一种先验的语义图像转变成图片的方法
本发明涉及计算机图像转换领域,具体为一种先验的语义图像转变成图片的方法。
背景技术:
1、在计算机图像领域,对抗神经网络(generative adversarial networks,简称gan)经过训练,不仅能够生成很多之前并不存在的图片,例如:我们可以通过训练生成器和辨别器,生成和训练数据同类的但是不同样的真实图片。而且还可以实现不同域的图像相互转换,例如:实现把不同风格的图片进行转换、面部表情修改,并且都展现出不错的性能。
2、如果可以从semantic label maps(语义图像)的条件下生成出高分辨率的图片,那么就可以为一些视觉识别算法生成训练数据,因为为所需场景创建语义标签要比生成训练图像容易得多。然而,最早做不同域图像转换的工作,因为损失函数的选择不够恰当,导致生成的图片比较模糊。其次,因为一套生成器和辨别器的组合并不能达到好的实验结果,所以导致很多人都想着去在最原始的模型外去嵌套多尺度的生成器和判别器。最后,对抗性训练可以实现高分辨率的图像的生成,但是在高分辨率图像生成任务中可能是不稳定的,并且容易失败。也有人采用改进的感知损失来合成图像,这些图像具有高分辨率,但往往缺乏精细的细节和逼真的纹理。在传统的gan模型对生成图片中的实例编辑这一点做的并不是特别的好,在语义图像转换成真实图片的这个领域,如果能够对生成的图片进行实例编辑,那么理论上来说,我们可以通过我们训练的模型生成无数张训练数据。尽管由于对抗生成网络(gan)的后续改进工作能够稍微的减少上述问题带来的影响,但是对抗生成网络面临着几个非常严峻的问题:生成器和判别器如果初始参数设置不好的话很容易出现梯度消失的问题。对抗生成网络被定义为极小极大问题,没有损失函数,在训练过程中很难区分是否正在取得进展。网络的学习过程可能发生崩溃问题(collapse problem),生成器开始退化,总是生成同样的样本点,无法继续学习。当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,训练无法继续。
3、因此,如何简单有效的转换生成高分辨率的、纹理清晰的图片,并且实现对生成图片中的某一个实例对象进行编辑。这成为了本技术需要解决的一个重点问题。
技术实现思路
1、本发明的目的在于克服现有的缺陷而提供的一种先验的语义图像转变成图片的方法,简单有效的将语义图像转换生成高分辨率的、纹理清晰的图片,并且实现对生成图片中的某一个实例对象进行编辑。
2、实现上述目的的技术方案是:
3、一种先验的语义图像转变成图片的方法,包括:
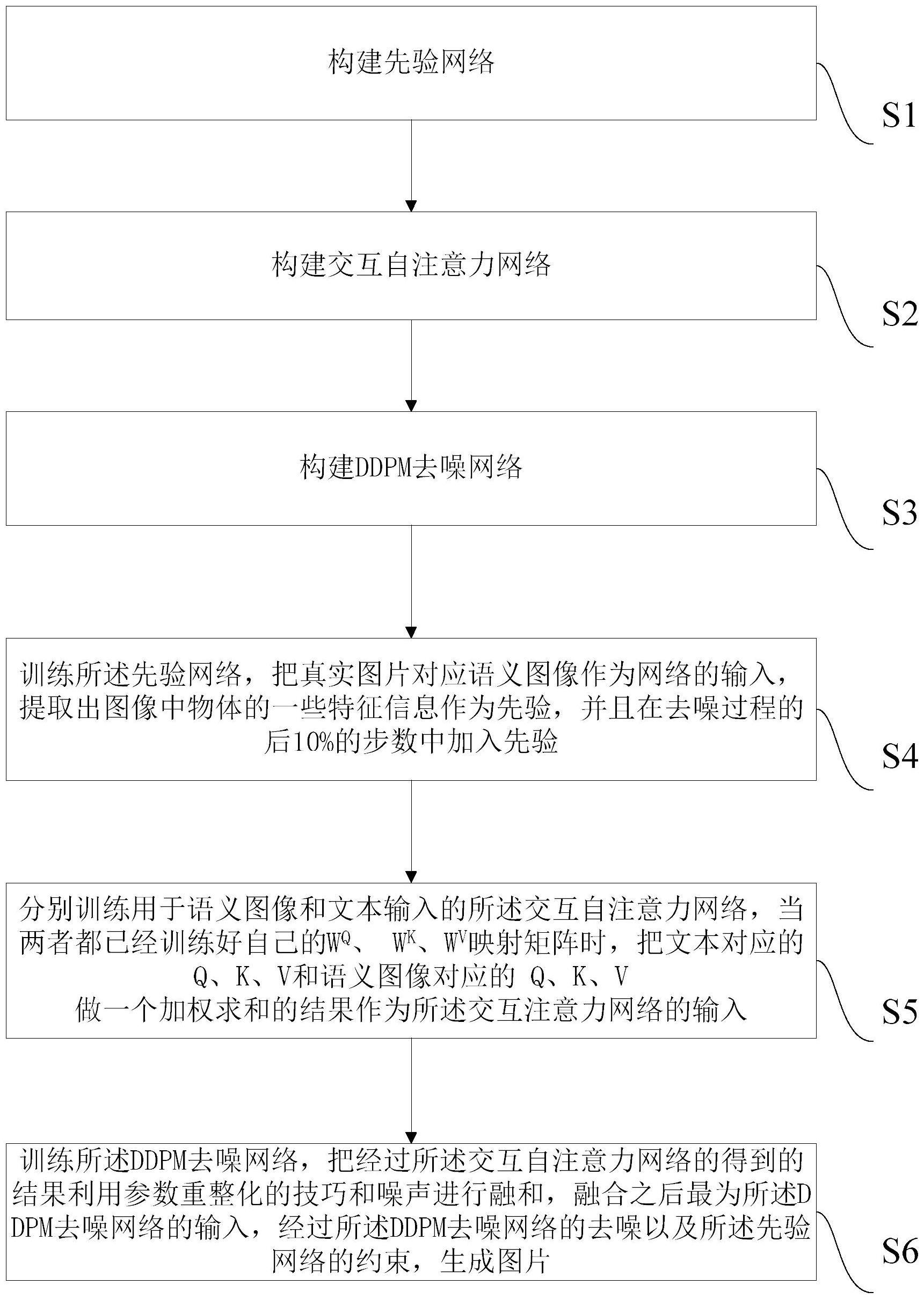
4、步骤s1,构建先验网络;
5、步骤s2,构建交互自注意力网络;
6、步骤s3,构建ddpm(概率扩散模型)去噪网络;
7、步骤s4,训练所述先验网络,把真实图片对应语义图像作为网络的输入,提取出图像中物体的一些特征信息作为先验,并且在去噪过程的后10%的步数中加入先验;
8、步骤s5,分别训练用于语义图像和文本输入的所述交互自注意力网络,当两者都已经训练好自己的wq、wk、wv映射矩阵时,把文本对应的q、k、v和语义图像对应的q、k、v做一个加权求和的结果作为所述交互注意力网络的输入;
9、步骤s6,训练所述ddpm去噪网络,把经过所述交互自注意力网络的得到的结果利用参数重整化的技巧和噪声进行融和,融合之后最为所述ddpm去噪网络的输入,经过所述ddpm去噪网络的去噪以及所述先验网络的约束,生成图片。
10、优选的,所述先验网络由多个卷积层和线性层以及一个batchnorm归一化层组合而成,当加入先验网络的t正好等于0.9*t时,所述先验网络的两个输入均为语义图像,之后的所述先验网络输入为语义图像本身和上一层的激活。
11、优选的,所述先验网络中,将语义图像过第一层卷积,得到的结果会经过两个linear线性层进而得到每个通道c的均值μ和方差σ;同时,通过第一个卷积层得到的结果分为两路,并且分别通过第二层卷积,分别计算得到γ参数和β参数,所产生的γ和β相乘、相加到归一化活化元素中,式子如下所示:
12、
13、其中,表示将m转换为第i个激活图中位置(c,y,x)上的缩放和偏置值的函数,使用一个简单的两层卷积网络实现,表示归一化前的激活,和表示通道c中激活量的平均值和标准差。
14、优选的,根据更改的所述交互自注意力网络的编码器实现文本和语义图像之间信息的交互,将参数重整化把得到的结果和高斯噪声相结合作为所述ddpm去噪网络的输入。
15、优选的,所述步骤s5中,所述交互自注意力网络的操作结束后,再经过一个多层感知机得到信息交互之后得到的结果。
16、优选的,所述步骤s6中,选择预测噪声的均值,式子如下所示:
17、
18、其中,σt表示t时刻的方差,表示关系均值的表达式,μθ(xt,t)表示用来拟合真实均值的神经网络;
19、也可选择预测噪声,式子如下所示:
20、
21、其中,σt表示t时刻的方差,αt=1-βt,βt为t时刻加的噪声的方差,表示x0表示原图,∈表示随机的高斯噪声,∈θ表示用来拟合真实噪声的神经网络,t表示t时刻;
22、上式的系数都是固定的,将系数去掉,使得训练过程中收敛的更加稳定,更加平滑,得到如下式子:
23、
24、将预测噪声的式子记为lsimple。
25、优选的,通过u-net预测噪声,u-net(卷积神经网络)的下采样的进行,感受野一步步扩大,图片被压缩,单位面积感知的区域变大,感知到更多的图片的低频信息,通过u-net上采样进行恢复,在上采样的同时,网络架构进行了skip connection(跳跃式传递),将各个层次的信息保留,使得整个所述ddpm去噪网络可以很好的记住图片的所有信息,进而生成图片。
26、优选的,对于生成的图片转换成语义图像,计算生成真实图片的语义图像和原始图片对应的语义图像之间的相似程度,通过mse(均方误差)指标衡量,式子如下:
27、
28、其中,m为图像i的像素总数,n为图像k的像素总数,mse值越小,图像越相似。
29、本发明的有益效果是:本发明把真实图片对应语义图像作为网络的输入,提取出图像中物体的一些特征信息作为先验,在去噪过程的后10%的步数中加入先验;让先验模型的输出和生成过程中的图片一起作为u-net网络的输入,更好的生成图像中的一些实例的形状,使生成的图片更加真实;本发明还把输入图像和编辑图像的文本作为做了一个自注意力的交互,那么图片中的每一个特征,就会和其他的特征进行交互,实现了对生成图片进行实例编辑。
技术特征:
1.一种先验的语义图像转变成图片的方法,其特征在于,包括:
2.根据权利要求1所述的一种先验的语义图像转变成图片的方法,其特征在于,所述先验网络由多个卷积层和线性层以及一个batchnorm归一化层组合而成,当加入先验网络的t正好等于0.9*t时,所述先验网络的两个输入均为语义图像,之后的所述先验网络输入为语义图像本身和上一层的激活。
3.根据权利要求2所述的一种先验的语义图像转变成图片的方法,其特征在于,所述先验网络中,将语义图像过第一层卷积,得到的结果会经过两个linear线性层进而得到每个通道c的均值μ和方差σ;同时,通过第一个卷积层得到的结果分为两路,并且分别通过第二层卷积,分别计算得到γ参数和β参数,所产生的γ和β相乘、相加到归一化活化元素中,式子如下所示:
4.根据权利要求1所述的一种先验的语义图像转变成图片的方法,其特征在于,根据更改的所述交互自注意力网络的编码器实现文本和语义图像之间信息的交互,将参数重整化把得到的结果和高斯噪声相结合作为所述ddpm去噪网络的输入。
5.根据权利要求1述的一种先验的语义图像转变成图片的方法,其特征在于,所述步骤s5中,所述交互自注意力网络的操作结束后,再经过一个多层感知机得到信息交互之后得到的结果。
6.根据权利要求1述的一种先验的语义图像转变成图片的方法,其特征在于,所述步骤s6中,选择预测噪声的均值,式子如下所示:
7.根据权利要求6述的一种先验的语义图像转变成图片的方法,其特征在于,通过u-net预测噪声,u-net的下采样的进行,感受野一步步扩大,图片被压缩,单位面积感知的区域变大,感知到更多的图片的低频信息,通过u-net上采样进行恢复,在上采样的同时,网络架构进行了skip connection,将各个层次的信息保留,使得整个所述ddpm去噪网络可以很好的记住图片的所有信息,进而生成图片。
8.根据权利要求6述的一种先验的语义图像转变成图片的方法,其特征在于,对于生成的图片转换成语义图像,计算生成真实图片的语义图像和原始图片对应的语义图像之间的相似程度,通过mse指标衡量,式子如下:
技术总结
本发明公开了一种先验的语义图像转变成图片的方法,包括:步骤S1,构建先验网络;步骤S2,构建交互自注意力网络;步骤S3,构建DDPM去噪网络;步骤S4,训练先验网络,把真实图片对应语义图像作为输入,提取出图像中物体的特征信息作为先验,并在去噪过程的后10%的步数中加入先验;步骤S5,训练用于语义图像和文本输入的交互自注意力网络,把文本对应的Q、K、V和语义图像对应的Q、K、V做一个加权求和的结果作为交互注意力网络的输入;步骤S6,训练DDPM去噪网络,经过DDPM去噪网络的去噪以及先验网络的约束,生成图片。本发明可以简单有效的将语义图像转换生成高分辨率的、纹理清晰的图片,并且实现对生成图片中的某一个实例对象进行编辑。
技术研发人员:林灵鑫,康嘉文,肖明,杨学贤,陈奕林,侯子豪,王钧亮,张奕棋,曹海文
受保护的技术使用者:广东工业大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!