一种基于主动学习的开放集图像识别方法及系统
本发明涉及机器学习开放集图像识别,尤其涉及一种基于主动学习的开放集图像识别方法及系统。
背景技术:
1、图像分类问题是计算机视觉领域最基本的问题,具有广阔的应用场景。在实际生活中,例如,交通管理领域中通过对拍摄的车辆图片进行分类,实现更好的城市道路规划;电子商务领域中通过对客户浏览的商品图案进行分类,更精准的向客户进行商品推荐;农业领域中通过对采集的昆虫图片进行分类,指导农民及时发现害虫并进行防治。图像分类的目标是将不同的图像划分到不同的类别,实现最小的分类误差。近年来,基于深度学习的图像分类技术往往通过大量标记图像数据学习分类模型,对无标记的图像数据进行类别预测,这个过程是封闭的,即标记数据和未标记数据中的图像属于相同类别。然而,现实应用场景是开放的,在未标记数据中通常会出现与标记数据类别不同的图像,标记数据和未标记数据之间的类别空间不同,导致模型对未标记样本的预测性能降低。开放集图像识别任务要求分类器不仅要准确地对已见类数据进行分类,还要有效地处理新类数据。
2、已有的开放集图像识别方法主要有样本重加权和开放集检测评分。样本重加权方法的思想是为开放集图像分配较低的权重,降低其对模型训练的影响。样本重加权方法中涉及基于元学习的无标记数据重加权机制以及基于距离的无标记数据重加权机制。开放集检测评分的目的是设计一个评分机制,为每个未标记的图像数据计算一个开放集评分,根据分数和预定义的阈值检测开放集图像。在开放集图像识别领域,基于模型预测集成的开放集实例检测评分机制和基于度量的开放集检测评分机制未考虑未标记样本的信息,仅从有限的标记数据中学习,无法有效提升开放集图像的识别性能。基于噪声标签优化的方法、基于一对多分类器的方法以及基于图像特征和类别标签匹配得分的方法提出考虑挖掘未标记样本的信息提升模型表达能力,但是这些方法对未标记数据的评估和伪标记信息的利用不足,难以学习到类别区分度较高的特征表示,导致开放集识别准确率较低,影响图像分类的精度。
技术实现思路
1、为解决现有技术的不足,本发明提出一种基于主动学习的开放集图像识别方法及系统。通过引入已见类别的语义知识,构建语义知识和图像特征的映射关系。利用阈值选择策略区分开放集样本和已见类样本,之后通过主动学习模型迭代地识别高置信度开放集样本和已见类样本,并将高置信度的已见类样本及其计算得到的伪标签添加到标记数据集中,减少开放集样本对分类模型的影响并充分利用未标记数据扩充标记数据集。
2、本发明的目的是通过下述技术方案实现的:
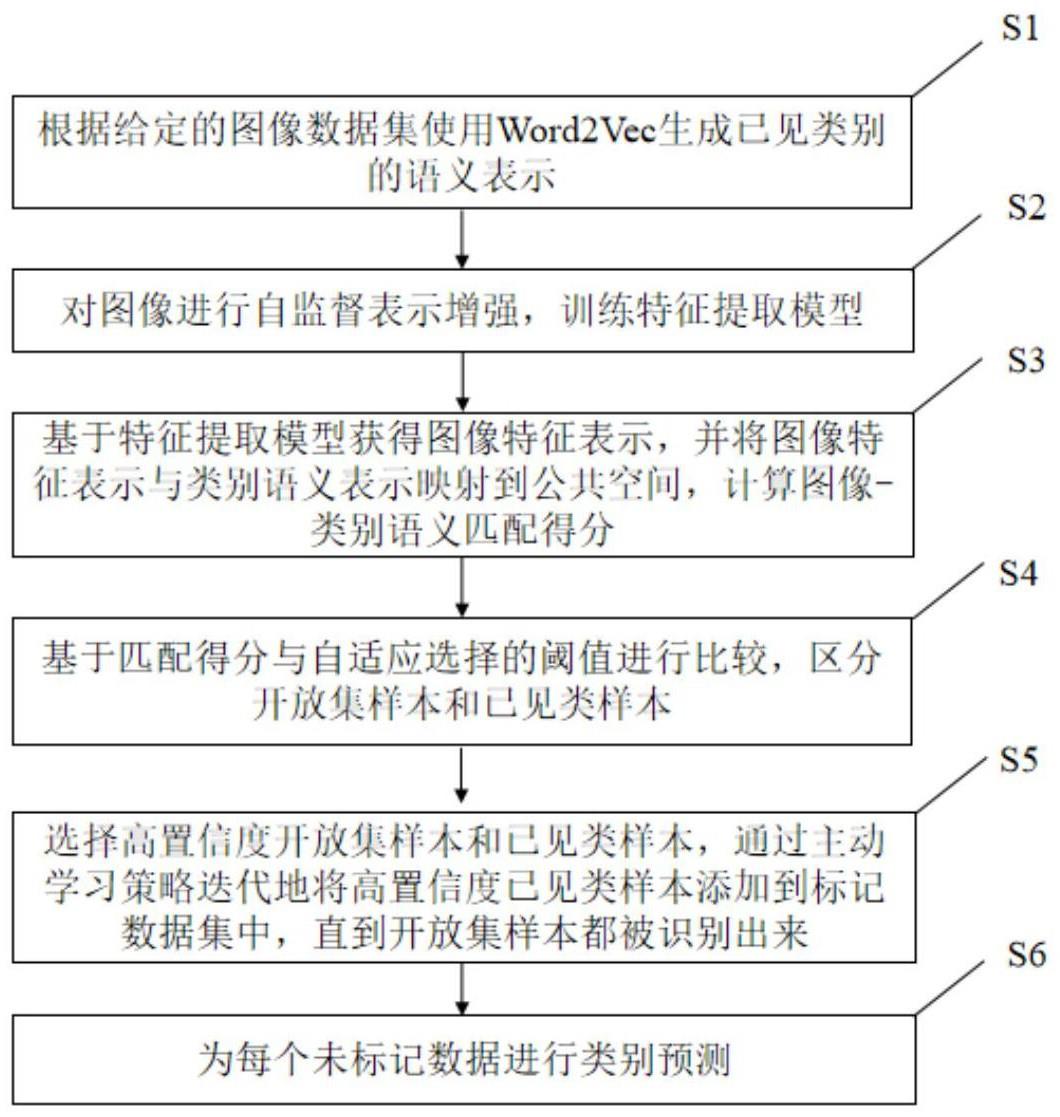
3、一种基于主动学习的开放集图像识别方法,包括如下步骤:
4、s1:给定标记图像数据集和未标记数据集利用语言模型word2vec生成已见类图像对应的类别语义表示
5、s2:引入图像旋转预测框架rotnet,对给定图像数据集中的图像分别旋转0°、90°、180°和270°,进行自监督表示增强学习,训练图像特征提取模型,构造自监督损失lsef;
6、s3:利用图像特征提取模型对所有图像进行特征表示,融入类别语义知识,将图像特征和类别语义知识映射到公共空间进行相似度计算,利用余弦相似度,计算图像特征和类别语义匹配得分,构造匹配损失lma;
7、s4:通过otsu算法自适应选择预定义的阈值,将匹配得分与预定义的阈值进行比较,匹配得分低于阈值的未标记图像认为是开放集图像,匹配得分高于阈值的未标记图像认为是已见类图像;
8、s5:采用主动学习策略,选择高置信度开放集样本和高置信度已见类样本,top-k得分最高的样本是高置信度样本,将高置信度已见类样本及其计算得到的伪标签添加到标记数据中进行训练,以此形成循环,直到开放集样本都被识别出来,同时实现标记数据集的扩充;
9、s6:为每个未标记数据进行类别预测,构造分类损失lce。
10、进一步,步骤s1包括:给定标记样本集和一个未标记样本集其中和分别表示有标记和无标记的图像,表示有标记样本的真实标签,标记样本集中包含k个目标类别,即为每个类别定义一个语义表示表示类别语义特征。
11、进一步,步骤s2包括:引入图像旋转预测框架rotnet,对所有标记数据和未标记数据进行自监督表示增强学习,将每张图像分别旋转0°、90°、180°和270°生成4个对应图像,并预测类别概率,对于图像特征xi,旋转之后的特征xi,j=xi*(j-1)*90°,其中j=1,2,3,4,旋转后的预测概率qi,j:
12、qi,j=h(f(xi,j)),
13、其中h(·)表示1个线性层和1个softmax函数,训练过程的自监督损失函数为:
14、
15、进一步,步骤s3包括:将图像特征和类别语义特征映射到公共空间实现视觉特征和语义特征的对齐,对于语义特征,利用word2vec得到已见类语义表示,对于图像x和它的标签y,首先提取图像x的特征z=f(x),接着抽取标签y对应的语义表示a,然后将z和a映射到一个公共空间进行相似度计算,利用余弦相似度,得到样本x和标签y的匹配得分:
16、s(x,y)=s(z,a)=cos(f(x),a),s(x,y)通过计算图像和类别语义相似度的大小来反映y是否是x的正确类别标签,其中类别语义相似度大的被认为是正确的类别标签;
17、随机选择除真实标签和最难区分标签之外的标签下面是模型训练的损失函数,标记数据的损失函数如下:
18、
19、其中,和分别表示最难区分的标签和随机选择的标签,
20、
21、
22、对于每一个未标记数据假设其预测概率为其伪标签未标记数据的损失函数如下:
23、
24、其中,
25、由此构造匹配损失lma:
26、
27、进一步,步骤s4包括:阈值通过otsu算法自适应的选择,对于某一批次样本,首先按照s中匹配得分值进行直方图的构造,对得分值进行归一化后进行正向累积求和与水平翻转求和,分别得到w1和w2,接着分别计算每个得分在正向累计求和中和水平翻转求和中的平均值和m1和m2:
28、
29、
30、再根据平均值计算方差v:
31、v=w1*w2*(m1-m2)2,
32、最后最大化方差,方差最大值对应的得分即为阈值t:
33、
34、进一步,步骤s5包括:采用主动学习策略,选择高置信度开放集样本和高置信度已见类样本,将高置信度已见类样本及其计算得到的伪标签添加到标记数据中进行训练,以此形成循环并完成开放集样本的识别,top-k得分最高的样本是高置信度样本,对所有未标记样本的匹配得分si由大到小进行排序,选择top-k个得分最高的样本及其计算得到的伪标签加入到标记数据集中,top-k个得分最低的样本被认为是开放集样本,高置信度样本选取数量k根据开放集样本数目来确定,完成一轮开放集样本和已见类样本的挑选后,进行下一次迭代,并不断更新特征提取网络,直到所有开放集数据都被识别出来。
35、进一步,步骤s6包括:对每个输入图像xi提取特征表示:zi=f(xi),f(·)表示特征提取网络的计算函数,在特征提取网络上附加一个线性层和一个softmax层,得到k维类别概率向量pi:
36、pi=g(zi)=g(f(xi)),
37、其中,g(·)表示线性层和softmax操作,在训练阶段,利用交叉熵损失来优化标记图像的类别概率向量:
38、
39、其中,表示的预测概率。
40、一种基于主动学习的开放集图像识别系统,包括以下模块:
41、类别语义生成模块:根据给定的图像数据集中标记图像对应的类别,使用语言模型word2vec生成类别的语义表示;
42、自监督表示增强模块:引入图像旋转预测框架rotnet,对给定图像数据集中的图像分别旋转0°、90°、180°和270°,进行自监督表示增强学习,训练一个图像特征提取模型;
43、知识指导的开放集检测模块:利用resnet对图像进行特征表示,融入类别语义知识,将图像特征和类别语义知识映射到公共空间进行相似度计算,利用余弦相似度,计算图像特征和类别语义匹配得分;
44、类别区分模块:通过otsu算法自适应的选择阈值,将匹配得分与预定义的阈值进行比较,匹配得分低于阈值的未标记图像认为是开放集图像,匹配得分高于阈值的未标记图像认为是已见类图像;
45、主动学习模块:采用主动学习策略,选择高置信度开放集样本和高置信度已见类样本,将高置信度已见类样本及其计算得到的伪标签添加到标记数据中进行训练,以此形成循环并完成开放集样本的识别和标记数据集的扩充;
46、图像分类模块:为每个未标记数据进行类别预测。
47、综上所述,发明具有以下有益效果:
48、本发明引入已见类别的语义知识,利用阈值选择策略及主动学习方法迭代识别开放集样本,减少开放集样本对分类模型的影响并充分利用未标记数据扩充标记数据集。
- 还没有人留言评论。精彩留言会获得点赞!