基于大数据和知识图谱的推荐方法与装置与流程
本发明提供了一种基于大数据和知识图谱的推荐方法与装置,用于高考志愿推荐,属于教育数据分析与智能算法推荐。
背景技术:
1、高考是当前选拔人才的重要途径,学生在获得高考成绩之后需要进行高考志愿填报。传统的高考志愿填报方式是学生及家长通过阅读教育部门印发的《高考志愿填报指南》,了解各个院校的专业设置情况以及录取分数和位次,从中筛选出适合学生高考分数和位次的院校及专业,并依据院校及专业的录取分数和位次,按照“冲刺”、“稳妥”、“保底”的策略调整每一条志愿在志愿填报表单中的优先顺序,最终形成一套志愿填报方案。该方法存在以下问题:(1)院校和专业的样本数量是非常庞大的,仅依靠人工的方式很难细致全面的了解院校和专业的录取情况。(2)院校和专业往年的录取分数和位次存在波动,只看一年的录取分数和位次不足以分析该志愿是应该作为“冲刺”志愿,还是“稳妥”志愿,或者是“保底”志愿,而人工分析往年录取数据的工作量是非常艰巨的。(3)许多专业的在培养阶段学习的课程,未来就业的领域以及职业发展的方向是非常接近的。学生在选择专业时往往参考家长和老师的经验,家长和老师对于其了解的专业可以做出准确的判断,但是对于其不了解的专业,则很难分析和掌握专业之间的相关性,从而在志愿填报的过程中失去了很多有价值的参考信息。
2、近年来随着互联网和大数据技术的发展,许多研究机构开发了辅助高考志愿填报的系统。现有的高考志愿辅助系统大多只能提供简单的院校及专业历史录取分数位次查询。较为智能化的产品,则会运用数学公式和人工规则以及简单的神经网络选择与考生位次匹配的院校专业,并评估考生被这些院校专业录取的概率。以上方法仍然存在缺点:(1)不同分数段的考生数量分布是不同的,简单的数学公式和人工规则难以迁移到各个分数段,而根据不同分数段设计不同的人工规则和计算公式,在实际执行过程中难度大,成本高。(2)神经网络模型虽然能自动捕获数据特征,减少人工设计规则和特征的成本,但是在高考志愿预测领域,数据具有很强的时序特征,比如在评估一个院校专业是否可以报考时,会参考该院校专业近几年的录取位次,而同一个专业在不同年份的录取位次会产生波动,一般的神经网络不具备捕获时序特征的能力。(3)在推荐专业时不能充分满足考生对于专业的意愿,从而让用户觉得产品不够智能化和人性化。
技术实现思路
1、针对上述研究的问题,本发明的目的在于提供基于大数据和知识图谱的推荐方法与装置,解决现有技术在推荐专业时不能充分满足考生对专业的意愿的问题。
2、为了达到上述目的,本发明采用如下技术方案:
3、一种基于大数据和知识图谱的推荐方法,包括:
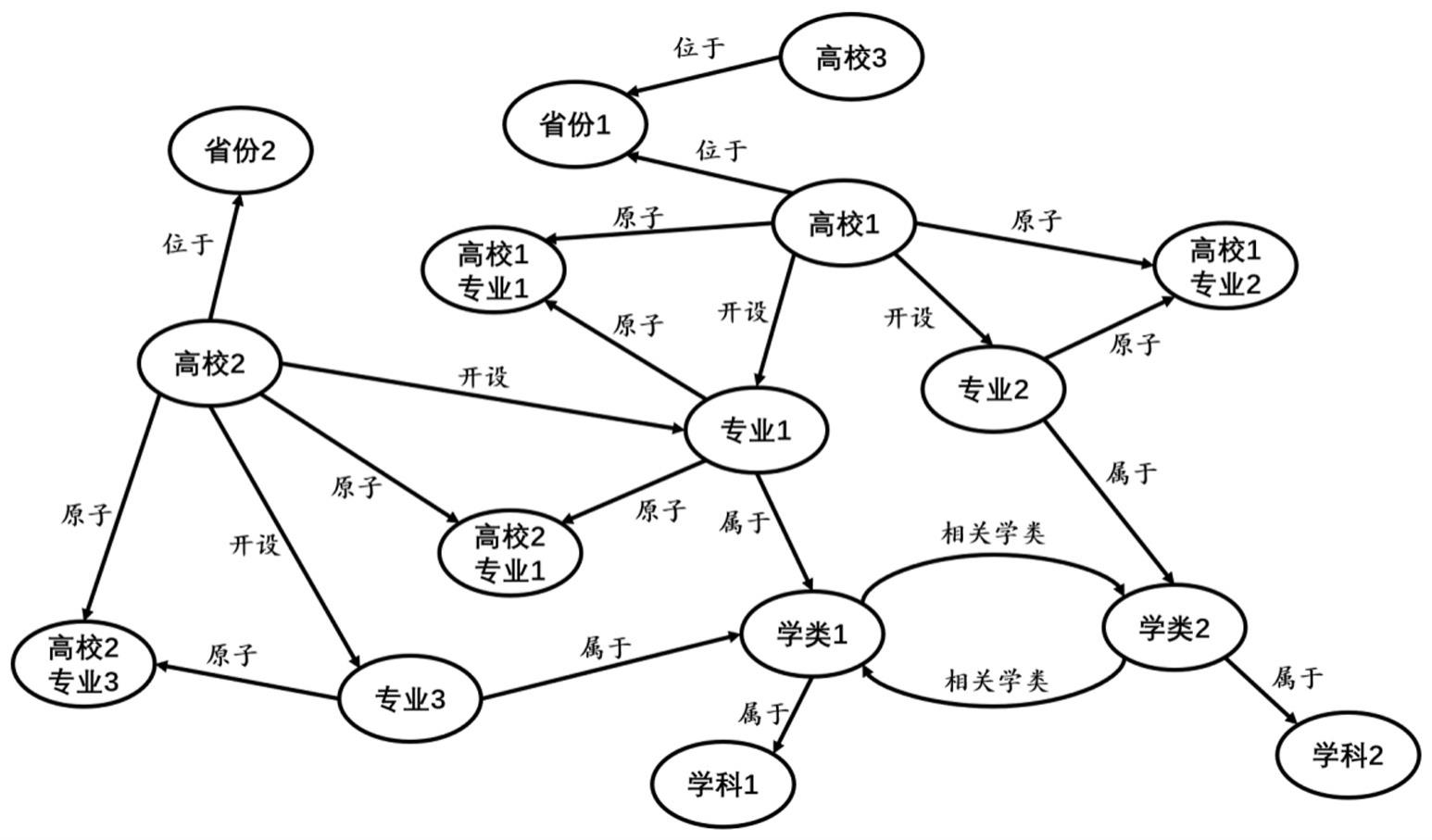
4、s1. 根据考生所意向的学类实体和专业实体查询高考志愿服务知识图谱,得到专业实体集合;
5、s2.根据用户输入的意向省份,在高考志愿服务知识图谱中查询匹配的省份实体;
6、s3.在高考志愿服务知识图谱中查询与省份实体具有位于关系的高校实体集合;
7、s4.在高考志愿服务知识图谱中同时查询与专业实体集合以及高校实体集合具有原子关系的原子术语实体集合;
8、s5.根据考生的位次和原子术语实体集合,过滤掉与考生位次不匹配的原子术语实体,过滤后得到候选高校专业集合。
9、进一步,所述高考志愿服务知识图谱包括:
10、高校实体:是指高考志愿服务知识图谱中名称定义为高校名称的一类节点,用于表示高校,包含的属性有该高校的基本介绍、是否为985高校、是否为211高校、是否为双一流高校、距离报考当年一年前该高校的录取位次、距离报考当年二年前该高校的录取位次和距离报考当年三年前该高校的录取位次;
11、专业实体:是指高考志愿服务知识图谱中名称定义为三级专业名称的一类节点,用于表示专业,包含的属性有该专业的基本介绍;
12、原子术语实体:是指高考志愿服务知识图谱中名称定义为高校名和专业名组成的细粒度的一类节点,用于表示由高校和专业组成的原子,包含的属性有距离报考当年一年前该高校该专业的录取位次、距离报考当年两年前该高校该专业的录取位次和距离报考当年三年前该高校该专业的录取位次;
13、省份实体:是指高考志愿服务知识图谱中名称定义为省份及直辖市名称的一类节点,用于表示省份;
14、学类实体:是指高考志愿服务知识图谱中名称定义为二级学类名称的一类节点,用于表示二级学类,包含的属性有该学类的基本介绍;
15、学科实体:是指高考志愿服务知识图谱中名称定义为一级学类名称的一类节点,用于表示一级学科,包含的属性有该学科的基本介绍;
16、开设关系:是指以高校实体作为头实体,以专业实体作为尾实体,从头实体指向尾实体的有向边;
17、位于关系:是指以高校实体作为头实体,以省份实体作为尾实体,从头实体指向尾实体的有向边;
18、原子关系:是指以高校实体作为头实体,以原子术语实体作为尾实体,从头实体指向尾实体的有向边;或指的是以专业实体作为头实体,以原子术语实体作为尾实体,由头实体指向尾实体的有向边;
19、属于关系:是指以专业实体作为头实体,以学类实体作为尾实体,从头实体指向尾实体的有向边;或指的是以学类实体作为头实体,以学科实体作为尾实体,从头实体指向尾实体的有向边;
20、相关学类关系:是指两个相关或相似的学类实体之间的有向边。
21、一种高校专业填报策略分档方法,包括:
22、模型训练阶段:
23、步骤1.对获取的训练数据集进行预处理;
24、步骤2.构建基于lstm的录取成功率预测模型,并用预处理后的训练数据集进行训练,得到训练好的录取成功率预测模型;
25、模型使用阶段:
26、步骤3.获取考生的候选高校专业集合,利用训练好的录取成功率预测模型对候选高校专业集合中的全部高校中的各专业进行预测,计算考生被各院校中各专业录取的成功率,其中,各专业包括法学、土木工程、计算机应用和电气自动化;
27、步骤4.将候选高校专业集合中的各高校中的各专业按照成功率得分划分为“冲”、“稳”、“保”三类院校专业集合,所述“冲”表示此高校中的该专业集合录取难度最大,所述“稳”表示此高校中的该专业集合录取难度适中,所述“保”表示此高校中的该专业集合录取难度最小。
28、进一步,所述步骤1具体为:
29、步骤11.获取各高校各专业公示的历年历史录取数据,当年的前一年定义为y,y之前的第三年定义为y1,y之前的第二年定义为y2,y之前的第一年定义为y3,所述的历史录取数据指的是y年、y1年、y2年、y3年各高校中各专业的录取数据;
30、所述历史录取数据定义如下:各高校中各专业在y1年的录取位次为rank1,在y2年的录取位次为rank2,在y3年的录取位次为rank3,在y年的录取位次定义为rank_update;
31、步骤12.将所述历史录取数据取rank_update的值作为中心位次,根据某省y年的一分一段表将rank_update映射为具体的分数score_update;步骤13.取分数score_update向上5分以及向下5分的全部分数组成一个浮动分数集合,记作sample_score1, sample_score2,…sample_score11,其中,分数score_update为sample_score6;
32、步骤14.将所述浮动分数集合中的分数根据某省y年的一分一段表转换为具体的位次,记作sample_rank1, sample_rank2,…,sample_rank11,组成一个浮动位次集合;
33、步骤15.将所述浮动位次集合中的各位次sample_ranki分别与所述rank1、rank2、rank3和rank_update进行组合,组合后生成一个浮动样本集合,浮动样本集合内有11个样本;
34、步骤16.将所述浮动样本集合中的各样本中的sample_ranki与rank_update进行比较,若sample_ranki大于rank_update,则样本中新增变量resign_labeli=0,表示未能被录取,若sample_ranki小于rank_update,则样本中新增变量resign_labeli=1,表示能被录取;
35、步骤17.将各高校中的各专业的rank1、rank2、rank3与计算得到的各sample_ranki和resign_labeli组合生成一条训练样本,其中,一个高校中的一个专业共计生成11条训练样本;
36、步骤18.基于步骤17得到的结果,将各高校中的各专业生成的训练样本进行组合,生成训练基于lstm的录取成功率预测模型的训练数据集;
37、步骤19.按照数据标准化方法,将所述训练样本中的rank1、rank2、rank3和对应的sample_ranki进行归一化,转换成符合基于lstm的录取成功率预测模型输入要求的形式,即得到预处理后的各高校中的各专业往年的历史录取数据,其中,数据标准化方法计算公式如下: 计算rank1、rank2、rank3和sample_ranki的平均值mean;
38、mean = (rank1 + rank2 + rank3 + sample_ranki) ÷ 4;
39、计算rank1、rank2、rank3和sample_ranki的标准差std;
40、std=
41、
42、利用平均值与标准差对rank1、rank2、rank3、sample_ranki进行标准化;
43、x1 = (rank1 - mean) ÷ std;
44、x2 = (rank2 - mean) ÷ std;
45、x3 = (rank3 - mean) ÷ std;
46、xs = (sample_ranki - mean) ÷ std;其中,x1、x2和x3表示过去第一年、第二年和第三年的录取位次标准化后的结果,xs表示录取位次标准化后的结果。
47、进一步,所述步骤2中基于lstm的录取成功率预测模型的结构包括两个输入端,分别为第一输入端和第二输入端,接收第一输入端输入的数据的单向lstm网络,接收第二输入端输入的数据的全连接网络,以及将lstm网络和全连接网络输出的特征向量进行距离特征计算的融合层,将融合层得到的距离特征向量进行得分计算的输出层,其中,输出层一个全连接网络,全连接网络的激活函数为sigmoid函数。
48、进一步,所述步骤2中训练基于lstm的录取成功率预测模型的具体步骤为:
49、步骤21.将所述浮动样本集合中的每一条样本得到的x1、x2和x3输入训练好的录取成功率预测模型的第一个输入端,将xs输入训练好的录取成功率预测模型的第二个输入端,所述浮动样本集合中的每一条样本的resign_label作为基于lstm的录取成功率预测模型输出端的结果;
50、步骤22.在第一个输入端将x1、x2、x3通过单向lstm网络进行编码,编码后把最后一个lstm单元的隐藏状态输出作为高校专业历史录取数据特征向量;
51、在第二个输入端将xs通过一个全连接网络编码成与高校专业历史录取数据特征向量具有相同维度的特征向量;
52、步骤23.从两个输入端得到的特征向量通过向量相减进行融合,得到距离特征向量;
53、步骤24.将所述距离特征向量经输出层的sigmoid函数激活得到0-1之间的得分,该得分表示当某高校某专业历史录取数据为rank1、rank2、rank3时,若某考生位次为sample_rank,则该考生被该高校该专业录取的成功率;
54、步骤25.判断训练轮数是否大于20,若否,判断是否已连续训练3轮,且最近连续3轮训练得到的录取成功率预测模型的准确率都未提升,则停止训练,若否,更新lstm的录取成功率预测模型后,重复步骤21-步骤25。
55、进一步,所述步骤3具体为:
56、步骤31.获取考生当年位次,定义为student_rank,取student_rank的值作为中心位次,根据某省当年的一分一段表,将student_rank映射为具体的分数student_score;
57、步骤32.取 student_score 向上 4 分, 记作score_up,取student_score向下 7分,记作score_down,并根据某省当年一分一段表,将score_up和score_down分别映射成具体的位次rank_wnd_up和rank_wnd_down,作为匹配高校专业的原子术语实体的上界和下界;
58、步骤33.获取考生意向省份和意向专业,结合步骤32中计算得到的位次匹配上界和下界,利用所述基于大数据和知识图谱的推荐方法,在所述高考志愿服务知识图谱中查询得到满足考生意向以及与考生位次相匹配的高校的专业,组成候选高校专业集合;
59、步骤34.获取所述候选高校专业集合中各高校中的各专业在y2年的录取位次rank2,y3年的录取位rank3和y年的录取位次rank_update;
60、步骤35.利用数据标准化方法对rank2、rank3、rank_updata和student_rank进行标准化,其中,数据标准化方法计算公式如下;
61、计算rank2、rank3、rank_update和student_rank的平均值mean;
62、mean = (rank2 + rank3 + rank_update + student_rank) ÷ 4;
63、计算rank2、rank3、rank_update和student_rank的标准差std;
64、std =
65、
66、对rank2、rank3、rank_update和student_rank进行数据标准化;
67、z1 = (rank1 - mean) ÷ std;
68、z2 = (rank2 - mean) ÷ std;
69、z3 = (rank3 - mean) ÷ std;
70、zs = (student_rank - mean) ÷ std;
71、其中,z1、z2、z3分别表示rank2、rank3、rank_update进行数据标准化后的结果,zs表示student_rank进行数据标准化后的结果;
72、步骤36.将z1、z2、z3输入训练好的录取成功概率预测模型的第一个输入端,将zs输入训练好的录取成功概率预测模型的第二个输入端,计算考生被所述候选高校专业集合中各高校中的各专业录取的成功率。
73、进一步,所述步骤4具体为:
74、步骤41.若成功率得分小于0.55的高校专业,其填报策略设置为“冲”;
75、步骤42. 若成功率得分在0.56-0.70之间的高校专业,其填报策略设置为“稳”;
76、步骤43. 若成功率得分大于0.71的高校专业,其填报策略设置为“保”。
77、一种基于高考志愿服务知识图谱的高考志愿推荐方法,包括:
78、知识推理引擎模块基于大数据和知识图谱的推荐方法获取候选高校专业集合;
79、录取成功率计算模块基于训练好的录取成功概率预测模型,预测候选高校专业集合中的各高校中的各专业录取的成功率;
80、院校专业分类推荐模块基于录取成功率计算模块预测的成功率,划分为“冲”、“稳”、“保”三类,推荐给考生。
81、一种基于高考志愿服务知识图谱的高考志愿推荐系统,包括:
82、知识推理引擎模块:用于基于大数据和知识图谱的推荐方法获取候选高校专业集合;
83、录取成功率计算模块:基于训练好的录取成功概率预测模型,预测候选高校专业集合中的每一个高校中的专业录取的成功率;
84、院校专业分类推荐模块:用于基于录取成功率计算模块预测的成功率,划分为“冲”、“稳”、“保”三类,推荐给考生。
85、本发明同现有技术相比,其有益效果表现在:
86、一、本发明通过设计高考志愿服务知识图谱,建立省份、高校、学科、学类、专业之间的关联,形成一个更加强大的高考志愿服务领域知识库,可以支撑多种高考志愿服务应用,比如高校信息检索,专业信息检索,相关专业检索,志愿推荐服务中的复杂推理等。
87、二、本发明在进行高考志愿推荐服务时,获取考生的省份意向,专业意向,考生当年位次,利用知识推理方法构建复杂条件查询图,从高考志愿服务知识图谱中检索满足考生意向并且与考生位次匹配的各高校各专业及其相关专业,有利于帮助考生快速设计出志愿填报方案,减轻人工筛选的压力,由于在筛选高校和专业时充分考虑了考生本人的意向,筛选得到了更多的与考生意向专业相关的专业,考生将有拥有更多机会进入自己意向的专业领域学习。
88、三、本发明中的lstm 的录取成功率预测模型中的lstm网络不仅能处理具有时序特征的数据,而且lstm网络的最后一个lstm单元的隐藏状态融合了全部历史数据的特征,并且较近的年份的比重会比较大,较远的年份比重会比较小,符合人工分析数据的思维,且历史数据时序特征的融合是由lstm内部的计算机制自行完成的,不需要人工设计加权的规则,实施起来比较灵活,解决了人为分析工作量很大的问题,通过利用基于 lstm 的录取成功率预测模型自动捕获历史数据的变化趋势,与考生当年位次比对,计算考生被各高校各专业录取的成功率,能让考生对自己是否能否被某高校的某专业有一个合理的认知,解决了在高考志愿填报过程中高校专业数量大,历史数据变化趋势复杂以至于人工分析数据压力大的问题,根据录取成功率将高校专业划分为“冲”、“稳”、“保”三档供考生参考,有利于考生科学合理的制定高考志愿填报方案。
- 还没有人留言评论。精彩留言会获得点赞!