一种基于集成最大熵深度逆强化学习的无人驾驶奖励学习和控制方法
本发明涉及人工智能和强化学习,尤其涉及一种基于集成最大熵深度逆强化学习的高速路无人驾驶的奖励学习和控制方法。
背景技术:
1、近年来,随着高性能计算、大数据和深度学习技术的快速发展,alphago、alphagozero等人工智能软件核心技术的强化学习算法及其应用得到了更广泛的关注和更快的发展。该算法在游戏、机械臂、机器人、无人驾驶等领域得到了较为广泛的应用。在与环境的交互过程中,强化学习算法学习最优策略以最大化收益或实现特定目标。强化学习把学习看作试探-评价过程,智能体选择一个动作作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号反馈给智能体,智能体根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化的概率增大。因此奖励函数的设计成为制约强化学习发展的瓶颈问题。
2、人工设计奖励函数受到诸多问题的影响。例如无人驾驶需要考虑的因素很多,因此奖励函数需要考虑限速奖励、撞击奖励、开上人行道奖励、越线奖励、舒适驾驶奖励、停止奖励等,设计较难。因此研究者提出逆强化学习算法,逆强化学习算法消除了手工设计成本函数所需的专业知识和努力,可以生成更符合人类行为的奖励函数;然后进行任务决策。首先研究者提出专家克隆和模仿学习逆强化学习算法,但这两种算法只能完全模仿具有有限行为观察的专家行为。因此学徒学习和最大边际逆强化学习等边际类逆强化学习算法被提出,通过学习使学习者的特征期望尽可能接近专家的特征期望。但该类算法存在模糊问题,即多个策略对应一个奖励函数。因此基于最大熵的深度逆强化学习算法得到广泛的发展,该方法的核心思想是通过减小学习者期望的状态访问频率与期望的经验状态访问频率之间的差异来提高奖励函数的学习精度。
3、但在最大熵深度逆强化学习算法中,非最优、有限和不平衡的专家演示数据影响着奖励函数的学习,且最大熵深度逆强化学习算法存在过拟合等问题,这都限制了奖励函数的学习性能。本发明在最大熵深度逆强化学习算法的框架下,发明了一种在高速路无人驾驶环境下用于奖励函数融合的基于软q-learning和集成算法的最大熵深度逆强化学习方法。解决了非最优、有限、不平衡的专家演示问题,以及过拟合问题,提高了奖励函数的学习精度,更好的实现强化学习的决策控制。
技术实现思路
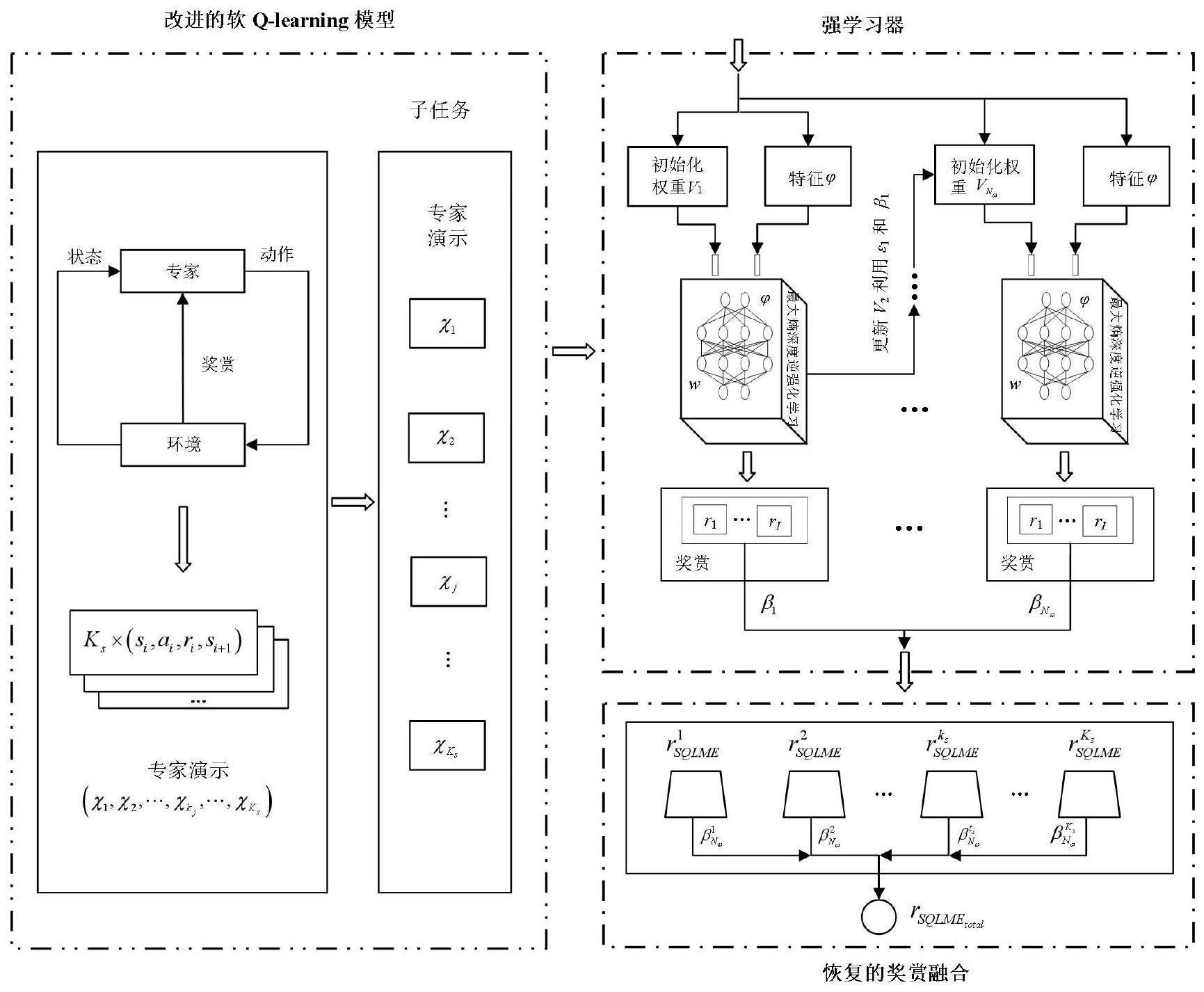
1、针对高速路无人驾驶环境中非最优、有限的、不平衡的专家演示,本发明提出了一种基于值裁剪和缩放指数线性单元激活函数的改进的软q-learning算法,平衡探索与利用问题,解决梯度爆炸和梯度消失问题以及数据溢出问题。从而获得更好的、更优的无人驾驶车的专家演示。
2、在高速路无人驾驶环境中,针对传统最大熵深度逆强化学习算法存在的奖励函数学习效率低和过拟合问题,本发明提出了集成最大熵深度逆强化学习方法,根据专家偏好将奖励函数的学习任务解耦为多个子任务,然后利用集成算法将每个最大熵深度弱学习器集合成强学习器,学习每个子任务的奖励函数。为防止强学习器过拟合问题,发明了在这些弱学习器的线性组合中加入一个常数正则化。
3、针对集成最大熵深度逆强学习中的复杂计算的问题,本发明提出了一种利用截断梯度方法对强学习器获得的奖励进行稀疏化处理的方法,从而降低模型的复杂性。
4、针对集成最大熵深度逆强学习中的过拟合问题,本发明提出了一种线性组合方法,将高速路无人驾驶各子任务学习的奖励函数融合成整体的奖励函数。
5、针对上述技术问题,本发明提供了一种基于集成最大熵深度逆强化学习的无人驾驶的奖励学习和控制方法,能够在逆强化学习的应用实验中,学习较优的专家演示,克服非最优、有限、不平衡的无人驾驶车的专家演示问题。同时根据专家偏好将复杂的奖励函数的学习任务解耦为多个子任务,利用集成学习将深度最大熵弱学习器集成为强学习器,然后将无人驾驶中各子任务的奖励函数通过线性组合为最终的奖励函数,提高奖励函数的学习效率,获得更好的驾驶决策性能。
6、为了实现上述高速路无人驾驶的目的,本发明提供如下技术方案:
7、本发明首先提供一种基于集成最大熵深度逆强化学习的无人驾驶奖励学习和控制方法,包括以下四个步骤:
8、步骤一:在高速路无人驾驶的逆强化学习应用场景下构建一个基于马尔科夫决策过程模型,将高速路无人驾驶环境转换为求解一个马尔科夫决策过程;
9、步骤二:为求解步骤一构建的马尔科夫决策过程,首先构建基于值裁剪和缩放指数线性单元激活函数的改进的软q-learning学习模型来获取专家演示,并根据专家偏好将逆强化学习任务解耦为各子任务;
10、步骤三:在步骤二获得的各子任务的专家演示下,建立强学习器集成模型,通过最大熵深度逆强化学习求解各子任务的奖励函数,利用集成算法将深度最大熵弱学习器集合成强学习器;
11、步骤四:通过线性组合方法将步骤三中学习获得的无人驾驶环境下的各子任务奖励函数进行融合,从而提高无人驾驶奖励函数的学习精度。
12、具体为:
13、在步骤一中,高速路无人驾驶的强化学习问题被建模为一个由五元组的马尔科夫决策过程其中s表示无人驾驶车的状态空间,si∈s;a表示无人驾驶车的动作空间,ai∈a;表示无人驾驶车的转移概率;r表示无人驾驶车的奖励函数;γ表示折扣因子。基于强化学习模型的定义,高速路无人驾驶的逆强化学习问题被建模为四元组高速路无人驾驶环境由三车道高速公路、红色主车v0和环境车{v1,v2,v3,v4,v5}组成。在高速路无人车驾驶系统中,需要满足三个条件。1)红色车辆比其他环境车辆快,2)不同车辆的司机不互相交流,3)而且不同车辆之间不共享数据。红色主车的合作过程描述如下:首先,高速路上红色主机车在目前的状态si下采取一个行动π(si)。其次,高速路环境中的车观察红色主车的行动,并根据策略采取行动。最后,红色主机车通过新位置和v0前后的环境中的车得到下一状态si+1。
14、在步骤二中,将熵项增加到传统的软q-learning算法中获得求解高速路无人驾驶的奖励函数的最优化目标函数π*,
15、
16、其中r(si,ai)表示无人驾驶车的奖励函数,ρπ表示无人驾驶车的轨迹分布的状态-动作边缘。熵项通过进行计算,表示无人驾驶车的策略π(·|si)在概率分布上的随机性。σ表示控制熵项重要性的温度因子,即控制无人驾驶车的所选择动作的随机性。熵越大,无人驾驶车所选择的策略的随机性越大。
17、高速路无人驾驶的逆强化学习算法中的软q函数和软值函数定义为,
18、
19、
20、其中折扣因子γ表示未来奖励对当前时刻奖励的影响,即γ越大,无人驾驶车往前考虑的步数l越多,但训练难度也越高。
21、通过重要性采样,无人驾驶车的软q函数的软贝尔曼误差可以用一个等价的形式表示为最小化,
22、
23、其中ds表示无人驾驶车状态空间的分布,da表示无人驾驶车动作空间的分布,表示无人驾驶车的目标q值,表示无人驾驶车的目标参数。
24、利用神经网络的激活函数缩放指数线性单元激活函数,选择右半轴的斜率λ1为1.05解决梯度爆炸问题。
25、
26、其中λ2为1.67,表示软饱和区的斜率。
27、在高速路无人驾驶的实验过程中,改进的软q-learning算法的值函数增长非常快,存在数据溢出问题,因此发明值裁剪方法来处理软q值函数,当软值函数大于定义的阈值软q值函数被更新为否则,软q值函数保持不变。
28、
29、其中表示经值裁剪后的无人驾驶的软q值函数。
30、在发明的改进的软q-learning算法中,将从高速路无人驾驶环境中获得的状态作为改进的软q-learning算法的输入,动作分布作为改进的软q-learning算法的输出。动作对应的概率越大,相应的动作被选择的可能性越大。在改进的软q-learning算法的迭代学习过程中,将通过学习得到的状态-动作对和奖励函数存储在缓冲器中。然后经过采样,获得逆强化学习算法的专家演示。根据专家偏好,将无人驾驶车复杂的奖励函数学习任务解耦为多个子任务,进行奖励函数的学习。在每一个专家演示的子任务下,学习无人驾驶车的奖励函数和最优策略。
31、在步骤三中,基于利用改进的软q-learning算法学习到的无人驾驶车的专家演示,强学习器集成模型的建立方法为:弱学习器通常是指泛化性能仅略优于随机猜测的学习器。在高速路无人驾驶环境下集成的最大熵深度逆强化学习框架中,通过子任务下的专家演示,将每个最大熵深度逆强化学习过程视为一个弱学习器,输入状态特征并输出奖励。最佳网络参数w通过公式(7)计算,
32、
33、其中表示专家演示中专家演示轨迹的个数,表示配分函数,p(si+1|si,ai)表示无人驾驶车状态转移概率,表示无人驾驶车状态si的特征函数,j为无人驾驶车学习奖励函数的子任务的个数。
34、根据链式法则,公式(7)中数据项对网络参数标量w的完全导数由两部分组成:一个是数据项对奖励函数r(w)的导数,另一个是奖励函数r(w)对参数w的导数。
35、
36、其中表示在最大熵深度逆强化学习中深度神经网络梯度反向传播的效率,表示无人驾驶车的专家演示中期望的经验状态访问计数,表示在专家演示下,无人驾驶车学习获得的期望的状态访问计数。如果奖励函数是正的,则c被设置为0.01;否则c被设置为-0.01。
37、在专家演示下,最大熵深度逆强化学习算法被用来学习无人驾驶车的奖励函数这被当作弱学习器。弱学习器的输入为特征函数和权重,输出为奖励函数。
38、
39、其中w表示无人驾驶车的奖励函数权重,表示无人驾驶车的特征函数,表示无人驾驶车的专家演示轨迹。
40、在高速路无人驾驶弱学习器的学习过程中,集成算法执行以下操作:
41、步骤1:在无人驾驶车的集成最大熵深度逆强化学习方法模型中,首先通过集成最大熵深度逆强化学习方法学习到的奖励函数的权重分布初始化为:v1=(w1,1,w1,2,…,w1,i),i=1,2,…,i。
42、步骤2:利用具有当前分布的无人驾驶车的专家演示训练数据学习弱学习器计算得到弱学习器的学习误差率,
43、
44、其中表示无人驾驶车学习者期望的状态访问频率,表示无人驾驶车期望的经验状态访问频率。
45、步骤3:弱学习器的系数计算如下:
46、
47、步骤3:更新无人驾驶车的奖励函数的权重,为下一个弱学习器做准备,
48、
49、其中α被设置为0.01,表示归一化因子。利用集成学习的方法提高了无人驾驶车学习错误的专家演示的数据的权重,降低了学习正确的专家演示的数据的权重。
50、在高速路无人驾驶复杂的非线性环境下,采用最大熵深度逆学习奖励的过程中存在计算复杂和过拟合的问题,影响了奖励的学习精度。为了防止这些问题,在发明的最大熵深度逆学习中考虑了梯度截断方法和修正因子。
51、最大熵深度逆强化学习的弱学习器的奖励可以计算如下,
52、
53、其中为重力参数,越大,表示梯度截断方法的稀疏性越大。且为梯度截断方法的阈值,ζ为梯度截断方法的重力参数的系数。
54、梯度截断方法的指示函数tg计算如下,
55、
56、在训练过程中,adaboost算法会使学习奖励性能较差的权值呈指数增长。因此,下一个弱学习器会偏向于学习这些权重增加的奖励,导致这些弱学习器容易受到噪声干扰。为了防止这个问题,在弱学习器的线性组合中加入修正因子ν,构成弱学习者的系数。
57、此外,集成算法通过线性加权投票将多个弱学习器构建成一个强学习器,从而求解子任务的奖励函数,
58、
59、其中系数表示弱学习器的重要性,v表示常数正则化。
60、在步骤四中,线性组合实现无人驾驶环境中各子任务奖励函数的融合的建立方法为:针对多个子任务,利用强学习器学习得到的奖励函数通过线性组合方法融合成为最终的奖励函数,提高了奖励函数的学习精度,获得更优的决策性能。
61、
62、其中表示在第ks个子任务中强学习器的系数与现有技术相比较,本发明具有如下技术优势。
63、1)在高速路无人驾驶环境中,与传统的最大熵深度逆强化学习相比,本发明不仅考虑了非最优、有限、不平衡的无人驾驶车的专家演示问题,同时考虑了软q-learning算法中的梯度爆炸、梯度消失以及数据溢出问题,发明了基于值裁剪和缩放指数线性单元激活函数的改进的软q-learning学习专家演示,获得更优的无人驾驶车的专家演示。
64、2)基于利用改进的软q-learning学习获得的无人驾驶车的专家演示,集成最大熵深度逆强化学习算法,梯度截断和弱学习器集成的过程中的常数正则化的引入提高无人驾驶车的奖励函数的学习率、解决了复杂计算和过拟合问题,实验结果表明与其他算法相比本发明有效提高奖励函数的学习性能,更好地实现无人驾驶的决策控制。
- 还没有人留言评论。精彩留言会获得点赞!