一种Kafka消息消费处理方法、装置、设备及存储介质与流程
本发明涉及大数据实时处理,特别涉及一种kafka消息消费处理方法、装置、设备及存储介质。
背景技术:
1、当前,kafka作为较为流行的消息队列方案之一,在业界使用较多,多用于一些日志类数据传输通道,这类业务对数据可靠性要求并不是很高,但将其作为业务功能的异步化处理方案时,kafka的缺点就很明显了,具体的缺点如下:第一、kafka消费数据后是通过提交位移点来控制消费位置,没有重试的功能,这在业务使用场景中弊端较多,实际上,业务往往需要失败后定期重试或更复杂的重试策略;第二、kafka往往每个消费业务端都需要新起一个分组,业务上往往同一个topic有大量的下游需要选择性消费,比如下单消息,这时候创建同等比例的分组但实际消费的有效消息却是其中被选择的一部分,导致资源浪费;第三、kafka的同一个topic下消费线程数等同于分区数,这限制了消费端的消费能力,而增加分区数就会增加资源开销。
2、鉴于此,提供一种解决上述技术问题的方案,已经是本领域技术人员所亟需关注的。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种kafka消息消费处理方法、装置、设备及存储介质,能够实现高可靠的消费方案,提供了同一个消费组下多消费路由功能,从而提升消费并发性能。其具体方案如下:
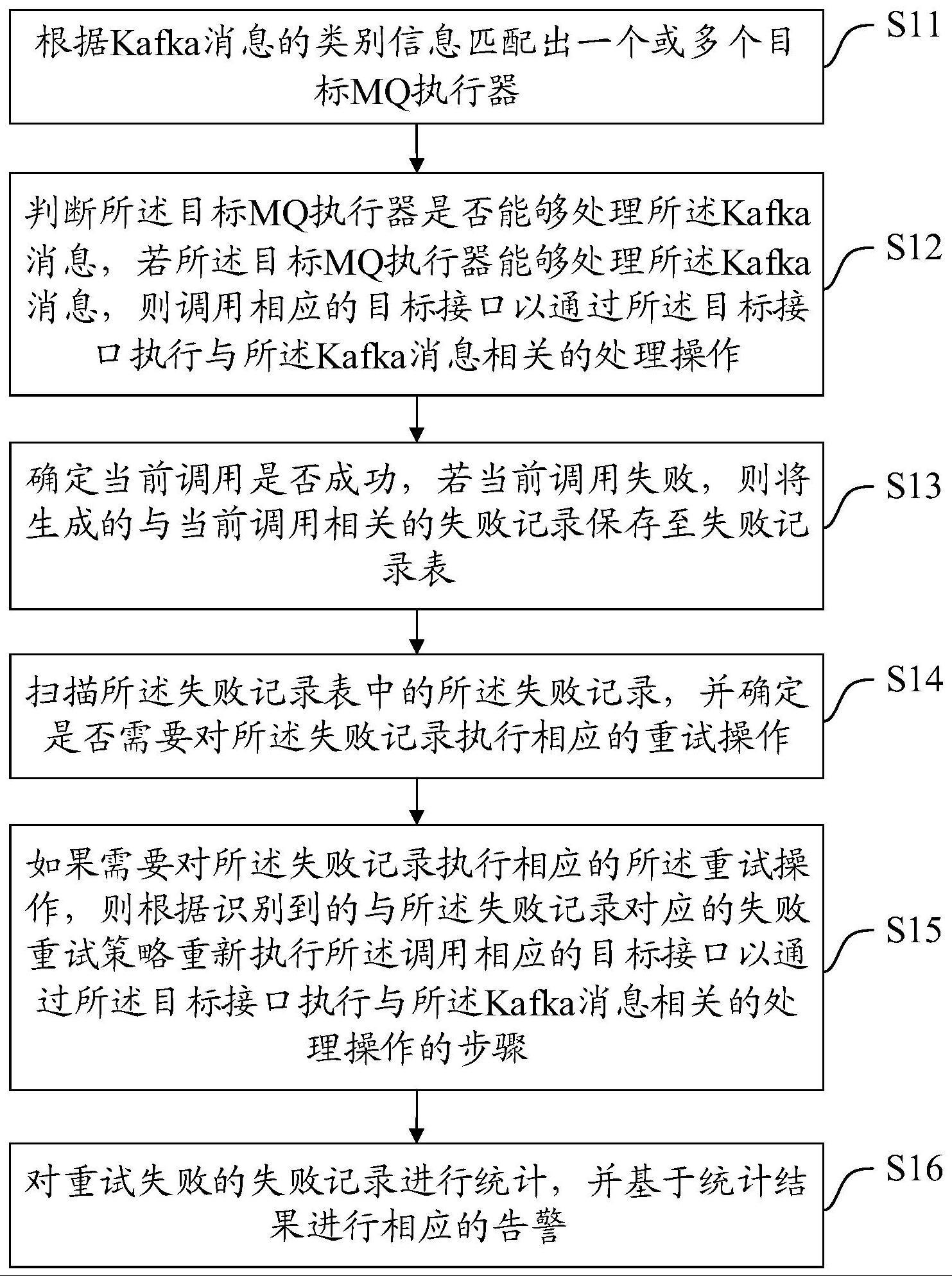
2、第一方面,本技术公开了一种kafka消息消费处理方法,包括:
3、根据kafka消息的类别信息匹配出一个或多个目标mq执行器;
4、判断所述目标mq执行器是否能够处理所述kafka消息,若所述目标mq执行器能够处理所述kafka消息,则调用相应的目标接口以通过所述目标接口执行与所述kafka消息相关的处理操作;
5、确定当前调用是否成功,若当前调用失败,则将生成的与当前调用相关的失败记录保存至失败记录表;
6、扫描所述失败记录表中的所述失败记录,并确定是否需要对所述失败记录执行相应的重试操作;
7、如果需要对所述失败记录执行相应的所述重试操作,则根据识别到的与所述失败记录对应的失败重试策略重新执行所述调用相应的目标接口以通过所述目标接口执行与所述kafka消息相关的处理操作的步骤;
8、对重试失败的失败记录进行统计,并基于统计结果进行相应的告警。
9、可选的,所述根据kafka消息的类别信息匹配出一个或多个目标mq执行器之前,还包括:
10、监测数据库中的mq执行器的配置变更得到相应的变更信息;
11、基于所述变更信息执行相应的变更操作。
12、可选的,所述基于所述变更信息执行相应的变更操作,包括:
13、如果所述变更信息表明所述数据库中增加新的mq执行器,则注册相应的kafka消费者至kafka集群;
14、如果所述变更信息表明所述数据库中的所述mq执行器的配置变更,则依据所述变更信息更新所述数据库中的所述mq执行器的配置。
15、可选的,所述确定当前调用是否成功,包括:
16、根据所述目标接口返回的调用信息和所述目标mq执行器的成功表达式确定当前调用是否成功。
17、可选的,所述判断所述目标mq执行器是否能够处理所述kafka消息,包括:
18、根据所述kafka消息的具体内容执行所述目标mq执行器的触发表达式以判断所述目标mq执行器是否能够处理所述kafka消息。
19、可选的,所述调用相应的目标接口以通过所述目标接口执行与所述kafka消息相关的处理操作,包括:
20、根据构造的请求头和请求参数体进行目标接口的调用以通过所述目标接口执行与所述kafka消息相关的处理操作。
21、可选的,所述确定是否需要对所述失败记录执行相应的重试操作之后,还包括:
22、如果不需要对所述失败记录执行相应的所述重试操作或对所述失败记录重试成功时,则将所述失败记录的状态更新为已过期状态。
23、第二方面,本技术公开了一种kafka消息消费处理装置,包括:
24、执行器匹配模块,用于根据kafka消息的类别信息匹配出一个或多个目标mq执行器;
25、执行器判断模块,用于判断所述目标mq执行器是否能够处理所述kafka消息;
26、接口调用模块,用于若所述目标mq执行器能够处理所述kafka消息,则调用相应的目标接口以通过所述目标接口执行与所述kafka消息相关的处理操作;
27、调用判断模块,用于确定当前调用是否成功,若当前调用失败,则将生成的与当前调用相关的失败记录保存至失败记录表;
28、重试判断模块,用于扫描所述失败记录表中的所述失败记录,并确定是否需要对所述失败记录执行相应的重试操作;
29、重试模块,用于如果需要对所述失败记录执行相应的所述重试操作,则根据识别到的与所述失败记录对应的失败重试策略重新执行所述调用相应的目标接口以通过所述目标接口执行与所述kafka消息相关的处理操作的步骤;
30、告警模块,用于对重试失败的失败记录进行统计,并基于统计结果进行相应的告警。
31、第三方面,本技术公开了一种电子设备,包括:
32、存储器,用于保存大数据实时处理程序;
33、处理器,用于执行所述大数据实时处理程序,以实现前述公开的kafka消息消费处理方法的步骤。
34、第四方面,本技术公开了一种大数据实时处理可读存储介质,用于存储大数据实时处理程序;其中,所述大数据实时处理程序被处理器执行时实现前述公开的kafka消息消费处理方法的步骤。
35、可见,本技术提供了一种kafka消息消费处理方法,包括:根据kafka消息的类别信息匹配出一个或多个目标mq执行器;判断所述目标mq执行器是否能够处理所述kafka消息,若所述目标mq执行器能够处理所述kafka消息,则调用相应的目标接口以通过所述目标接口执行与所述kafka消息相关的处理操作;确定当前调用是否成功,若当前调用失败,则将生成的与当前调用相关的失败记录保存至失败记录表;扫描所述失败记录表中的所述失败记录,并确定是否需要对所述失败记录执行相应的重试操作;如果需要对所述失败记录执行相应的所述重试操作,则根据识别到的与所述失败记录对应的失败重试策略重新执行所述调用相应的目标接口以通过所述目标接口执行与所述kafka消息相关的处理操作的步骤。对重试失败的失败记录进行统计,并基于统计结果进行相应的告警。由此可见,本技术在每一条kafka消息消费处理的过程中,根据kafka消息的类别信息匹配出一个或多个目标mq执行器,即配置了多个执行器绑定同一个消费组实现并发消费,在目标mq执行器能够处理所述kafka消息时,调用相应的目标接口以通过目标接口执行与kafka消息相关的处理操作,也就是说,通过匹配到的目标mq执行器进行各种对应的后置操作,实现一条消息可触发多个后置操作,然后确定调用是否成功,若失败,则对生成的失败记录进行有策略的重试,最后基于失败记录重试失败的统计结果进行告警,从而提高消费处理的可靠性,也即本技术的上述技术方案为能够实现高可靠的消费方案,提供了同一个消费组下多消费路由的功能,从而提升消费并发的性能。
- 还没有人留言评论。精彩留言会获得点赞!