所得数据写入所述汇总数据层。
9.根据权利要求8所述的架构,其特征在于,所述数据仓库基于的数据湖的平台包括apache hudi及apache hadoop;其中,apache hadoop用于提供数据存储计算功能,所述apache hudi用于在所述apache hadoop上提供包括更新数据、删除数据及消费变化数据的数据管理能力。
10.根据权利要求9所述的架构,其特征在于,所述业务应用层包括报表系统、实时大屏及用户画像系统,分别用于基于所述数据仓库传输的数据更新自身报表数据、进行实时展示及进行用户画像。
技术总结
本发明公开了一种数据仓库领域的湖仓一体架构,包括数据采集层、数据仓库及业务应用层;其中:数据采集层,用于采集业务数据及日志数据,并将采集到的数据传输给数据仓库;数据仓库基于数据湖实现,用于对数据采集层传输的数据进行处理分析,并将处理分析所得的数据传输给业务应用层;业务应用层,用于将数据仓库传输的数据提供给外部的业务系统,供业务系统实现对相应数据的应用。本发明的数据仓库对数据采集层采集的数据进行分析处理后,传输给业务应用层实现相应的数据应用,且数据仓库是基于数据湖实现的;可见,本发明利用数据湖实现对数据仓库的补充,从而使得数据仓库能够支持分钟级别的数据分析处理,有效提高数据分析处理的时效性。
技术研发人员:陈帅
受保护的技术使用者:上海二三四五网络科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!