基于解耦与重构学习的SAR真假目标鉴别与目标识别方法
本发明属于sar遥感图像处理,特别是一种基于解耦与重构学习的高分辨率sar真假目标鉴别与目标识别方法。
背景技术:
1、合成孔径雷达(sar,synthetic aperture radar)是一种主动式的微波成像雷达,通过脉冲压缩与合成孔径来获得高分辨率的sar图像,该雷达具有全天时全天候的工作,对植被具有一定穿透性的特性,在军民领域具有巨大的应用价值。随着sar系统技术的发展,成像模式逐渐丰富,一个sar平台可能具备多个接收天线,平台姿态变化、传感器通道间幅相不平衡等误差,可能带来多通道效应进而导致虚假目标的出现。这种虚假目标在图像中相较于真实目标在亮度上存在一定的衰减,但是几何形态和真实目标较为相似,导致真假目标区分困难。这种虚假目标的存在会对sar对地观测、目标检测识别造成巨大的挑战。因此,研究真假目标鉴别与目标识别对提高sar遥感的应用性能具有重要意义。
2、针对sar图像真假目标鉴别与目标识别的重要应用,现有的方法主要通过对真假目标进行特征提取然后构建多任务分类器,实现端到端的模型优化,实现真假目标鉴别和目标识别。这类方法忽视了虚假关联特征与目标类别关联特征的耦合作用,导致模型只能学习到虚假的数据关联性,导致特征表示能力不足,进而在实际应用中容易造成性能崩塌,难以满足高精度的目标识别应用需求。因此,现有的针对真假目标鉴别与目标识别的技术还有待改进与发展。
技术实现思路
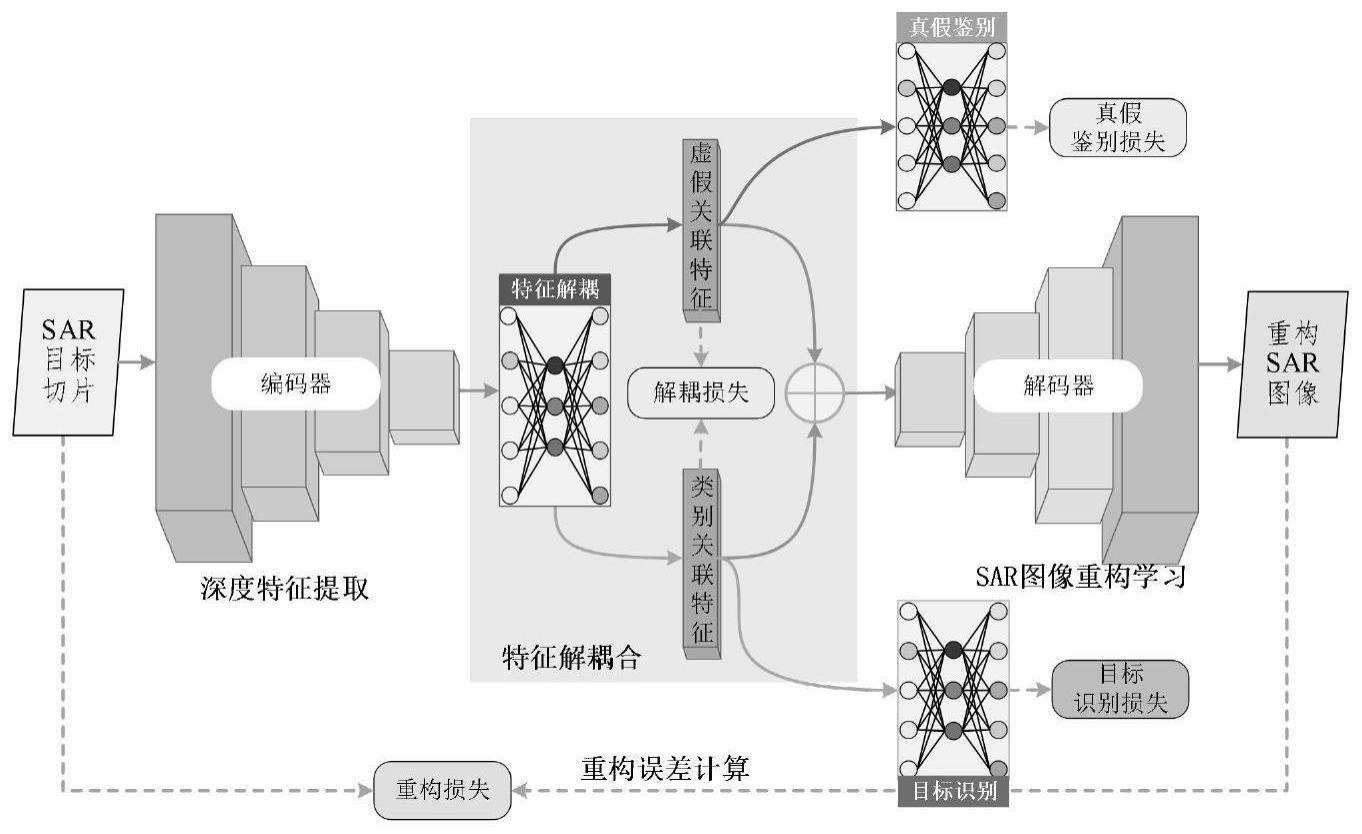
1、本发明主要针对真假目标鉴别与目标识别困难的问题,构建了一种基于解耦与重构学习的sar真假目标鉴别与目标识别方法,实现虚假关联特征与目标类别关联特征解耦合,进而实现高精度的真假目标鉴别与目标识别。
2、本发明是通过以下技术方案实现的:
3、基于解耦与重构学习的sar真假目标鉴别与目标识别方法,所述方法包括以下步骤:
4、步骤一:准备真假sar目标切片数据集,利用高分辨率的sar数据作为真实目标模板,使用仿真生成该模板对应的虚假目标图像,虚假目标标签为1,真实目标标签为0;
5、步骤二:数据集划分与预处理,根据准备好的真假sar图像数据集,按照一定的比例对每个类别的真假目标样本分别划分训练集与测试集,真假目标图像划分训练集与测试集的比例相同,将所有图像切片中心剪裁为相同大小,并使用统一的格式进行储存;
6、步骤三:构建卷积自编码器模型,该模型主体结构包含编码器和解码器结构,其中编码器结构用于目标的潜在特征提取,而解码器结构通过将潜在特征重建为原始图像,以保证提取的特征具有信息完整性;
7、步骤四:基于构建的卷积自编码器模型,构建解耦与重构学习模型,为了分别提取虚假关联特征与类别关联特征,在特征独立性与信息完整性准则下,构建真假目标鉴别损失,目标识别损失,解耦损失与重构损失,使用训练数据联合优化这四类损失函数实现解耦与重构学习,进而训练得到最优的模型权重;
8、步骤五:利用训练好的模型权重实现真假目标鉴别与目标识别,丢弃解码器结构,利用编码器结构对输入sar图像目标进行深度特征提取,进而对提取到的深度特征进行特征解耦得到虚假关联特征和类别关联特征,实现真假目标鉴别与目标识别,最后使用目标识别率和虚假目标识别率来评价性能。
9、进一步地,所述步骤一具体为:
10、第一步:准备高分辨率sar图像目标切片数据集,作为真实目标模板,对每个目标切片进行类别标注;
11、第二步:通过在真实目标图像的距离-多普勒域添加1%的二次相位误差,生成该模板对应的虚假目标图像,将假目标标签设置为1,真实目标标签设置为0。
12、进一步地,所述步骤二具体为:
13、第一步:数据集划分与预处理,根据准备好的真假sar图像数据集,按照5%,10%和20%的样本数比例对每个类别的真假目标样本分别划分训练集,每类真假目标图像划分训练集的比例相同,剩余的样本作为测试集;
14、第二步:将所有图像切片中心剪裁、缩放为128×128大小,并使用统一的文件格式进行储存。
15、进一步地,所述步骤三具体为:
16、第一步:构建卷积自编码器的编码器:编码器fe由5个卷积层、1个残差模块和1个全连接层组成,经过5次降采样操作扩大感受野,每个卷积层由卷积操作,实例归一化层和relu激活函数组成;残差模块由两个卷积层和残差连接组成;编码器输入通道数为3,每个卷积层的输出通道数分别为64,128,256,256和256,残差模块输入与输出通道数均为256;为了减少计算量,使用全连接层对编码器输出的特征进行降维,降维后使用relu激活函数增强特征的非线性表示能力,为了避免过拟合,全连接层后设置dropout率为0.5,训练过程中随机丢弃50%的全连接层神经元,增强全连接层的表达能力;
17、第二步:构建卷积自编码器的解码器:解码器结构与编码器结果恰恰相反,采用转置卷积(transposed convolution)代替卷积操作进行隐变量的解码,与编码器结构的组成类似,解码器结构由5个转置卷积层、1个残差模块和1个全连接层组成,全连接层的作用是对隐变量进行升维,以满足后续转置卷积层计算的需求,升维后使用relu激活函数增强隐变量的非线性表示能力,为了避免过拟合,全连接层后设置dropout率为0.5,训练过程中随机丢弃50%的全连接层神经元,增强全连接层的表达能力;每个转置卷积层由转置卷积操作,实例归一化层和relu激活函数组成,残差模块与编码器结构的结构一致;对编码器的结构对应,解码器模块输入通道数为256,残差模块输入与输出通道数均为256,5个转置卷积层的输出通道数分别为256,256,128,64,3,以实现输入图像的重建。
18、进一步地,所述步骤四具体为:
19、第一步:利用卷积自编码器的编码器fe将输入图片x经过神经网络的非线性映射得到编码后的特征向量z0:
20、z0=fe(x) (1)
21、第二步:在此基础上,使用多变量独立的高斯混合模型来表征虚假关联特征zfake和类别关联特征zcls,这两类特征的每个维度均由相互独立的隐变量组成,且每个隐变量服从正态分布,利用神经网络对均值向量μ和方差向量σ2进行估计:
22、
23、其中,fμ和fσ分别表示预测均值向量μ和方差向量σ2的全连接层神经网络;进一步使用kl散度(kullback-leibler divergence)约束隐变量尽可能接近标准正态分布n(0,i),计算解耦损失:
24、ldec=kl(n(μ,σ2)||n(0,i)) (3)
25、其中,均值向量μ=[μ0,...,μd-1],标准差向量σ=[σ0,...,σd-1],由于各个变量之间相互独立,以一元正态分布的kl散度为例,可得:
26、
27、对于多变量相互独立的正态分布而言,解耦损失可计算为:
28、
29、其中,d为隐变量的个数,μi和σi分别为第i个服从正态分布n(μi,σi2)的隐变量的均值与标准差,通过重参数化方法可以得到第i个隐变量zi:
30、zi=μi+εi×σi (6)
31、其中,εi为从标准正态分布的采样值,虚假关联特征zfake和类别关联特征zcls特征均包含d/2个隐变量zi,取第0到第d/2-1维独立的隐变量zi作为虚假关联特征zfake,取第d/2到第d-1维独立的隐变量zi作为虚假关联特征zcls:
32、
33、第三步:为了保证虚假关联隐特征zfake与类别关联隐特征zcls的信息完整性,即包含了输入图片的所有信息,利用这两类特征能够重构出输入图片;具体地,将虚假关联隐特征zfake与类别关联隐特征zcls再经过解码器fd将潜在的特征表示映射回图像空间,得到重建的图片:
34、x′=fd(concat(zfake,zcls)) (8)
35、那么通过约束输入图片与重建图片之间的重构误差最小,则使得zfake和zcls包含所有的信息;该实施拟采用二范数计算重构误差,计算重构损失为:
36、lrec=(x-fd(concat(zfake,zcls)))2 (9)
37、第四步:为了确保类别关联特征包含目标识别的关键特征,虚假关联特征包含目标虚假相关的信息,使用目标识别损失与真假鉴别损失实现目标识别与真假目标鉴别有效信息的注入;目标识别损失使用交叉熵损失函数计算第i个类别预测概率与第i个类别标签的误差:
38、
39、其中,c为类别数,真假鉴别损失使用二元交叉熵函数计算虚假目标预测概率pfake与真假目标标签yfake误差:
40、lfake=-yfakelogpfake-(1-yfake)log(1-pfake) (11)
41、第五步:为了通过获得具有可分辨性的类别关联的特征表示与虚假关联的特征表示,将以上4类损失进行联合优化,总体损失函数为
42、l=lcls+lfake+λ1ldec+λ2lrec (12)
43、其中,λ1和λ2分别为平衡训练过程中ldec和lrec损失的超参数,实验中分别设置为1和0.4;训练过程中使用动量的随机梯度下降算法(sgd算法)优化式(12)的损失函数,为了保证训练过程中的稳定,加快收敛速度,使用余弦退火对学习率进行调整:
44、
45、其中,n为训练epoch数,ηt、ηmax和ηmin分别为当前,最大与最小学习率,实验中,ηmax=0.001,ηmin=0.0002,训练过程中batchsize设置为4,总共训练50个epoch。
46、进一步地,所述步骤五具体为:
47、第一步:利用训练好的模型权重实现真假目标鉴别与目标识别,丢弃解码器结构,利用编码器结构对测试集中的sar图像目标进行深度特征提取,进而对提取到的深度特征进行特征解耦得到虚假关联特征和类别关联特征,实现真假目标鉴别与目标识别;真假目标鉴别置信度阈值设定为0.5,预测置信度大于0.5则判定为假目标,否则为真实目标;
48、第二步:采用目标识别率和虚假目标识别率作为评价指标,评价指标定义如下:
49、
50、其中,ntp为正确识别的样本数,ngt为样本总数,正确识别的虚假目标数,nc为虚假样本总数。
51、本发明相对于现有技术的有益效果为:
52、1、本发明通过解耦与重构学习的方式提取sar目标虚假关联特征与类别关联特征,使得面向真假目标鉴别与目标识别的各个维度特征之间互不相关,特征分布更为稀疏,对噪声扰动更为鲁棒,进而使得模型收敛过程更快,真假目标鉴别与目标识别的精度更高。
53、2、本发明可应用于sar遥感图像处理领域,可以实现高精度的真假目标鉴别与目标识别。
- 还没有人留言评论。精彩留言会获得点赞!