一种编译器、AI网络编译方法、处理方法、执行系统与流程
本发明涉及计算机领域,具体来说,涉及一种编译器、ai网络编译方法、处理方法、执行系统。
背景技术:
1、对于用于运行ai网络的人工智能(ai)处理器,若ai处理器具有片上内存,并且ai网络能够基于ai处理器的片上内存运行,那么运行速度会很快。片上内存是处理器中的一块可以被快速访问、读写速度快的内存,相较于片外内存,具有低延迟、高带宽、低容量的特点。
2、由于片上内存的容量有限,容量非常小,因此如果期望利用片上内存的特点使得ai处理器能够高效率运行ai网络,ai网络在执行的时候所占用的内存就需要限定在片上内存的容量范围内,这就需要对ai网络进行划分,将ai网络划分为不同的子网,使得划分出来的整个子网运行所占用的内存限定在片上内存的范围内,从而提高ai网络的任务执行效率和速度。
3、但是,现有技术下,没有一个成熟的对ai网络进行合理子网划分的方案,虽然有类似于线性扫描的子网划分方案,但是线性扫描是由人工先验的方式选取较优的切分的任务节点集合,再使用贪心切分的方式逐渐切分ai网络,这种方式需要依赖大量实验迭代,需要多次实验性的运行网络来得到切分的集合,消耗资源多,尤其对于比较复杂的ai网络来说,更加不利于快速实施、运行。
技术实现思路
1、因此,本发明的目的在于克服上述现有技术的缺陷,提供一种编译器、ai网络编译方法、处理方法以及执行系统,可以在编译期就进行子网划分,并基于合理划分出的子网生成子网对应的指令,以供ai处理器执行,而无需像现有技术那样在编译完成以后需要过多依赖实验性的运行网络来得到大量实验迭代的结果,可以降低由于需要多次实验性运行网络所带来的资源开销,通过本发明的方案可以一种更高效、消耗资源更少的方式来进行子网划分,将子网运行所需数据占用的内存限定在片上内存的范围内,从而有利于ai处理器基于有限的片上内存高效执行ai网络的任务。
2、根据本发明的第一方面,提供一种编译器,所述编译器在编译待加载到ai处理器上的ai网络时,被配置为执行如下步骤对所述ai网络进行编译:
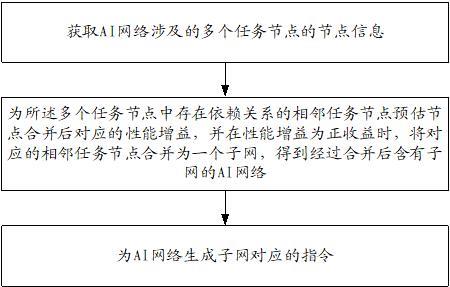
3、获取ai网络涉及的多个任务节点的节点信息,所述节点信息用于反映任务节点之间的依赖关系;
4、为所述多个任务节点中存在依赖关系的相邻任务节点预估节点合并后对应的性能增益,并在性能增益为正收益时,将对应的相邻任务节点合并为一个子网,得到经过合并后含有子网的ai网络;其中,合并后得到的任意一个子网运行一次所需的内存小于或等于所述ai处理器的片上内存;
5、为含有子网的ai网络生成子网的指令。
6、通过上述编译器可以在编译期根据片上内存的容量进行合理的子网划分,节约子网内任务节点间的数据搬运时间,且无需像现有技术那样过多依赖实验性地运行网络来得到大量实验迭代结果从而导致消耗较多的资源。
7、优选的,所述性能增益是指多个任务节点合并前的运行时钟之和,与,多个任务节点合并为一个子网后的子网运行时钟这二者的差值。
8、优选地,所述性能增益是指相邻任务节点在合并前的运行时钟之和、所述相邻任务节点合并为一个子网后的子网运行时钟这二者的差值。
9、其中,一个任务节点的运行时钟为从系统内存中搬运该任务节点所需数据到片上内存所需的时钟、该任务节点基于片上内存执行所需的时钟、将该任务节点的执行结果从片上内存搬运到系统内存所需的时钟三者之和;子网运行时钟为从系统内存中搬运该子网所需数据到片上内存所需的时钟、该子网基于片上内存执行所需的时钟、将该子网的执行结果从片上内存搬运到系统内存所需的时钟三者之和。
10、相较于ai处理器的片上内存,系统内存可以视为相对于片上内存的片外内存,例如,系统内存可以是双倍速率同步动态随机存储器(double data rate sdram,简称ddr),sdram 是synchronous dynamic random access memory的缩写。
11、通过准确预估不同情况下的运行时钟,比较合并前、后的运行时钟差异,可以更准确的计算合并子网可能带来的性能增益,从而进行更合理的子网划分。
12、优选的,ai处理器是gpu,该gpu具有片上内存。
13、在本发明的一些实施例中,所述编译器还被配置为:以ai网络中的一个任务节点为一个初始子网,获得ai网络的初始子网划分结果;基于初始子网划分结果,对ai网络进行多轮子网合并直至无合并性能增益以获得最终的子网划分结果,其中,每轮子网合并时,预估上一轮合并后得到的子网划分结果中任意两个相邻子网合并后的性能增益,并将其中性能增益为正收益且增益最大的两个相邻子网合并为一个新的子网;为所述最终的子网划分结果生成各子网对应的指令。
14、在本发明的一些实施例中,所述编译器还被配置为:以ai网络的一个任务节点为一个初始子网,获得ai网络的初始子网划分结果;基于初始子网划分结果,对ai网络进行多轮子网合并直至无合并性能增益以获得最终的子网划分结果,其中,每轮合并时,预估上一轮合并后得到的子网划分结果中任意两个相邻子网合并后的性能增益,将为正收益的所有性能增益进行降序排列,并基于该降序排列依次进行各性能增益对应的子网合并;为所述最终的子网划分结果生成各子网对应的指令。
15、优选的,所述编译器还被配置为:在基于所述降序排列进行子网合并时,如果性能增益对应的子网合并会改变周围子网结构,则跳过该性能增益对应的子网合并。
16、优选的,所述编译器还被配置为:在进行每一轮子网合并的过程中,根据相邻子网在合并前的运行时钟之和,以及,所述相邻子网合并为一个新的子网后的运行时钟,确定相邻子网合并后的性能增益。
17、优选的,子网的运行时钟为:子网任务总量*子网对应的单位任务量的运行时钟。其中,优选的,所述子网对应的单位任务量的运行时钟为该子网对应的:ai处理器片上内存满载任务量的运行时钟/片上内存满载任务量。
18、例如,若ai处理器是gpu,片上内存满载情况下,子网对应的单位任务量的运行时钟为该子网对应的:gpu片上内存满载任务量的运行时间/片上内存满载任务量,其中,gpu片上内存满载任务量的运行时间包括从系统内存获取满载任务量数据到片上内存的时钟、满载任务量在片上内存执行的时钟、将满载任务量情况下对应的执行结果从片上内存搬运到系统内存的时钟之和。
19、根据本发明的第二方面,提供一种ai网络任务编译方法,所述方法包括:获取ai网络;采用如本发明第一方面所述的编译器对ai网络进行编译,获得ai网络的子网划分结果,以及基于所述ai网络的子网划分结果,为划分确定的各子网生成子网对应的指令。
20、根据本发明的第三方面,提供一种ai网络处理方法,所述方法包括:采用如本发明第二方面所述的方法对ai网络进行编译,获得ai网络对应的编译结果,所述编译结果包括基于ai网络的子网划分结果为子网生成的指令;按照子网划分结果将ai网络对应的任务加载给ai处理器执行,包括将为子网生成的指令加载给ai处理器执行,以使ai处理器在执行这些指令的过程中,在片上内存读取或写入运行子网所需的任务数据。
21、根据本发明的第三方面,提供一种ai网络执行系统,所述系统包括如本发明第一方面所述的编译器、加载器、ai处理器,其中:所述编译器用于确定ai网络的子网划分结果,并基于子网划分结果对ai网络进行编译;所述加载器用于根据编译器确定的子网划分结果将ai网络对应的任务加载给ai处理器;所述ai处理器用于以子网为单位,基于片上内存执行ai网络对应的任务。
22、与现有技术相比,本发明的优点在于:
23、本发明以ai处理器的片上内存容量为基础,通过编译器在编译期间提前对ai网络进行合理的子网划分,并为子网生成对应的指令,以使子网能够基于片上内存执行,有利于保证ai处理器后期在执行子网对应的指令时,能够在片上内存读写运行子网所需的任务数据,保证任务执行效率和速度,同时,本发明的方案无需在编译结束以后再由人工先验的方式选取较优的切分的集合然后使用贪心切分的方式逐渐切开全图,即无需进行多次实验性的运行来获得实验迭代的结果从而进行子网切分,消耗的资源比较小,成本较低,既节省时间又能达到比较优的结果,实用性更强。
- 还没有人留言评论。精彩留言会获得点赞!