基于小样本学习的眼底照片分类方法与流程
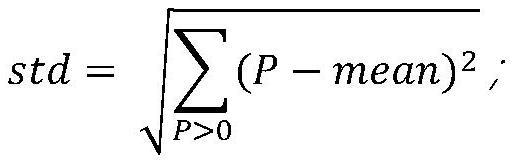
本发明属于图片分类领域,具体涉及一种基于小样本学习的眼底照片分类方法。
背景技术:
1、视觉是人们认识世界,获取知识最主要的信息接受器。眼球作为视觉的器官载体,包括视盘(视神经)、血管、视网膜组织及脉络膜等,是全身唯一能用肉眼直接、集中观察到动脉、静脉和毛细血管的部位,这些特征往往能够反映出人体的多种属性,如年龄、性别或者存在某些疾病等。若非专业人士,这些信息往往难以直接通过人工观察得出,必须借助计算机技术来帮助识别和分类。
2、基于机器学习和人工智能的计算机技术发展至今,已经有大量的研究人员投入到了图片分类的工作中。其中包括对自然景物的分类,手写字体的分类,动物的分类等。其中,对于眼底照片的分类还相对较少,并且,在根据眼底图像来对年龄、性别等进行分类判断的过程中,仍然存在着诸多问题:首先,眼底数据集在数量和质量上都面临着较大的考验。传统的深度学习算法通常需要大量的数据支撑,但是网络上公开的眼底数据集如ddr,、aptos都远远达不到足够的规模。在单个数据集中,眼底图片的来源也五花八门,颜色、清晰度、对比度、亮度、尺寸、眼球完整度等各不相同,质量层次不齐。第二,眼底数据集存在严重的数据失衡现象,包括数量上的不平衡以及难易程度上的不平衡。通常占比最高的一类眼底数据会占到总数据量的一半左右,甚至更高,而占比最少的数据可能只有其1/20~1/30。这种不平衡会导致机器学习模型在训练的过程中忽略对少数类别的特征学习,而更加关注多数类别的样本,最终导致模型效果较差,准确率虚高的问题。同时,还可能会遇到某类数据在数量少的同时,还难以被区分。第三,目前对眼底图片分类任务的研究几乎都忽略了其标签之间的关联性。通常我们使用one-hot编码来表示输入数据的标签,并以此作为参数输入到损失函数中进行损失计算,更新模型。不同于常见的分类任务,比如以年龄段划分的不同类别的眼底图片,他们之间存在着一定的,可推断的联系,如少年眼底与青年眼底的距离必然是小于少年眼底与老年眼底的距离,若仍然简单粗暴地使用one-hot编码方式确定类别间的距离,则显得不够合理。上述三个问题,导致机器学习在眼底图片分类任务的表现仍然存在较大的改进空间。
3、基于上述技术问题,本发明提出了一种基于小样本学习的眼底照片分类方法,以用于辅助眼底图片分类,并扩充不同分类标准的眼底数据集。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一,提供一种基于小样本学习的眼底照片分类方法。
2、包括两个阶段:模型训练阶段和实际应用阶段;
3、所述模型训练阶段包括读取多个眼底图片数据及其标签并进行标准化处理和增强处理;
4、根据处理后的眼底图片数据和关系加权标签训练和构建基于小样本学习的网络模型;
5、所述实际应用阶段包括读取未分类的眼底图片数据并进行标准化处理;
6、将所述处理后的未分类的眼底图片数据输入所述基于小样本学习的网络模型,将所述模型输出的向量中,值最大的类别作为所述眼底照片的分类结果。
7、可选的所述模型训练阶段包括读取多个眼底图片数据及其标签并进行标准化处理和增强处理,包括:
8、读取照片文件路径,使用通过opencv-python库打开对应的眼底图片数据;
9、对眼底图片进行标准化处理,包括:
10、使用圆形裁剪方法,把眼底图片裁剪为512*512像素大小,背景为纯黑,正中央为圆形眼底的格式;
11、使用剔除背景的归一化方法,计算剔除背景区域后的眼底图片像素值均值与标准差;
12、对图片进行增强处理,包括:
13、对所述眼底图片进行随机上下翻转、随机左右翻转和随机旋转处理。
14、可选的所述圆形裁剪方法,包括:初步裁剪和二次裁剪;
15、所述初步裁剪的具体关系式如下:
16、p′=cutg(mask(pg,tol),po);
17、其中,po表示原始眼底图片,pg表示po转化后的灰度图片,tol表示阈值超参数,mask表示根据阈值tol划分眼底区域和背景区域,并得到对应的掩膜,cutg表示根据掩膜,将原始图片po的多余背景进行裁剪,得到初步裁剪的图片p′,使眼底区域的边缘成为图片的边缘;
18、所述二次裁剪的具体关系式如下:
19、
20、其中,l表示p′中较长边的长度,resize表示将图片缩放成指定的大小;cutc表示在图片中心,以l/2为半径,裁剪出一个圆形区域作为最终的眼底区域,其余部分的像素值设为0,作为背景区域,最后将图片缩放为512*512像素,得到最终符合标准的眼底图片p。
21、可选的所述剔除背景的归一化方法,包括:
22、区分眼底图片的眼球区域和背景区域;
23、计算眼球区域的像素值均值和标准差;
24、具体关系式如下:
25、
26、
27、其中,∑p>0p表示累加图片p中大于0的像素值,count(p>0)表示统计图片p中大于0的像素个数,mean和std分别表示图片剔除背景的均值和标准差。
28、可选的所述根据处理后的眼底图片数据和关系加权标签训练和构建基于小样本学习的网络模型,包括:
29、根据图片真实标签将所述处理后的眼底图片数据划分为查询集和支持集;
30、将查询集和支持集一起输入基于小样本学习的网络;
31、由网络输出对眼底图片数据的预测结果;
32、根据所述关系加权标签与所述眼底图片数据的预测结果,计算所述交叉熵损失,并反向传播更新所述模型参数;
33、循环损失计算与参数更新的过程,直到损失趋于稳定,不再下降,得到所述基于小样本学习的网络模型。
34、可选的所述查询集和支持集,划分方式为:
35、从所述处理后的眼底图片数据中,每个类别抽取k张图片,作为支持集,具体关系式如下:
36、
37、其中,s表示支持集,c表示不同的类别数,k表示每个类别抽取的图片数,xi和yi分别表示处理后的眼底图片数据和真实标签;
38、得到支持集后,剩余的所述处理后的眼底图片数据,全部作为查询集,具体关系式如下:
39、
40、其中,q表示查询集,m表示眼底图片的总数据量,xj和yj分别表示剩余的处理后的眼底图片数据和真实标签,c和k与上述关系式的中的含义相同。
41、可选的,所述基于小样本学习的网络,包括:特征提取模块、距离度量模块;
42、所述特征提取模块,采用u-net3网络计算并提取所述查询集和支持集的特征图,具体关系式如下:
43、fi=extractor(xi),(i=1,2,…,c);
44、其中,fi表示眼底图片数据xi经过u-net3网络得到的特征图,extractor表示特征提取模块;
45、所述距离度量模块,包括:
46、将查询集中提取到的特征图与支持集中提取到的特征图在通道维度上进行拼接,具体关系式如下:
47、fij=fi⊕fj,(i=1,2,…,c);
48、其中,fi和fj分别表示i类支持集和查询集中提取到的特征图,⊕表示将两个特征图在通道维度上进行拼接,fij表示拼接后的特征图;
49、将拼接后的特征图f输入resnet18网络,计算所述支持集和查询集的分数向量,选择最大分数最大的类型作为眼底图片数据的预测结果,具体关系式如下:
50、rij=distance(fij),(i=1,2,…,c);
51、其中,rij表示查询集在i类上的得分,distance表示距离度量网络。
52、可选的,所述根据所述关系加权标签与所述眼底图片数据的预测结果,计算所述交叉熵损失,并反向传播更新所述模型参数,包括:
53、所述关系加权标签,可以在3种加权方式上进行选择,其具体关系式如下:
54、
55、
56、
57、其中,i表示真实标签,j表示预测标签,n表示类别数,weightaij,weightbij,wrightcij分别是在真实标签为i,预测标签为j的条件下,标签向量对应位置的3种关系权重;三者在正确标签的位置上的值均为1,随着错误标签与正确标签距离d(d=abs(i-j))的增加,三者的值分别以递增,稳定,递减的速度下降,当标签距离达到最大,即标签分别为0和n-1时,权重值为0,达到最小;
58、所述交叉熵损失计算的具体关系式如下:
59、
60、其中,i表示输入数据实际所属类别,outi表示模型在对应类位置的直接输出,yi表示对应位置上的关系权重,由关系加权标签决定,softmax(outi)表示通过softmax函数计算得到对应类型的预测概率;
61、计算得到损失值后,反向传播更新所述模型参数。
62、可选的,所述实际应用阶段包括读取未分类的眼底图片数据并进行标准化处理,包括:
63、读取所述未分类的眼底照片数据后,只进行所述标准化处理,不进行增强操作,然后输入所述基于小样本学习的网络模型中。
64、可选的,将所述处理后的未分类的眼底图片数据输入所述基于小样本学习的网络模型,将所述模型输出的向量中,值最大的类别作为所述眼底照片的分类结果,包括:
65、采用所述的基于小样本学习的网络模型,对所述未分类的眼底图片数据进行预测;
66、将模型输出输出的向量中,值最大的类别作为所述眼底图片的分类结果;
67、对所述的分类结果不进行损失计算,不对所述模型参数进行更新。
68、本发明提供一种基于小样本学习的眼底照片分类方法。本发明对于眼底图片的标准化处理,能够尽可能统一眼底图片的格式,将图片眼球区域和背景区域清晰地区分开来,也可以很好的避免黑色背景区域的极端像素值(等于0)对眼底区域的均值和标准差的计算产生干扰,得到的均值与标准差将实现更加合理的数据分布。本发明还使用关系加权标签改进了传统one-hot标签,能够让不同标签间的距离得到更合理的体现,实现更好的损失计算,还能够对严重失衡的数据实现一定的平衡。
- 还没有人留言评论。精彩留言会获得点赞!