一种基于深度强化学习的多智能体协同导航方法
本发明属于多智能体协同导航,具体涉及一种基于深度强化学习的多智能体协同导航方法。
背景技术:
1、多智能体协同导航是多智能体系统完成协同任务的重要基础,在近些年受到了广泛的关注。它要求智能体具有在复杂环境中互相协调执行任务的能力,并且在任务过程中避免碰撞以保证自身的安全。相比于单智能体,实现协同导航的多智能体系统能更高效地完成任务,提高系统的容错能力和对环境的适应能力。多智能体协同导航具有广泛的应用场景,一些应用包括多机器人编队控制、多机器人目标搜索和自主移动服务机器人等。深度强化学习算法继承了深度学习算法在感知和特征提取方面的优越性,通过将智能体的状态信息映射到特征空间来实现端到端的学习,而无需人工设计特征。至于训练所需要的大量数据则是通过与模拟环境的交互以低廉的成本生成,如此轻松解决了样本问题。这些特点使得深度强化学习成为了多智能体和人工智能领域最火热的研究和应用方向之一。
2、现有的专利技术,比如“一种基于深度强化学习的多智能体导航算法”,授权公布号为“cn113218400b”。该方法将a*算法融合到ppo算法中,前者是一种路径规划方法,后者是一种深度强化学习方法。该方法利用设计的奖惩函数实现两种算法的深度融合,智能体通过输入传感器原始图像数据,决策规划出最佳行动路径,到达目标点。由于该方法需要将扫描仪得到的图像信息进行特征提取,通过卷积神经网络训练得到低维环境特征,而图像处理的过程比较耗时,也对设备的性能提出了比较高的要求,训练过程相对较长。
3、分层稳定多智能体深度强化学习算法可以很好地学习多智能体协同导航的端到端解决方案。该算法直接将原始传感器数据映射到控制信号,而不是使用基于规划的方法。具体地,该算法的训练阶段是在随机环境中进行的,智能体在此期间可以学习合作策略。一旦学习到策略,就将策略部署到每个智能体上,以便在未知环境中完成协同导航,而不需要进行耗时的规划和关于目标选择信息的交换操作。但是该算法模型存在容易陷入过拟合、策略的全局最优性不足、训练过程中对样本的利用率不高等问题,因此需要对算法模型网络进行改进,以提高模型泛化能力,提升协同导航性能。
技术实现思路
1、为了克服以上现有技术存在的问题,本发明的目的在于提供一种基于深度强化学习的多智能体协同导航方法,在碰撞避免策略网络中使用自注意力机制来处理其他智能体的状态序列信息,使得智能体有选择性地筛选出重要的环境信息,从而达到优化策略的目的,并在其训练过程中加入r-drop机制,通过对隐藏层节点进行随机删除操作以及改进损失函数来改善模型的过拟合问题,同时使用优先经验回放机制,给予重要性更大的样本更大的采样率,来提升样本的利用率。由此,该方法提高了模型的泛化能力,从而提升了协同导航性能。
2、为了实现上述目的,本发明采用的技术方案是:
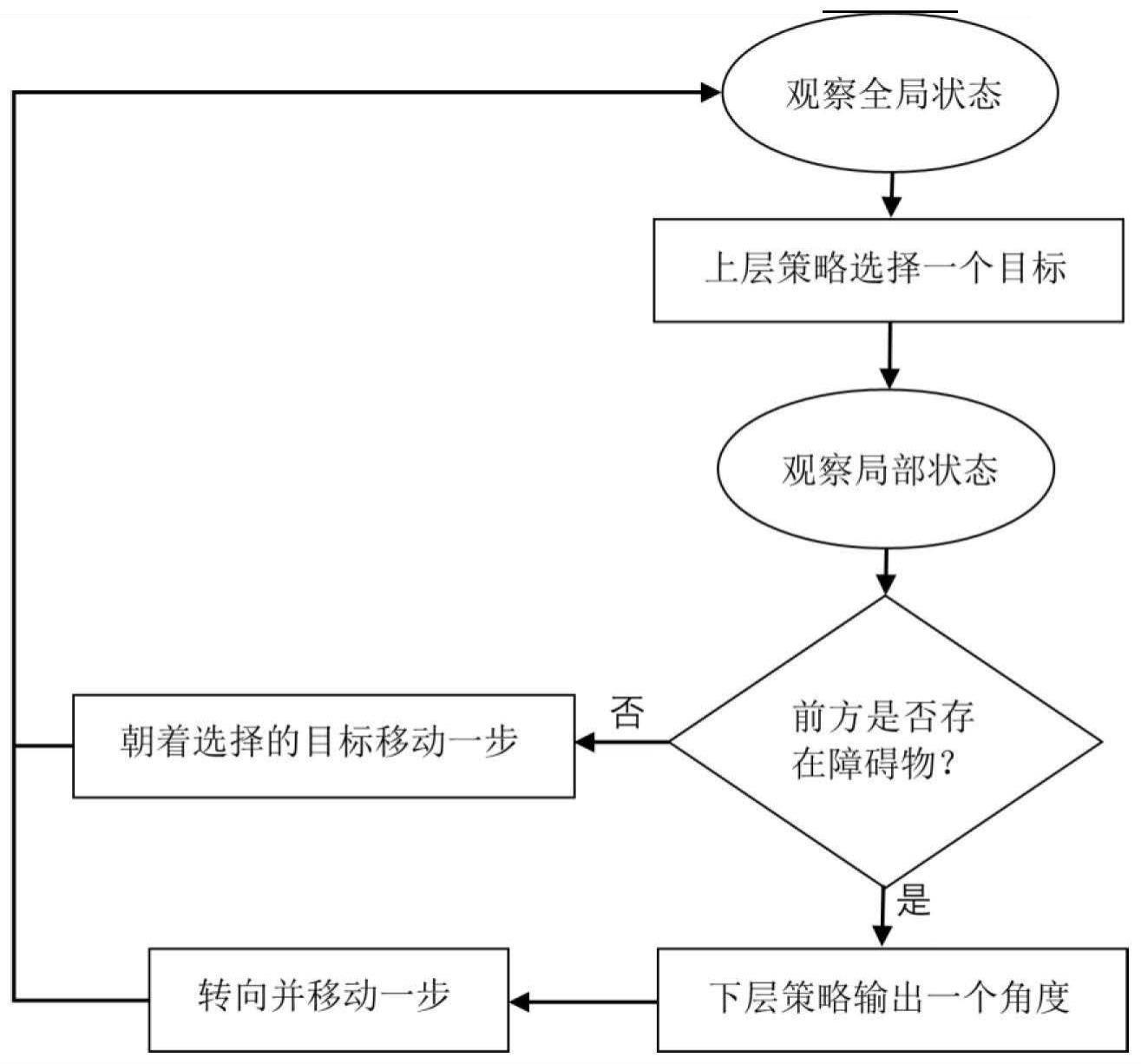
3、一种基于深度强化学习的多智能体协同导航方法,以一个运动设备为一个智能体或被一个智能体控制,各智能体执行以下步骤;
4、步骤1,观察全局状态,所述全局状态指当前运动设备探测到的所有目标以及其他智能体的相对位置坐标;构建目标选择策略网络和碰撞避免策略网络;
5、步骤2,根据所述目标选择策略网络,选择一个目标,所述目标指当前运动设备需要导航到的目标地点;
6、步骤3,观察局部状态,所述局部状态指当前运动设备探测到的与周围障碍物之间的距离;
7、步骤4,判断前方是否存在障碍物,若否,则当前运动设备向选择的所述目标移动一步,并返回步骤1;若是,则根据所述碰撞避免策略网络得到一个角度,当前运动设备转向该角度并向前移动一步,并返回步骤1;所述向前,指当前运动设备转向的角度方向;
8、所述目标选择策略网络,该神经网络有一个输入层,两个隐藏层和一个输出层;该网络是在无障碍物的环境中进行训练的:将每回合观测到的状态信息存入经验回放机制模块的经验回放池中,并从经验回放池中抽取样本输入到目标选择策略网络中,然后将网络的预测值与真实值输入到损失函数中,求取损失值,其表达式为并根据随机梯度下降法对神经网络参数进行更新,其中,表示求期望,i表示第i个智能体,t表示第t个时间步,表示实际的奖励值,gts表示对应的目标选择策略网络输出的动作价值函数值。
9、所述步骤1中碰撞避免策略网络具体包括:
10、(1)对碰撞避免策略网络进行训练与测试,评估模型的性能指标;所述碰撞避免策略网络用于进行碰撞避免;
11、(2)在碰撞避免策略网络中添加r-drop机制模块;当在智能体感知范围内的方向上观察到障碍物时,由该网络输出一个转向角度来指导智能体进行避障;
12、所述r-drop是一种正则化方法,它是dropout方法的一种变体,用于缓解模型的过拟合问题,提高模型的泛化能力;
13、(3)在步骤(2)的基础上,在碰撞避免策略网络中添加自注意力机制模块,所述自注意力机制模块通过预处理其他智能体的状态序列信息,用于实现对不同重要程度环境信息的筛选,从而提高模型的协同导航能力;
14、(4)在步骤(3)的基础上,将碰撞避免策略网络训练过程中用到的经验回放机制模块替换为优先经验回放机制模块,所述优先经验回放机制模块在网络模型的训练过程中基于样本的优先度来进行样本抽取,优先度代表着样本的重要性大小,优先度越大的样本对应采样率也越大,对样本的利用率更高,并提高了模型学到好策略的概率,得到改进的网络模型;
15、(5)对改进的网络模型进行导航的训练与测试,评估模型的性能指标。
16、(6)在训练与测试后的改进的网络模型进行导航。
17、所述步骤(1)和(5)中,对网络模型和改进算法网络模型进行训练与测试的过程,包括下列步骤:
18、(1)在无障碍环境中训练算法网络模型的目标选择策略;将每回合观测到的状态信息存入经验回放机制模块的经验回放池中,并从经验回放池中抽取样本输入到目标选择策略网络中,然后将网络的预测值与真实值输入到损失函数中,求取损失值,其表达式为并根据随机梯度下降法对神经网络参数进行更新,其中,表示求期望,i表示第i个智能体,t表示第t个时间步,表示实际的奖励值,gts表示对应的目标选择策略网络输出的动作价值函数值;
19、(2)重复步骤(1)直到episode达到10000轮后结束,此时目标选择策略网络已经收敛;
20、(3)以训练好的目标选择策略为热启动,在障碍物未知且随机设置的环境中训练碰撞避免策略;将每回合观测到的状态信息存入经验回放池中,并从经验回放池中抽取样本输入到碰撞避免策略网络中,然后将网络的预测值与真实值输入到损失函数中,求取损失值,并根据随机梯度下降法对神经网络参数进行更新;
21、(4)重复步骤(3)直到episode达到10000轮后结束,此时碰撞避免策略网络已经收敛;
22、(5)在障碍物未知且随机设置的环境中测试算法模型的性能,生成1000个测试任务,以成功率和归一化平均最大导航时间作为性能指标进行评估。
23、所述步骤(2)中,在每个训练步中,给定输入数据对(xi,yi),将xi输入到网络的前向通道中两次,由此得到模型预测的两个分布,分别记为p1和p2;两个前向传递确实基于的是两个不同的子模型,样本xi两次通过带有dropout的模型时随机删除的神经元不同,因此对于同一输入数据对(xi,yi),模型预测的两个分布p1和p2是不同的;
24、然后,在训练过程中,r-drop机制模块通过最小化同一样本的这两个输出分布之间的双向kl散度来正则化模型预测,从而缩小训练与测试模型之间的差异,双向kl散度通常取两个分布的两个kl散度的加和的一半,其表达式为其中dkl表示求两个输出分布之间的kl散度;
25、加入r-drop机制模块,网络的损失函数变为
26、
27、其中,和分别为样本两次前向传递在算法碰撞避免策略网络的损失,和分别为样本两次前向传递在算法碰撞避免策略网络输出值,dkl表示求两个输出分布之间的kl散度,α是对该散度进行控制的权重系数。
28、所述步骤(3)具体为:
29、利用自注意力机制预处理其他智能体的观测序列信息,使得智能体能够有选择性地筛选出重要的环境信息,而忽略掉不重要的信息;
30、样本在算法碰撞避免策略网络中进行前向传递的损失为
31、
32、其中,表示求期望,i表示第i个智能体,t表示第t个时间步,表示实际的奖励值,gca表示对应的碰撞避免策略网络输出的动作价值函数值,表示观测值,表示来自其他智能体的环境信息,该值由自注意力机制模块输出所得,表示对应的碰撞避免策略网络输出的动作值。
33、所述步骤(4)的优先经验回放模块是特殊的二叉树,其中每个节点的值都是其子节点值之和,并且以样本的优先度作为叶子节点,观测到的状态信息就是样本数据,在将样本存入经验回放池之前,需要计算每个样本的优先度,这样二叉树叶子节点的优先度与样本数据之间就能建立起对应关系,样本经验池中所有样本的优先度之和即为根节点的优先度。
34、所述步骤(6)中,在协同导航过程中,每个智能体以恒定速度v=1米每时间步移动,并具有在[-(π/2),(π/2)]范围内变化的转向角度,如果所有智能体分别到达不同目标即为导航成功,若发生碰撞则导航失败,两种情况都使得本回合结束,在每个时间步中,每个智能体首先根据其对全局状态的观测选择一个目标,然后将其视野中心旋转到所选目标并观察局部状态,如果在感知范围内的方向上没有观察到障碍物,智能体会直接向目标移动,否则,激活下层策略输出一个角度,智能体将转向该角度并向前移动。所述步骤(1)是对原算法网络模型进行训练与测试,步骤(5)是对改进后网络模型进行训练与测试,需要对结果进行对比。
35、本发明的有益效果:
36、该方法在碰撞避免策略网络中加入r-drop机制模块,来缓解网络学习的过拟合现象。使用自注意力机制模块预处理输入到碰撞避免策略网络中的关于其他智能体的状态信息序列,增强智能体筛选重要环境信息的能力。使用优先经验回放方法进行训练过程中样本的存储与抽取,提高对样本的利用率,增加学到好策略的概率。
37、本发明解决了以下技术问题:一是原有深度强化学习算法模型在训练过程中容易陷入过拟合的问题;二是没有考虑其他智能体状态对当前智能体影响程度的差异,使得策略的全局最优性不足的问题;三是在网络训练过程中对样本的利用率不高的问题。
- 还没有人留言评论。精彩留言会获得点赞!