一种自适应的隐私保护联邦学习方法
本发明涉及联邦学习(federated learning)安全领域和数据隐私领域,具体涉及一种自适应的隐私保护联邦学习方法。
背景技术:
1、联邦学习是一种分散式机器学习技术,其中多个客户端设备共同学习一个神经网络模型而不将其本地数据发送到云服务器。与集中式机器学习相比,联邦学习显着减轻了客户的隐私问题,因为它不需要集中他们的私人数据。然而,研究人员发现联邦学习仍然面临各种数据安全和隐私问题。这是因为参与者传递的模型参数和梯度信息可能会泄露数据隐私,导致攻击者可以通过这些信息重构出客户端本地的训练数据。
2、针对上述的隐私泄露问题,联邦学习的隐私保护技术主要分为以下两类:1)基于加密的隐私保护的方法,主要使用密码技术进行隐私保护,主流的方法有同态加密和安全多方计算。该方法可以保留原始模型训练的准确性并实现高隐私保证。然而,这类方法会产生大量的通信成本和计算成本,不太适用于参与者多、数据量大的联邦学习场景。2)基于扰动的隐私保护方法,主流方法是差分隐私技术(dp)。差分隐私技术通过在梯度信息上添加可度量的噪声来扰动梯度,从而防止真实梯度泄露带来的隐私攻击。虽然差分隐私技术由于其高效轻量的特点更适合联邦学习场景,现有基于差分隐私技术的联邦学习方法无法有效地权衡模型的隐私性和准确率,特别是在需要高可用性的模型情况下,数据的隐私保护得不到充分的保障。
3、因此,针对现有技术所存在的问题,当下迫切需要研究如何使用差分隐私技术实现高效、轻量、灵活的自适应的隐私保护联邦学习方法,以满足国家对数据安全保护的需求。
技术实现思路
1、本发明针对现有技术的不足之处作出了改进,提供了一种自适应的隐私保护联邦学习方法,既可以保证模型联合训练精度的同时能够抵御梯度攻击使其无法恢复出客户端的训练数据,本发明是通过以下技术方案来实现的:
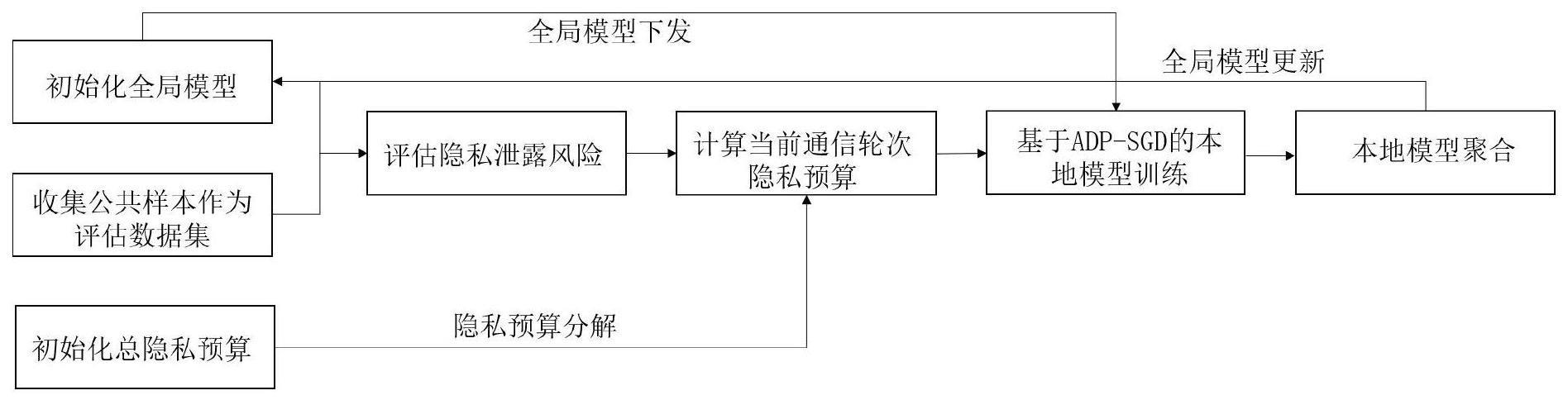
2、本发明公开了一种自适应的隐私保护联邦学习方法,包含如下步骤:
3、1):初始化阶段;
4、1.1)收集与联邦学习任务相关的公共样本作为评估数据集;
5、1.2)初始化全局模型;
6、1.3)初始化总的隐私预算(差分隐私机制中隐私强度的度量指标);
7、2):根据评估数据集和全局模型评估当前通信轮次的隐私泄露风险;
8、3):根据评估的隐私泄露风险对总的隐私预算进行分解,得到当前通信轮次的隐私预算;
9、4):根据隐私预算和当前全局模型,采用自适应的差分隐私随机梯度下降法(adp-sgd)开展本地模型训练得到新的本地模型;
10、4.1)将分配预算转化为零均值集中差分隐私(zcdp)范式并用全局模型初始化本地模型;
11、4.2)根据隐私预算和当前模型训练周期计算当前模型训练周期使用的噪声等级;
12、4.3)根据噪声等级更新剩余的隐私预算;
13、4.4)根据当前模型迭代周期计算当前模型迭代周期使用的梯度裁剪系数;
14、4.5)根据反向传播计算当前模型迭代周期的梯度;
15、4.6)根据梯度裁剪系数对当前模型迭代周期生成的梯度进行裁剪;
16、4.7)根据噪声等级和梯度裁剪系数计算噪声扰动参数,并在裁剪后的梯度上按噪声扰动参数添加高斯噪声得到扰动后梯度;
17、4.8)根据扰动后的梯度按梯度下降发更新本地模型(初始值为全局模型);
18、迭代4.2)到4.8)直到4.3)计算的剩余隐私预算小于0或模型训练周期结束;
19、5)本地模型聚合得到新的全局模型:
20、循环执行步骤2)到5),直至全局模型收敛(模型准备率不再提升或者提升范围小于阈值10^-4),联邦学习模型训练停止。
21、作为进一步地改进,本发明所述的评估当前通信轮次的隐私泄露风险具体为:服务器使用收集到的评估数据集来测试当前全局模型的准确率,并用其作为隐私泄露风险指示器来表征当前通信轮次的隐私泄露风险,考虑到全局模型的准确率会出现一定范围的小波动,为降低波动对隐私泄露风险评估的影响,若st表示t通信轮次的全局模型的准确率,模型准确率增值表示为:
22、
23、当训练刚起步阶段,缺乏有效的全局模型准确率数据,和取值为1。
24、作为进一步地改进,本发明所述的隐私预算进行分解具体为:在完成隐私泄露风险测算后,根据当前通信轮次的隐私风险计算当前通信轮次的隐私预算∈t:
25、
26、其中∈是总隐私预算,∈c是已消耗预算,t代表预设的总通信轮次,是当前通信轮次的全局模型准确率增量,用于评估隐私泄露风险。
27、作为进一步地改进,本发明所述的所述的自适应的差分隐私随机梯度下降法(adp-sgd)具体为:每个客户端基于下发的全局模型和根据隐私泄露风险得到的隐私预算,其使用自身本地数据集开展本地模型训练;
28、在adp-sgd中,首先将分配预算∈t转化为零均值集中差分隐私(zcdp)范式,因此,∈t转化为
29、ρt=(∈t)2/(4log(1/δ))
30、其中ρt表示zcdp范式下隐私预算,(∈t,δ)是dp范式下的隐私参数,对每个训练周期(epoch),首先更新当前剩余的隐私预算ρleft,并且决定当前周期的噪声等级(消耗一定的隐私预算),为提升收敛性,噪声等级应该随着训练周期衰减,因此每个训练周期的噪声等级σe为
31、
32、其中ρt是当前通信轮次分配给用户的隐私预算,β用来控制初始的噪声等级,kσ是噪声等级衰减率,e为预设的训练周期(训练周期结束,本地训练停止),e是当前训练周期,决定每个本地训练周期的噪声等级后,隐私预算剩余
33、
34、其中ρleft的初始值设为ρt,为了确保隐私预算不超过分配的ρt,隐私预算耗尽(ρleft≤0),停止训练;
35、在每个模型迭代周期τ(iteration),从客户端数据集中通过随机重组的方法选取一批样本b,对批次内样本(xk,yk)∈b,利用反向传播计算样本梯度,之后对梯度进行裁剪,
36、
37、其中l表示损失函数,f表示训练模型,w是模型参数,g(xk)和分别表示原始梯度和裁剪后梯度,cτ代表裁剪系数,如果梯度的l2范数||g(xk)||2大于裁剪值cτ,裁剪后梯度的l2范数为cτ,反之,梯度保持不变;
38、考虑到梯度值会随着训练变小,本方法动态衰减裁剪系数cτ:
39、cτ=c0exp(kcτ)
40、其中c0是裁剪系数初值,一般取批量梯度l2范数值的均值或中位数,kc为裁剪系数衰减率;
41、完成梯度裁剪之后,使用噪声扰动后梯度更新模型参数,噪声服从高斯分布
42、
43、模型更新之后,进入下一次模型迭代周期(τ+1),当本地数据集遍历完,一次本地训练完成,训练到下一个训练周期(e+1),当所有训练周期结束(e=e)或隐私预算耗尽,本地训练结束,将本地模型上传到服务器。
44、作为进一步地改进,本发明所述的所述的本地模型聚合具体为:步骤5)服务器对上传的本地模型进行模型聚合,得到新一轮的全局模型,比如采用的是平均聚合方法,新的全局模型更新如下:
45、
46、其中dk代表客户端k的本地数据集,代表客户端k本轮上传的本地模型。
47、本发明的优点在于:
48、本发明提出了一种自适应的隐私保护联邦学习方法,该方法完成联邦学习模型训练,为不同的通信轮次提供自适应的隐私保护,保证生成模型高可用的同时抵御梯度攻击,保护客户端训练数据安全。针对基于加密的隐私保护的联邦学习方法产生大量的通信成本和计算成本的问题,本发明采用在客户端进行梯度扰动的方法保护梯度隐私安全,在原联邦学习方法上零增加多余的通信成本,且梯度扰动的噪声生成计算成本远远低于加解密计算。针对现有基于差分隐私技术的联邦学习无法权衡模型的隐私性和准确率的问题,本发明揭示了梯度攻击具有通信轮次异构特点,从而提出泄露风险感知的隐私分解方案。该方案量化当前通信轮次共享参数的隐私泄露风险并自适应分配隐私预算,从而平衡不同通信轮次的数据隐私性与模型可用性。此外,在客户端训练阶段,本发明提出自适应的差分隐私随机梯度下降法,动态衰减噪声和裁剪系数,有效缓解差分隐私机制对模型训练造成的负面效应,提升模型准确性和收敛性。本发明具有模型高可用、计算轻量级、隐私可度量的特点,因此在联邦学习领域有较高实用价值。其高效、轻量、灵活的自适应数据隐私保护方法,满足国家数据分级保护的要求,对于联邦学习应用和推广具有重要的理论意义和应用价值。
- 还没有人留言评论。精彩留言会获得点赞!