一种改进粒子算法、及其在梁结构热误差的建模方法
本发明涉及机械误差分析领域,具体涉及一种改进粒子算法、及其在梁结构热误差的建模方法。
背景技术:
1、梁结构是桁架机器人主要的支撑部件,桁架机器人的机械臂通过各向梁的滑轨实现所在平面上的移动,以横梁为例进行说明,横梁的跨度较大,机械臂在其上移动产生的热变形往往对桁架机器人整体热误差影响较大,造成移动位置精度的下降,因此探寻降低横梁热误差的方法对桁架机器人加工精度的提升至关重要。
2、常规的热变形控制方法,比如改进冷却方式、改变部分结构材料等方法虽然可以取得一定效果,但是这两种方法在实际的加工环境中会导致加工成本密集,并且其方法针对于梁结构本身属性,无法对梁结构的热误差进行补偿;
3、热误差补偿是利用温度场和对应的热误差数据建立热误差预测模型,进而实现对机构的热误差补偿,这种方法在减少加工成本的情况下,能够有效提高生产作业精准、提升产品性能和竞争力;
4、但是使用传统方法,比如多元线性回归模型、粒子群算法pso等方法建立的热误差预测模型,因其无法处理具有强非线性的热误差数据而容易导致建立的模型预测精度较低,无法达到建立实时补偿系统的要求;比如lstm网络中不同的超参数组合往往会带来不同的预测效果,常采用的方法是人工调参进行超参数寻优,这种方法建立的人工调参lstm网络往往需要人工多次调整参数,费时费力;而使用传统粒子群算法作为超参数优化算法建立的传统pso-lstm网络,往往因传统粒子群算法容易陷入局部最优而无法取得较稳定的预测精度;同时,热误差数据是一个动态的时间序列,其随着历史温度值等因素变化而变化,每一个时刻的热误差都与当前时刻的热误差、以及历史热误差密切相关。
技术实现思路
1、本发明目的在于提供一种改进粒子算法,拥有更快的搜索速度、及搜索精度,且不容易和传统粒子群算法一样陷入局部最优,适用于处理强非线性热误差数据;
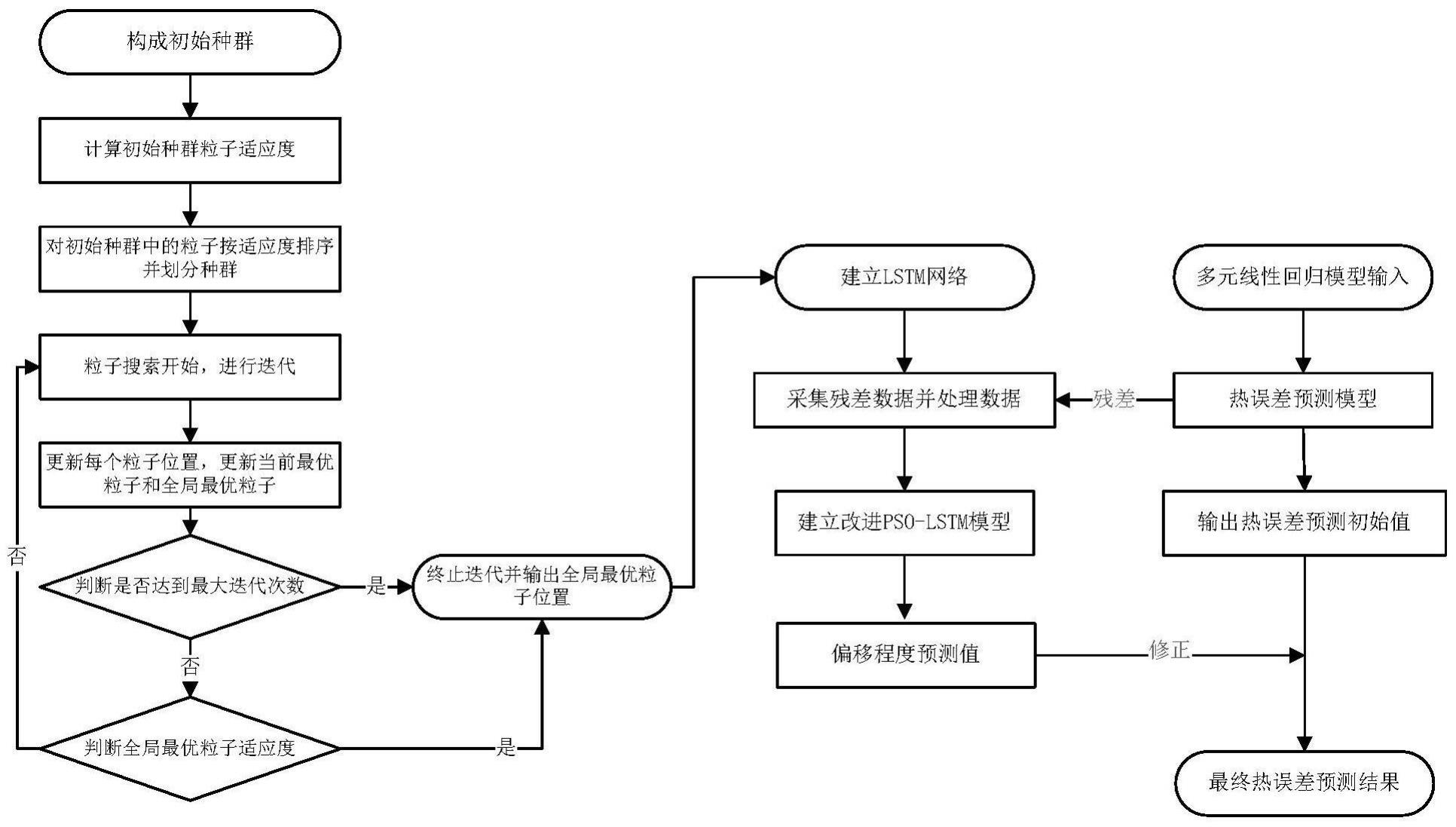
2、为实现上述目的,本一种改进粒子算法,具体包括以下步骤:
3、1)在预设范围内随机产生粒子以构成初始种群;
4、2)计算初始种群中每个粒子的适应度,将初始种群中适应度最优的粒子作为初始的当前最优粒子和全局最优粒子;
5、3)对初始种群中的粒子按适应度排序并划分种群;
6、4)粒子搜索开始,针对不同的种群的粒子采用不同的速度更新过程,进行迭代,并设置最大迭代次数与终止迭代的适应度值;
7、5)迭代完成后更新每个粒子位置,更新当前最优粒子和全局最优粒子,并判断是否达到最大迭代次数,若达到则终止迭代,否则继续执行步骤6);
8、6)判断全局最优粒子的适应度是否满足终止条件,若满足则终止迭代并输出全局最优粒子的位置,否则继续迭代,循环执行步骤4)-步骤6)。
9、进一步的,所述步骤2)中,当前最优粒子为每一次迭代中产生的适应度值最优的粒子,全局最优粒子为从开始迭代到终止迭代的过程中产生的适应度值最优的粒子。
10、进一步的,所述步骤3)中把初始种群中的粒子按照适应度值从大至小进行排序,适应度值小的一半划分为优秀种群,适应度值大的一半划分为普通种群;
11、步骤4)中针对优秀种群的粒子,其速度更新过程为:
12、
13、针对普通种群的粒子,其速度更新过程为:
14、
15、
16、其中,w为惯性因子,通常在0到1之间;表示第k迭代中第i个粒子第j坐标的速度,为第k次迭代中第i个粒子第j坐标的位置向量;c1为学习因子,rand()为[0,1]之间的正态分布函数;表明第k次迭代中第i个粒子第j坐标的个体最优解,gbi j为第i个粒子第j坐标的全局最优解;
17、表示速度变量,0<ξ-<1<ξ+cos()表示方向向量的余弦,从粒子当前位置到全局最优值位置向量作为方向向量;当两个余弦的乘积大于零时,表示粒子正在向最优解位置移动;如果两个余弦的乘积小于零时,则表示粒子在最优位置附近徘徊;如果两个余弦的乘积为0,则相对不变。
18、进一步的,所述步骤5)中,当前最优粒子和全局最优粒子的更新过程为:
19、以第k次迭代为例,个体最优解和全局最优解的更新过程为:
20、
21、
22、其中,个体最优解,表明第k次迭代中粒子的最优解;g(x)为适应度值;为第k次迭代中粒子的位置向量;gbi=[gb1,...gbn]t全局最优解,表明整个迭代过程中的最优解。
23、本发明目的在于提供一种改进粒子算法在梁结构热误差的建模方法,能够对多元线性回归模型的热误差预测值进行修正,能够处理强非线性热误差数据、预测精度更高且更稳定,不仅不需要人工多次调整参数,而且避免陷入局部最优而影响预测精度。
24、一种梁结构热误差的建模方法,具体包括如下步骤:
25、a.采集桁架机器人梁结构温度及其热伸长量数据,作为多元线性回归模型的输入以建立梁结构热误差预测模型,并输出热误差预测值predl;
26、b.对梁结构热误差预测模型的残差数据进行处理;
27、c.以权利要求4所述的一种改进粒子算法作为lstm网络的超参数优化算法,初始种群中每个粒子的位置映射为lstm网络的时间窗口大小、批处理大小、单元数量;并以平均绝对误差mae作为改进粒子群算法的适应度,适应度值越小表示粒子越优秀,使用lstm网络对多元线性回归模型的偏移程度进行预测;
28、d.每次迭代完成后,更新当前最优粒子和全局最优粒子的位置并输出,判断全局最优粒子的位置的适应度是否满足预设要求,若不满足,则执行步骤e,若满足,则终止迭代并执行步骤f;
29、e.判断迭代次数是否达到最大值,若是,则终止迭代并执行步骤f,若否,则继续迭代,循环步骤d和e;
30、f.以输出全局最优粒子的位置映射的时间窗口大小、批处理大小、单元数量作为lstm网络的最终超参数,建立改进pso-lstm模型;
31、使用改进pso-lstm模型对多元线性回归模型的偏移程度进行预测,得到偏移程度预测值prede;
32、g.使用偏移程度的最终预测值对多元线性回归模型的偏移程度进行修正,得到最终热误差预测结果preda,其修正方法为:
33、predl±prede=preda。
34、进一步的,当偏移程度对应的多元线性回归模型的残差大于0时,
35、predl+prede=preda;
36、偏移程度对应的多元线性回归模型的残差小于或等于0时,
37、predl-prede=preda。
38、进一步的,所述步骤b中,建立仿真模型,通过数值分析软件计算梁结构的仿真热伸长量、并将其作为目标函数来对梁结构的实际热伸长量进行预测,从而得到多元线性回归模型的残差数据。
39、进一步的,所述步骤f得到偏移程度预测值prede、以及步骤g中得到的最终热误差预测结果preda,均采用平均绝对误差mae、均方根误差rmse和均方误差mse作为相应模型的性能评估指标,其值越小表示模型性能越优秀;
40、平均绝对误差mae公式为:
41、
42、均方根误差rmse公式为:
43、
44、均方误差mse公式为:
45、
46、其中,n为样本数,predictedi和observedi分别表示第i个样本的预测值和观测值。
47、进一步的,所述步骤b中,将热误差预测模型的残差数据的绝对值先作为多元线性回归模型的偏移程度,再采用归一化的方法对多元线性回归模型的偏移程度进行处理。
48、与现有技术相比,本一种改进粒子算法对初始种群中的粒子按适应度排序并划分种群,针对不同种群的粒子采用不同的速度更新方式,对适应度值一般的粒子加速以提高搜索效率,对适应度值优秀的粒子速度进行控制以提高搜索精度,同时通过全局最优粒子的位置、最大迭代次数进行循环,相较于传统粒子群算法的单种群且速度更新方式固定的搜索方式,本算法拥有更快的搜索速度,及搜索精度,且不容易和传统粒子群算法一样陷入局部最优;
49、本梁结构热误差的建模方法,基于机理与数据驱动、热误差数据作为时间序列数据,首先利用多元线性回归模型建立热误差预测模型,并将其残差通过数据处理,使用改进的pso算法对lstm网络的时间窗口大小、批处理大小、单元数量这些超参数进行寻优、使用最优超参数建立改进pso-lstm模型对多元线性回归模型的热误差预测值进行修正,能够处理强非线性热误差数据、预测精度更高且更稳定,不仅不需要人工多次调整参数,而且避免陷入局部最优而影响预测精度。
- 还没有人留言评论。精彩留言会获得点赞!